

Reactor operators
Reactor는 Reactive Streams 사양을 구현한 라이브러리 중 하나이며, 일반적으로 Project Reactor를 의미하는 용어로 사용됩니다. Reactor는 비동기 데이터 흐름을 Mono, Flux 스트림 형태로 다루며, 이를 변환하고 조합하기 위한 다양한 operator(연산자) 를 제공합니다. 이번 글에서는 그 operator(연산자)들에 대해 보다 자세히 살펴보겠습니다.
리액티브 스트림즈에 관한 자세한 내용은 Reacative Programing에서 다뤘습니다.
Subscribe
Reactor에서 Publisher(Flux/Mono)는 음료가 담긴 컵과 같습니다. 컵 안에는 음료가 준비되어 있어도 빨대를 꽂지 않으면(= subscribe()) 음료는 입으로 들어오지 않습니다.
Reactor 스트림도 마찬가지입니다. Flux, Mono 를 선언하고 operator를 체인으로 연결했다고 해서 바로 실행되는 것이 아닌, subscribe가 호출되는 순간 비로소 데이터가 흐르기 시작합니다.
subscribe()는 여러 형태로 오버로딩되어 있으며, 전달하는 파라미터에 따라 동작 방식이 달라집니다.
1. Consumer를 넘기지 않는 subscribe()
public final Disposable subscribe()가장 단순한 형태의 subscribe()는 아무 인자도 받지 않고, 별도의 소비 로직 없이 스트림을 끝까지 실행합니다.
Publisher는 내부적으로 Long.MAX_VALUE 만큼 요청을 보내고 데이터를 그대로 흘려보내지만, 사용자가 onNext·onError·onComplete 신호를 처리하지 않기 때문에 특별한 동작을 확인하기는 어렵습니다.
2. Consumer 기반 subscribe
public final Disposable subscribe(
@Nullable Consumer<? super T> consumer,
@Nullable Consumer<? super Throwable> errorConsumer,
@Nullable Runnable completeConsumer,
@Nullable Context initialContext
)각 인자는 모두 null 가능하기 때문에 다음과 같이 여러 형태로 사용될 수 있습니다.
subscribe(onNext)
subscribe(onNext, onError)
subscribe(onNext, onError, onComplete)
subscribe(onNext, onError, onComplete, context)이 방식의 subscribe는 데이터가 방출될 때(onNext) 어떻게 처리할지, 오류가 발생했을 때(onError) 어떻게 대응할지,
정상적으로 종료될 때(onComplete) 어떤 동작을 수행할지를 명확하게 정의할 수 있습니다.
또한 이 형태는 Disposable을 반환하기 때문에, 필요하다면 dispose()를 호출하여 언제든지 구독을 종료할 수 있습니다.
Disposable d = Flux.range(1, 5)
.subscribe(
v -> System.out.println("next: " + v),
err -> System.err.println("error: " + err),
() -> System.out.println("complete"),
Context.empty()
);
d.dispose(); // 구독 종료
다만 Consumer 기반 subscribe는 Subscription 객체를 전달받지 않기 때문에 request(n) 호출을 통한 요청량 제어나 cancel() 호출은 불가능합니다.
여기서 마지막 파라미터인 initialContext는 Reactor의 Context를 초기값과 함께 지정할 수 있는 기능입니다. Context는 스레드 로컬(ThreadLocal)과 비슷하게 데이터를 흐름에 실어 전달하는 역할을 하며, 인증 정보·트랜잭션 식별자·요청 단위 값 등을 downstream에서 참조해야 할 때 사용됩니다. Context는 뒤에서 자세히 다루도록 하겠습니다.
3. Subscriber 기반 subscribe
public final void subscribe(Subscriber<? super T> actual)Subscriber를 직접 구현하여 전달하는 방식은 Reactive Streams 표준에 가장 근접한 사용 형태로, 이 방식의 가장 큰 특징은 onSubscribe(Subscription s)에서 Subscription 정보를 받는다는 점입니다. Subscription 객체는 request(n)과 cancel()을 호출할 수 있는 권한을 가지며, 이를 통해 구독자가 스트림의 Backpressure를 직접 제어할 수 있습니다.
여기서 중요한 것은 onSubscribe() 메서드가 개발자가 명시적으로 호출하는 것이 아니라, Publisher에 subscribe()가 실행되는 순간 내부적으로 자동 호출된다는 점입니다. 즉, 구독이 시작되면 Publisher는 Subscriber에게 Subscription을 전달하며 가장 먼저 onSubscribe()를 호출하고, 이후 구독자가 request(n)을 통해 데이터를 요청해야 비로소 onNext() 이벤트가 흘러가기 시작합니다.
Flux.range(1, 100)
.subscribe(new Subscriber<Integer>() {
@Override
public void onSubscribe(Subscription s) {
s.request(10);
}
@Override
public void onNext(Integer value) {
System.out.println("next: " + value);
}
@Override
public void onError(Throwable t) {}
@Override
public void onComplete() {}
});위와 같이 Subscriber를 직접 구현하는 방식은 제어 능력이 뛰어나지만, 매번 onNext, onError, onComplete, onSubscribe를 모두 구현해야 하기 때문에 작성량이 많습니다.
Reactor는 이러한 번거로움을 줄이기 위해 BaseSubscriber<T> 라는 추상 클래스를 제공합니다. 직접 Subscriber 인터페이스를 구현하면 onSubscribe, onNext, onError, onComplete를 모두 작성해야 하지만, BaseSubscriber는 필요한 부분만 골라 override할 수 있도록 일종의 Subscriber용 어댑터(Adaptor) 클래스 역할을 합니다.
사실 앞에서 살펴본 Consumer 기반 subscribe도 내부적으로는 Subscriber를 직접 생성하여 사용합니다.
아래 코드를 보면, Consumer subscribe 호출 시 Reactor가 LambdaSubscriber를 만들어 subscribeWith()로 넘기는 구조를 확인할 수 있습니다.
public final Disposable subscribe(@Nullable Consumer<? super T> consumer, @Nullable Consumer<? super Throwable> errorConsumer, @Nullable Runnable completeConsumer, @Nullable Context initialContext) {
return (Disposable)this.subscribeWith(new LambdaSubscriber(consumer, errorConsumer, completeConsumer, (Consumer)null, initialContext));
}
그리고 LambdaSubscriber 내부 구현을 보면, onSubscribe() 단계에서 s.request(Long.MAX_VALUE)가 호출되는 것을 확인할 수 있습니다.
final class LambdaSubscriber<T> implements InnerConsumer<T>, Disposable {
public final void onSubscribe(Subscription s) {
...
s.request(Long.MAX_VALUE);
}
...
}
즉, Consumer 기반 subscribe는 사용자가 request(n)를 직접 지정하지 않기 때문에, Reactor는 기본적으로 Long.MAX_VALUE 만큼 요청하여 Publisher가 보낼 수 있는 데이터를 제한 없이 최대치로 요청(unbounded request) 합니다. 이 때문에 별도의 Backpressure 제어 없이도 Flux/Mono의 값이 끝까지 자연스럽게 흐르게 되는 것입니다.
이런 동작 방식은 간단하게 스트림을 소비할 때는 편리하지만, 처리 속도가 느린 소비자 환경에는 부담이 될 수 있습니다. 따라서 필요한 경우에는 Subscriber 또는 BaseSubscriber를 통해 request(n)을 명시적으로 호출하며 흐름을 제어하는 방식이 더 적합합니다.
시퀀스 생성
Reactive 프로그래밍에서 스트림(Stream) 은 실제 데이터가 onNext 신호와 함께 발행되는 흐름을 의미합니다.
반면 데이터가 실제로 생성되거나 흘러가지 않고, 발행될 수 있는 잠재적 흐름만 정의된 상태라면 이를 시퀀스(Sequence) 로 이해할 수 있습니다.
어떤 방식으로 시퀀스를 만들고, 어떤 형태로 흐름을 시작할 수 있는지 대표 생성 Operator들을 간단한 예제와 함께 살펴보겠습니다.
1. just()
just()는 값을 즉시 발행하는 가장 단순한 생성 방식입니다. 구독하면 onNext가 바로 발생하고, 이어서 onComplete가 호출되기 때문에, 간단한 테스트나 빠른 값 발행에 자주 사용됩니다.
Mono.just("Hello").subscribe(System.out::println);
Flux.just("A", "B", "C").subscribe(System.out::println);
2. error()
error()는 데이터를 발행하지 않고 onError만 발생시키는 스트림을 생성합니다. 오류 흐름을 테스트하거나 예외 처리 플로우를 검증할 때 사용합니다.
Mono.error(new RuntimeException("Mono error"))
.subscribe(null, System.out::println);
Flux.error(new RuntimeException("Flux error"))
.subscribe(null, System.out::println);
3. empty()
empty()는 값을 발행하지 않고 onComplete만 호출합니다. 값은 없지만 스트림 자체는 정상적으로 종료되는 상황을 표현할 때 적합합니다.
Mono.empty().subscribe(
System.out::println,
null,
() -> System.out.println("Mono Completed")
);
Flux.empty().subscribe(
System.out::println,
null,
() -> System.out.println("Flux Completed")
);
4. Mono.fromXxx()
fromSupplier(), fromCallable(), fromFuture(), fromRunnable() 등 1개의 값을 스트림으로 만들 때 사용합니다.
Mono.fromSupplier(() -> "value")
.subscribe(System.out::println);
5. Flux.fromXxx()
fromIterable(), fromStream(), fromArray(), fromPublisher() 등 기존 데이터를 기반으로 스트림을 만들 때 사용합니다.
Flux.fromIterable(List.of(1,2,3))
.subscribe(System.out::println);
6. Flux.range()
range()는 지정한 범위의 정수 값을 순차적으로 생성하는 연산자입니다. 카운터, 페이징, 반복 처리 등에서 간결하게 활용할 수 있습니다.
Flux.range(1, 5)
.subscribe(System.out::println);
7. Flux.generate()
generate()는 상태 기반으로 값을 1개씩 동기적으로 생성합니다. 무한 생성이 가능하므로 take() 등과 함께 제한하여 사용합니다.
public static <T, S> Flux<T> generate(
Callable<S> stateSupplier,
BiFunction<S, SynchronousSink<T>, S> generator
)첫 번째 인자로 초기값을 제공하는 Supplier를 받고, 두 번째 인자로 실제 값을 생성하는 로직을 담당하는 generate 함수를 받습니다.
generator는 다음과 같은 두 개의 인자를 받습니다.
- state – 현재 상태를 의미하며, 반환된 값이 다음 iteration의 state가 됩니다.
- SynchronousSink<T> – 명시적으로 next(), error(), complete()를 호출할 수 있는 sink입니다.
generate는 "한 호출 → 한 emit"의 pull 기반 생성 방식이기 때문에, 하나의 generator 호출에서 sink.next()는 최대 1회만 호출 가능합니다. (여러 emit이 필요한 경우 create()가 적합합니다.)
Flux.generate(
() -> 1,
(state, sink) -> {
sink.next(state);
return state + 1;
}
)
.take(3)
.subscribe(System.out::println);
8. Flux.create()
create()는 비동기적으로 Flux를 생성할 수 있는 연산자로, FluxSink를 사용하여 데이터를 직접 푸시(Push) 방식으로 emit합니다.
public static <T> Flux<T> create(Consumer<? super FluxSink<T>> emitter)FluxSink는 next(), error(), complete()를 명시적으로 여러 번 호출하는 것이 가능하기 때문에, 콜백 기반 이벤트 처리 또는 외부 비동기 소스를 Reactive 흐름으로 연결할 때 적합합니다.
또한 create()는 여러 스레드에서 동시에 sink.next()를 호출하는 것도 허용하며, 멀티스레드 환경에서 병렬로 데이터가 생산되는 상황을 자연스럽게 처리할 수 있습니다.
Flux<String> flux = Flux.create(sink -> {
CompletableFuture<Void> f1 = CompletableFuture.runAsync(() -> {
sink.next("task1 result");
});
CompletableFuture<Void> f2 = CompletableFuture.runAsync(() -> {
sink.next("task2 result");
});
CompletableFuture.allOf(f1, f2)
.thenRun(sink::complete);
});
flux.subscribe(System.out::println);CompletableFuture.allOf()와 함께 sink.complete()를 호출하여 두 작업이 종료된 시점을 Flux 완료 신호로 연결할 수 있습니다
9. handle()
handle()은 독립적으로 sequence를 생성하는 연산자가 아니라, 이미 존재하는 source 스트림에 연결되어 동작하는 연산자입니다.
즉, create/generate처럼 값을 직접 생산하기보다는, 중간에서 item을 가공·필터링하는 interceptor 역할에 가깝습니다.
public final <R> Mono<R> handle(BiConsumer<? super T, SynchronousSink<R>> handler)
public final <R> Flux<R> handle(BiConsumer<? super T, SynchronousSink<R>> handler)handle()의 인자인 BiConsumer는 두 가지 인자를 전달 받습니다.
첫 번째 인자는 기존 source의 item 이고, 두 번째 인자는 SynchronousSink<T>입니다. 이 sink는 generate()와 동일한 사용방법을 갖습니다.
Mono.just(10)
.handle((v, sink) -> {
if (v > 5)
sink.next("large: " + v);
})
.subscribe(System.out::println);
Flux.just(1, 2, 3, 4, 5)
.handle((v, sink) -> {
if (v % 2 == 0)
sink.next("even: " + v);
})
.subscribe(System.out::println);
쓰레드 & Scheduler
Reactor에서 아무런 설정을 하지 않으면 Publisher는 기본적으로 subscribe()를 호출한 caller 쓰레드 위에서 실행됩니다. 즉, 스트림을 선언하고 subscribe를 호출한 그 쓰레드가 그대로 연산을 수행하며, 중간에 map, filter, flatMap 등의 operator를 사용한 경우에도 동일한 쓰레드에서 연속적으로 실행됩니다. subscribe에 전달한 람다 역시 별도 Scheduler를 지정하지 않았다면 caller 쓰레드에서 바로 실행됩니다.

Reactor에서 대부분의 Scheduler는 Schedulers 팩토리 클래스를 통해 생성하거나 획득합니다.
1. Schedulers.immediate()
subscribe()를 호출한 caller 쓰레드에서 즉시 실행하며, 별도로 Scheduler를 지정하지 않은 경우와 동일하게 동작합니다.
Flux.create(sink -> {
for (int i = 1; i <= 5; i++) {
log.info("next: {}", i);
sink.next(i);
}
}).subscribeOn(Schedulers.immediate()
).subscribe(value -> log.info("value: " + value));
2. Schedulers.single()
하나의 워커 스레드를 계속 재사용하며 직렬 실행이 필요한 작업에 적합합니다. (스레드 공유)
for (int i = 0; i < 100; i++) {
final int idx = i;
Flux.create(sink -> {
log.info("next: {}", idx);
sink.next(idx);
}).subscribeOn(Schedulers.single()
).subscribe(value -> log.info("value: " + value));
}
Thread.sleep(1000);
3. Schedulers.parallel()
CPU 코어 수만큼의 워커를 사용하는 고정 크기 병렬 스레드풀, CPU-bound 연산 처리에 적합합니다.
for (int i = 0; i < 100; i++) {
final int idx = i;
Flux.create(sink -> {
log.info("next: {}", idx);
sink.next(idx);
}).subscribeOn(Schedulers.parallel()
).subscribe(value -> log.info("value: " + value));
}
Thread.sleep(1000);
4. Schedulers.boundedElastic()
boundedElastic 스케줄러는 기본적으로 CPU 코어 수 × 10개의 스레드까지 확장 가능하며,
워커 스레드는 필요할 때 생성되고 idle 상태가 60초 이상 유지되면 정리됩니다.
따라서 I/O blocking 작업에 적합하고, 과도한 스레드 생성으로 인한 리소스 낭비를 방지할 수 있습니다.
for (int i = 0; i < 100; i++) {
final int idx = i;
Flux.create(sink -> {
log.info("next: {}", idx);
sink.next(idx);
}).subscribeOn(Schedulers.boundedElastic()
).subscribe(value -> log.info("value: " + value));
}
Thread.sleep(1000);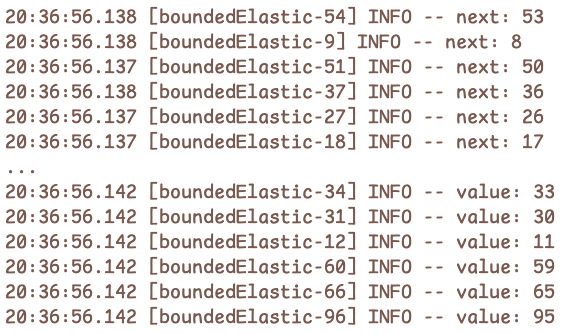
5. Schedulers.newXxx()
Schedulers.newXxx() 계열은 Reactor가 관리하는 공용 풀을 쓰지 않고 독립적인 스레드 풀을 새로 생성하므로, 사용 후에는 dispose()를 호출하여 리소스를 명시적으로 해제해야 합니다.
for (int i = 0; i < 100; i++) {
Scheduler newSingle = Schedulers.newSingle("single");
final int idx = i;
Flux.create(sink -> {
log.info("next: {}", idx);
sink.next(idx);
}).subscribeOn(newSingle
).subscribe(value -> {
log.info("value: " + value);
newSingle.dispose();
});
}
Thread.sleep(1000);
6. Schedulers.formExcutorService()
기존 ExecutorService를 Reactor Scheduler로 래핑하여 재사용할 수 있습니다.
ExecutorService executorService = Executors.newSingleThreadExecutor();
for (int i = 0; i < 100; i++) {
final int idx = i;
Flux.create(sink -> {
log.info("next: {}", idx);
sink.next(idx);
}).subscribeOn(Schedulers.fromExecutorService(executorService)
).subscribe(value -> {
log.info("value: " + value);
});
}
Thread.sleep(1000);
executorService.shutdown();
subscribeOn() vs publishOn()
subscribeOn은 체인 어디에 위치하든 상관없이 Publisher의 시작 지점(Source)부터 실행할 스레드를 지정하는 연산자입니다.
즉, Flux/Mono가 동작을 시작하는 순간의 쓰레드를 바꾸는 역할을 하며, 여러 번 사용해도 가장 먼저 적용된 것만 의미가 있습니다.
반면 publishOn은 쓰레드 변경 지점을 기준으로 이후 연산자들부터 스레드를 전환합니다.
따라서 publishOn은 체인 내에서 위치가 매우 중요합니다.
Flux.create(sink -> {
for (var i = 0; i < 5; i++) {
log.info("next: {}", i);
sink.next(i);
}
}).publishOn(Schedulers.single()
).doOnNext(item -> log.info("doOnNext: {}", item)
).publishOn(Schedulers.boundedElastic()
).doOnNext(item -> log.info("doOnNext2: {}", item)
).subscribeOn(Schedulers.parallel()
).subscribe(value -> log.info("value: " + value));
Thread.sleep(1000);
에러 핸들링
Reactor에서 onError 이벤트는 종료 신호이며, 한 번 발생하면 스트림은 더 이상 onNext나 onComplete 이벤트를 내보내지 않습니다. 에러가 발생하면 해당 이벤트는 downstream(아래 방향)으로 전파됩니다. 따라서 에러가 발생했을 때 기본 흐름이 끊기는 것이 자연스러운 동작이며, 필요하다면 개발자가 직접 에러를 가로채거나 대체하는 방식으로 흐름을 제어해야 합니다.
Reactor가 제공하는 에러 처리 방식은 크게 네 가지로 정리할 수 있습니다.
- 고정된 값을 반환(onErrorReturn)
- 대체 Publisher로 전환(onErrorResume)
- 에러를 onComplete로 전환(onErrorComplete)
- 다른 예외 타입으로 변환(onErrorMap)
0. 에러 핸들링이 없는 경우
스트림 내부에서 예외가 발생했지만 별도의 처리를 하지 않는다면 Reactor는 기본적으로 onErrorDropped 훅을 호출합니다.
기본 구현은 로그 출력 수준의 동작만 수행할 뿐, 스트림은 종료되고 downstream은 더 이상 데이터를 받을 수 없습니다.
다음은 Operators 클래스에 정의된 onErrorDropped() 메서드입니다.
public abstract class Operators {
public static void onErrorDropped(Throwable e, Context context) {
Consumer<? super Throwable> hook = (Consumer)context.getOrDefault("reactor.onErrorDropped.local", (Object)null);
if (hook == null) {
hook = Hooks.onErrorDroppedHook;
}
if (hook == null) {
log.error("Operator called default onErrorDropped", e);
} else {
hook.accept(e);
}
}
...
}메서드를 보면 별도의 훅이 없으면 기본 로그와 함께 에러를 출력하는 것을 확인할 수 있습니다.
다음 예제를 통해 에러 로그를 직접 확인해보겠습니다.
Flux.create(sink -> {
sink.next("hello");
sink.error(new RuntimeException("error"));
}).subscribe();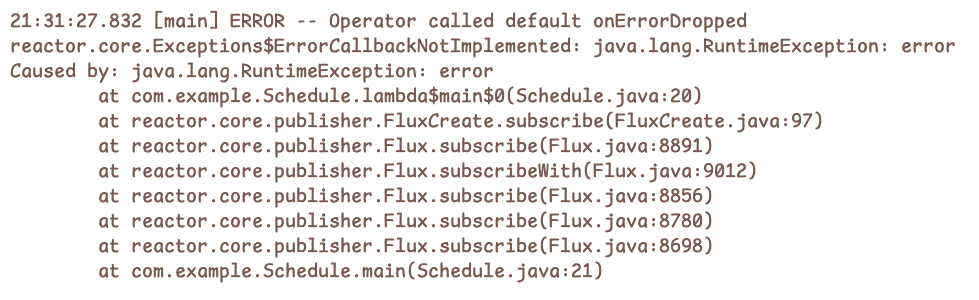
Hooks는 Reactor 전역에서 발생하는 이벤트(onError, operator 생성 등)를 가로채거나 행동을 수정하도록 등록하는 글로벌 인터셉션 포인트를 제공하는 유틸리티 클래스입니다.
Operators는 Reactor에서 연산자(Flux/Mono operator)를 구현하거나 확장할 때 사용하는 내부 유틸리티 API 클래스입니다.
1. onErrorReturn - 고정된 값을 반환
onErrorReturn은 가장 단순한 fallback 방식으로 에러 발생 시 미리 정해둔 값을 대신 흘려보내고 스트림을 정상 종료합니다. 다만 이 연산자는 에러 발생 여부와 상관없이 무조건 미리 실행되기 때문에 함수가 아닌 고정된 값을 사용해야 합니다.
onErrorReturn(T fallbackValue)Flux.error(new RuntimeException("error"))
.onErrorReturn(0)
.subscribe(value -> {
log.info("value: " + value);
});
2. onErrorResume - 대체 Publisher로 전환
onErrorResume은 에러가 발생했을 때 새로운 Publisher로 스트림을 교체할 수 있습니다. onErrorReturn과 달리 error 이벤트가 발생한 경우에만 실행됩니다.
onErrorResume(Function<Throwable, Publisher> fallback)Flux.error(new RuntimeException("error"))
.onErrorResume(e -> Flux.just(0, -1, -2))
.subscribe(value -> {
log.info("value: " + value);
});
3. onErrorComplete - 에러를 complete 신호로 변환
에러를 소비하고 스트림을 정상 종료(onComplete)로 전환합니다. 따라서 errorConsumer는 호출되지 않습니다.
onErrorComplete()Flux.error(new RuntimeException("error"))
.onErrorComplete()
.subscribe(value -> {
log.info("value: " + value);
}, e -> {
log.info("error: " + e);
}, () -> {
log.info("complete");
}
);
4. onErrorMap - 에러 변환
발생한 예외를 비즈니스 도메인에 맞는 예외로 변환하고 싶을 때 사용합니다.
onErrorMap(Function<Throwable, Throwable> mapper)Flux.error(new RuntimeException("error"))
.onErrorMap(e -> new CustomBusinessException("custom error"))
.subscribe();
5. doOnError - 에러 logging
doOnError는 스트림을 변경하지 않고 로그 출력, 모니터링, 메트릭 기록 용도로 사용되는, 흐름 제어 없이 부가 작업만 실행하는 연산자입니다.
doOnError(Consumer<Throwable> onError)Flux.error(new RuntimeException("error"))
.doOnError(e -> log.error("logging : {}", e.getMessage()))
.onErrorResume(e -> Flux.just(-1))
.subscribe();
결합
여러 Publisher를 하나로 합치거나, 시간 기반으로 이벤트 흐름을 조절하고 싶을 때 Reactor는 다양한 결합 Operators를 제공합니다. 이 연산자들은 이벤트 순서 보장 여부, 동시 처리 여부, 지연 처리 방식에 따라 구분되며, 상황에 따라 적절한 연산자를 선택하는 것이 중요합니다.
1. Flux.delayElements() - 이벤트를 일정 간격으로 지연
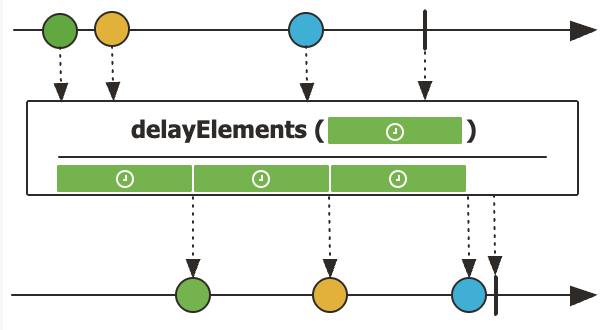
delayElements()는 onNext 이벤트가 내려갈 때 최소 delay 시간만큼 지연을 적용합니다.
이벤트 사이를 고정 간격으로 띄우고 싶을 때 사용하며, 이전 이벤트가 더 늦게 도착하더라도 최소 지연 시간 이후에는 바로 전달됩니다.
Flux.range(1, 5)
.delayElements(Duration.ofMillis(500))
.subscribe(v -> log.info("value={}", v));
2. Flux.concat() - 순서가 보장되는 직렬 연결

concat은 여러 Publisher를 앞에서 뒤로 순차적으로 연결합니다.
첫 번째 Publisher가 onComplete를 전달해야 다음 Publisher가 subscribe되고, 각 Publisher의 이벤트는 절대로 섞이지 않으며 순서가 항상 보장됩니다.
Flux.concat(
Flux.just("A1", "A2"),
Flux.just("B1", "B2")
).subscribe(v -> log.info("value={}", v));
3. Flux.merge() - 동시에 subscribe하며 순서 보장 X
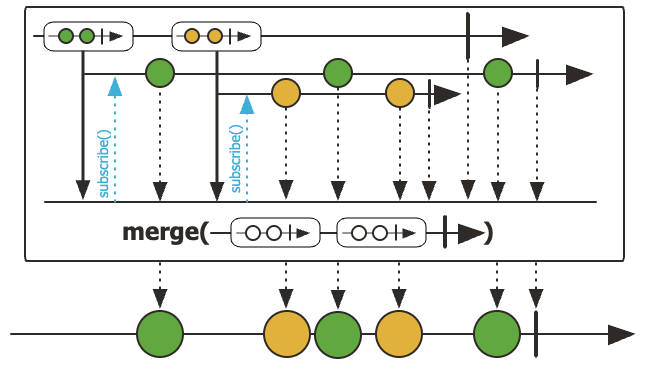
merge는 여러 Publisher를 동시에 subscribe하고, 이벤트가 도착하는 즉시 내려보냅니다.
따라서 발행 속도에 따라 onNext 순서가 섞일 수 있습니다.
Flux.merge(
Flux.interval(Duration.ofMillis(200)).map(i -> "A" + i),
Flux.interval(Duration.ofMillis(300)).map(i -> "B" + i)
).take(5).subscribe(v -> log.info("value={}", v));
4. Flux.mergeSequential - 동시에 subscribe하며 순서 보장 O
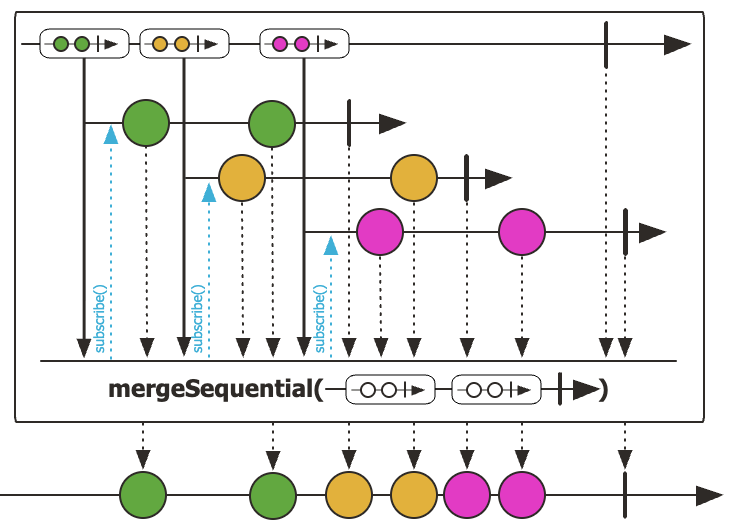
mergeSequential은 merge처럼 여러 Publisher를 동시에 subscribe하지만, 내부적으로 정렬하여 최종 구독자에게는 순서를 보장합니다.
Flux.mergeSequential(
Flux.interval(Duration.ofMillis(200)).map(i -> "A" + i),
Flux.interval(Duration.ofMillis(300)).map(i -> "B" + i)
).take(5).subscribe(v -> log.info("value={}", v));
5. Flux.zip() - 각 Publisher의 값을 1개씩 결합

zip은 두 개 이상의 Publisher가 각각 한 개씩 값을 생산해야 다음 이벤트를 생성합니다.
즉, 동일 인덱스 위치의 이벤트끼리 1:1로 묶어 출력하는 방식이며, 가장 느린 Publisher의 속도에 맞춰 진행됩니다.
Flux.zip(
Flux.just("A1", "A2", "A3"),
Flux.just(1, 2, 3),
(a, b) -> a + "-" + b
).subscribe(v -> log.info("value={}", v));
6. Flux.combineLatest() - 가장 최근 값을 기준으로 결합
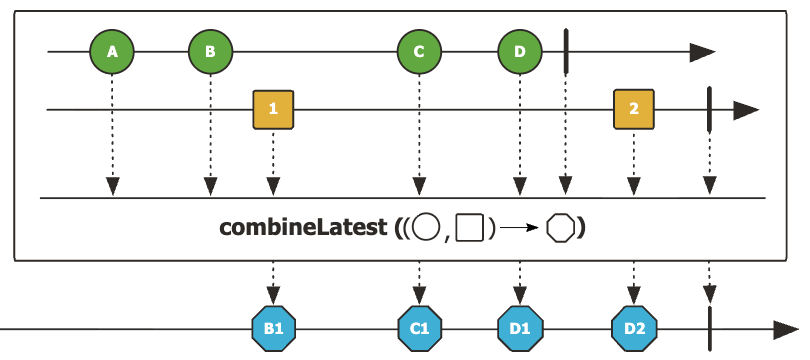
각 Publisher의 최신 값들을 조합하여 새로운 onNext 이벤트를 만들어냅니다.
Flux.combineLatest(
Flux.interval(Duration.ofMillis(300)).map(i -> "A" + i),
Flux.interval(Duration.ofMillis(500)).map(i -> "B" + i),
(a, b) -> a + "-" + b
).take(6).subscribe(v -> log.info("value={}", v));
유용한 연산자들
1. map / mapNotNull
map은 onNext 이벤트를 입력받아 변환 후 downstream으로 전달하는 가장 기본적인 변환 연산자입니다.
mapNotNull은 map과 유사하지만, 변환 결과가 null이면 이벤트를 자동 필터링합니다. (filter + map)
Flux.just(1,2,3)
.map(i -> i * 10)
.subscribe(v -> log.info("value={}", v));
Flux.just("A","", "B")
.mapNotNull(v -> v.isEmpty() ? null : v)
.subscribe(v -> log.info("value={}", v));
2. doOnXxx
doOnSubscribe, doOnNext, doOnComplete, doOnError 등 파이프라인의 이벤트를 관찰하거나 로깅할 때 사용하며, 스트림의 동작에는 영향을 주지 않습니다.
Flux.just(1,2,3)
.doOnNext(v -> log.info("next raw={}", v))
.map(v -> v * 2)
.doOnComplete(() -> log.info("complete!"))
.subscribe();
3. flatMap
flatMap은 단일 값 T를 Publisher Publisher<R>로 변환하고, 결과 이벤트를 펼쳐 downstream으로 흘려보냅니다.

Flux.just(1,2,3)
.flatMap(i -> Mono.just(i * 10))
.subscribe(v -> log.info("value={}", v));이 기능만 놓고 보면 Java Stream의 flatMap()과 매우 닮아있습니다. 하지만 Reactor의 flatMap은 더 강력한 비동기 처리 기능을 포함하고 있습니다.
| 구분 | Java Stream.flatMap | Reactor.flatMap |
| 역할 | 단순 컬렉션 구조 평탄화 | 평탄화 + 비동기 Publisher 결합 |
| 실행 방식 | 동기(Sync) | 비동기/Non-blocking |
| 이벤트 처리 | 즉시 순차적 처리 | 병렬 merge 가능(순서 보장 X) |
| 활용 사례 | List<List> → List | API 병렬 호출, DB 팬아웃, 비동기 조합 |
예를 들어, 다음과 같은 HTTP 병렬 호출 또한 flatMap으로 처리할 수 있습니다.
Flux.just("user1", "user2", "user3")
.flatMap(userId -> webClient.get()
.uri("/users/" + userId)
.retrieve()
.bodyToMono(User.class)
)
.subscribe(v -> log.info("value={}", v));만약 작업의 순서가 중요하다면 concatMap() 이나 flatMapSequential()을 사용해야 합니다.
4. filter
조건을 만족하는 값만 통과시키는 연산자입니다.
Flux.range(1,6)
.filter(i -> i % 2 == 0)
.subscribe(v -> log.info("value={}", v)); // 2,4,6
5. take / takeLast
take()는 처음 N 개의 값을 전달하고, takeLast()는 마지막 N 개의 값을 전달합니다.
개수가 아닌 시간(Duration)도 가능합니다.
Flux.range(1,10)
.take(3)
.subscribe(v -> log.info("value={}", v)); // 1,2,3
Flux.range(1,10)
.takeLast(3)
.subscribe(v -> log.info("value={}", v)); // 8,9,10
이때, take() 에는 limitRequest 라는 두 번째 인자가 있습니다. (default = true)
public final Flux<T> take(long n, boolean limitRequest)
limitRequest가 true라면 upstream에 요청하는 총 요청량을 n으로 제한합니다.
이 설정에서는 upstream이 n개보다 더 많은 데이터를 생산하지 못하도록 보장하며, 보다 엄격한 Backpressure 제어가 필요한 상황에서 유용합니다. 예를 들어 추가 데이터가 네트워크 전송 비용을 발생시키는 상황이라면 limitRequest = true가 적합합니다.
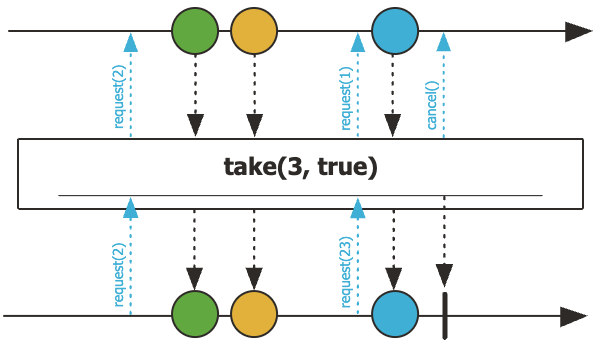
반면 limitRequest가 false이면 Backpressure 요청량을 제한하지 않고, upstream에 unbounded request를 보내지만 n개의 요소가 emit되면 cancel 후 complete됩니다. 이 방식에서는 cancel 이후에도 upstream이 여전히 많은 데이터를 생성할 수 있으며,
이는 불필요한 데이터 생산으로 이어질 수 있습니다.

6. skip / skipLast
skip()은 처음 N 개의 값을 생략하고, skipLast()는 마지막 N 개의 값을 생략합니다.
개수가 아닌 시간(Duration)도 가능합니다.
Flux.range(1,6)
.skip(2)
.subscribe(v -> log.info("value={}", v)); // 3,4,5,6
Flux.range(1,6)
.skipLast(2)
.subscribe(v -> log.info("value={}", v)); // 1,2,3,4
7. buffer
스트림을 버퍼의 개수만큼 리스트로 묶어서 전달합니다.
Flux.range(1,10)
.buffer(3)
.subscribe(list -> log.info("batch={}", list));
8. collectList
모든 onNext 이벤트를 메모리에 저장하고, onComplete 시점에 하나의 List 객체로 방출합니다.
Flux를 Mono<List<T>> 형태로 변경하는 대표적인 컬렉터입니다.
Flux.range(1,5)
.collectList()
.subscribe(list -> log.info("list={}", list));
9. cache
한 번 실행된 결과를 메모리에 저장하고, 다음 subscribe부터는 재실행 없이 저장된 onNext 이벤트를 다시 흘려보냅니다.
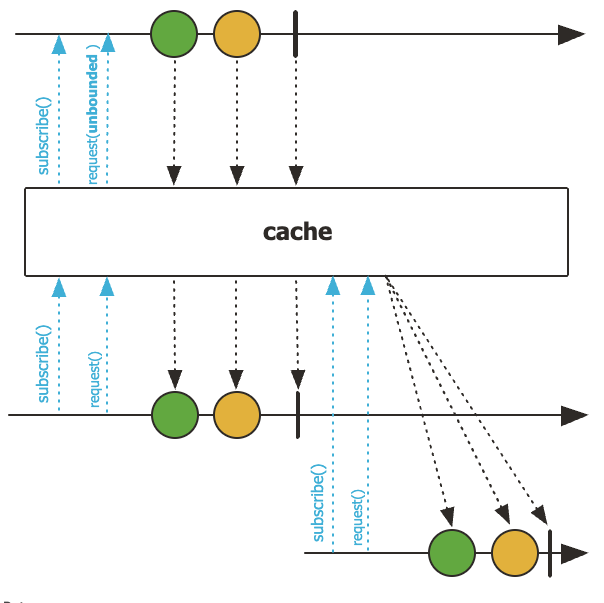
Flux<Integer> cached = Flux.range(1,3)
.doOnSubscribe(s -> log.info("source subscribe"))
.cache();
cached.subscribe(v -> log.info("A:{}", v)); // source 실행
cached.subscribe(v -> log.info("B:{}", v)); // 캐시 재사용
10. defer
defer()는 Publisher를 즉시 생성하지 않고, subscribe 시점에 Supplier를 실행하여 Publisher를 생성하는 연산자입니다.
즉, lazy factory 역할을 하며 매 구독마다 새로운 Publisher를 만들고 싶을 때 유용합니다.

Mono<String> mono = Mono.defer(() -> {
log.info("create Mono");
return Mono.just(LocalTime.now().toString());
});
mono.subscribe(v -> log.info("value: " + v));
mono.subscribe(v -> log.info("value: " + v));
Debug & Logging
리액티브 스트림은 Lazy, Asynchronous, Non-blocking으로 동작하기 때문에 일반적인 디버깅 방식이 잘 통하지 않습니다.
특히 onNext, onError, onComplete, request, cancel 등 이벤트 흐름을 따라가다 보면 "데이터가 어디서 사라졌는가?", "Backpressure는 어떻게 흘러가고 있는가?"를 추적하기가 어렵습니다.
Reactor는 이런 문제를 해결하기 위해 log(), checkpoint(), Hooks.onOperatorDebug(), 그리고 doOnXxx 기반의 관찰용 사이드 이펙트 기능을 제공합니다.
1. log()
log()는 Publisher 체인에 이벤트 기반 로깅을 추가하며, onSubscribe, request, onNext, onError, onComplete, cancel 흐름을 그대로 출력합니다.
Flux.range(1, 3)
.log()
.map(i -> i * 10)
.subscribe(v -> log.info("value={}", v));
2. doOnXxx()
Flux.just(1,2,3)
.doOnSubscribe(s -> log.info("subscribed"))
.doOnNext(v -> log.info("next={}", v))
.doOnComplete(() -> log.info("complete"))
.subscribe();
3. checkpoint()
Reactive pipeline은 stacktrace가 체인 전체를 명확히 보여주지 못하는 경우가 많은데, checkpoint()를 사용하면 어느 연산자 구간에서 문제가 발생했는지 추적 가능합니다.
Flux.just(1, 2, 3)
.map(i -> {
if (i == 2)
throw new RuntimeException("error");
return i;
})
.checkpoint("error-point")
.subscribe();
4. Hooks.onOperatorDebug()
전역 디버깅 모드를 켜서 모든 Operator에 stacktrace 캡쳐를 추가합니다.
Hooks.onOperatorDebug();
Flux.just(1, 2, 3)
.map(i -> {
if (i == 2)
throw new RuntimeException("error");
return i;
})
.subscribe();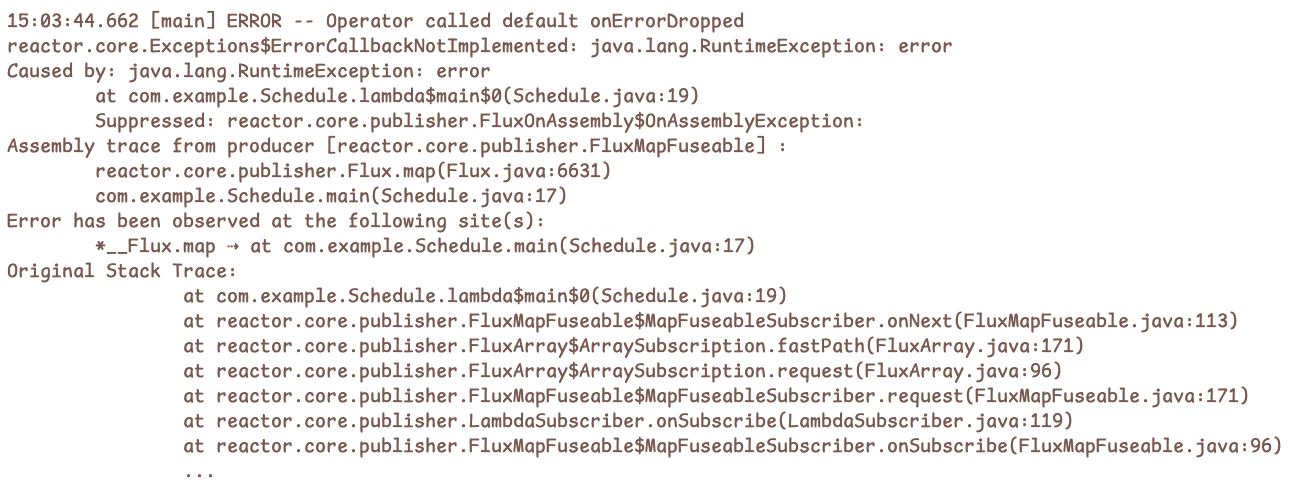
Backpressure
Reactor는 Reactive Streams 사양을 구현하고 있기 때문에 Subscriber는 언제든지 Publisher에게 얼마나 데이터를 받을 수 있는지를 요청(request) 단위로 전달할 수 있습니다. 이를 Backpressure라고 부르며, downstream 처리 속도가 느려도 upstream이 무제한으로 밀어넣지 않도록 흐름을 제어하고 압력을 역방향으로 전달하는 메커니즘입니다.
전통적인 Future/Callback 기반 비동기 처리에서는 producer가 빠르고 consumer가 느리면 큐 오버플로우, OutOfMemory, 응답지연을 유발하기 쉽지만, Reactor에서는 request량을 기반으로 조절 가능한 스트림 제어 모델을 제공합니다.
문제 상황
Flux.range(1, 1_000_000)
.map(i -> slowProcess(i))
.subscribe(v -> log.info("value={}", v));Consumer 기반 subscribe()를 사용하면 내부적으로 request(Long.MAX_VALUE)를 호출하여 사실상 무제한(unbounded) 요청을 보내게 됩니다. 그렇게 되면 upstream(Publisher)은 가능한 만큼 빠르게 데이터를 push하려고 하고, 만약 slowProcess()처럼 downstream 처리 속도가 느리다면 push된 onNext 이벤트는 Operator 내부 큐(buffer)에 계속 쌓이게 됩니다.
결국 소비 속도 < 생산 속도 상태가 유지되면, 버퍼는 점점 증가하고 메모리 사용량이 폭증할 수 있습니다.
1. request 수동 제어 - BaseSubscriber
가장 명확한 backpressure 제어 방법으로 필요할 때마다 직접 request를 호출합니다.
Flux.range(1, 100)
.subscribe(new BaseSubscriber<>() {
protected void hookOnSubscribe(Subscription s) {
request(1);
}
protected void hookOnNext(Integer v) {
log.info("value={}", v);
request(1);
}
});
2. 요청량 제한 연산자 - limitRate(), take()
limitRate(n)는 upstream 요청량을 n 단위로 batching하는 연산자로, prefetch-and-replenish(75% 소모 시 재요청) 전략을 사용하여 Backpressure를 보다 효율적으로 제어합니다.
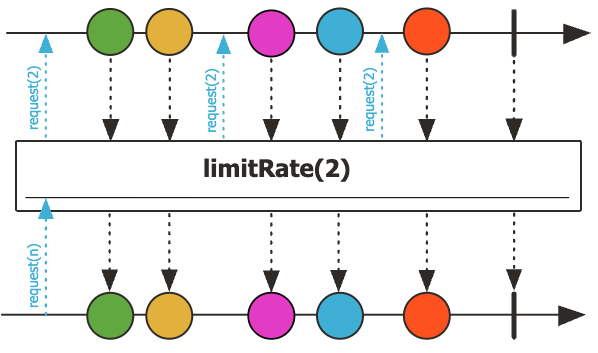
Flux.range(1,100)
.limitRate(10)
.subscribe(v -> log.info("value={}", v));
3. Backpressure Overflow 전략
Producer 속도를 줄일 수 없다면 어떻게 흘러넘치는 데이터를 처리할 것인지 정의할 수 있습니다.
| 연산자 | 동작 |
| onBackpressureBuffer() | 버퍼에 저장 (메모리 증가 위험) |
| onBackpressureDrop() | 처리 불가 데이터는 Drop |
| onBackpressureLatest() | 가장 최신 데이터만 유지 |
| onBackpressureError() | Overflow 시 에러 발생 |
Context
Reactive 파이프라인은 멀티 스레드 환경에서 비동기적으로 전환되기 때문에 일반적인 ThreadLocal 기반 로컬 저장 방식이 그대로 적용되지 않습니다. 스레드가 매번 바뀌기 때문에 ThreadLocal에 set한 값을 다음 처리 단계에서 보장할 수 없습니다.
이를 보완하기 위해 Reactor는 파이프라인 내부 어디에서든 접근 가능한 Context라는 Key-Value 기반 저장 영역을 제공합니다.
Reactor Context는 두 가지 타입으로 구분됩니다.
| 타입 | 설 명 |
| Context | 읽기/쓰기 가능. 새로운 Context를 생성하여 전달 |
| ContextView | 읽기 전용. downsteam 단계가 view로 조회 |
public interface ContextView {
<T> T get(Object key);
boolean hasKey(Object key);
boolean isEmpty();
int size();
}public interface Context extends ContextView {
Context put(Object key, Object value);
Context delete(Object key);
Context putAll(Context context);
}
Context는 다음과 같은 두 가지 중요한 특징을 가집니다.
- Context는 Publisher 생성 시점이 아니라 Subscribe 시점에 활성화되어, upstream(source 방향)로 전달
- Context는 immutable 하기 때문에, 수정이 아닌 새로운 Context를 생성하여 upstream(source 방향)로 전달
Context 초기화
Context의 초기 값은 subscribe()의 4번째 인자로 전달할 수 있으며, 전달된 값은 upstream 방향으로 전달됩니다.
public final Disposable subscribe(
@Nullable Consumer<T> consumer,
@Nullable Consumer<Throwable> errorConsumer,
@Nullable Runnable completeConsumer,
@Nullable Context initialContext)
)
Context는 생성을 위한 다양한 정적 팩토리 메서드를 지원하고 있습니다.
public interface Context extends ContextView {
static Context empty() {
return Context0.INSTANCE;
}
static Context of(Object key, Object value) {
return new Context1(key, value);
}
static Context of(Object key1, Object value1, Object key2, Object value2) {
return new Context2(key1, value1, key2, value2);
}
...
}
Context 읽기
Context는 lazy(구독 시점에 활성화)이기 때문에 값을 읽으려면 deferContextual() 연산자를 사용해야 합니다.
deferContextual(Function<ContextView, Publisher<T>> contextualPublisherFactory)deferContextual()은 동작 방식이 defer()와 거의 동일하지만, 차이점은 ContextView를 인자로 받는 Function을 사용한다는 점입니다.
Mono.just("Hello")
.flatMap(v -> Mono.deferContextual(contextView -> {
log.info("user: " + contextView.get("user"));
return Mono.just(v);
}
))
.subscribe(
v -> log.info("value: " + v),
Throwable::printStackTrace,
() -> {},
Context.of("user", "Jin")
);
Context 쓰기
contextWrite는 Context를 변경·추가하기 위한 연산자로 인자로 Function<Context, Context>를 전달합니다.
contextWrite(Function<Context, Context> contextModifier)
Context는 subscribe부터 시작하여 upstream으로 전달되며, contextWrite를 만나면 새로운 Context를 생성하여 다시 upstream으로 전달합니다. (Context는 불변이기 때문에 매번 새로 생성합니다.)
Mono.just("Hello")
.contextWrite(ctx -> ctx.put("user1", "Bob"))
.flatMap(v -> Mono.deferContextual(contextView -> {
log.info("user1: " + contextView.getOrEmpty("user1"));
log.info("user2: " + contextView.getOrEmpty("user2"));
return Mono.just(v);
}
))
.contextWrite(ctx -> ctx.put("user2", "Jin"))
.subscribe(v -> log.info("value: " + v));
위 예제 코드를 보면, flatMap 안에서 Mono.deferContextual을 통해 Context를 읽고 있습니다.
이때 해당 flatMap 연산자를 기준으로 아래쪽(downstream) 에서 contextWrite로 추가한 user2 값은 조회할 수 있지만,
위쪽(upstream) 에서 contextWrite로 추가한 user1 값은 조회할 수 없습니다.
이는 contextWrite가 자신보다 위에 위치한 연산자들(upstream)에만 영향을 주기 때문입니다.
'Spring > Webflux' 카테고리의 다른 글
| DispatcherHandler (1) | 2025.12.10 |
|---|---|
| Spring WebFlux (1) | 2025.12.09 |
| Netty - ByteBuf (2) | 2025.12.03 |
| Netty Server (0) | 2025.12.03 |
| Netty - EventLoop와 Channel (0) | 2025.12.02 |