

Spring Data R2DBC
Spring Data R2DBC는 R2DBC 드라이버를 기반으로 Reactive 환경에서 관계형 데이터베이스 접근을 가능하게 하는 Spring Data 모듈입니다. 이 모듈은 Spring의 핵심 프로그래밍 모델과 일관된 개발 경험을 제공하기 위해 설계되었으며, Reactive 애플리케이션에서 엔티티 중심의 데이터 접근 패턴을 적용할 수 있도록 지원합니다.
R2DBC는 논블로킹 I/O를 기반으로 설계된 데이터베이스 SPI이지만, 실제 애플리케이션 수준에서 사용하기 위해서는 매핑, CRUD 반복 코드, 쿼리 구성 등 부가적인 고려 사항이 필요합니다. Spring Data R2DBC는 이러한 영역을 추상화하여 개발자가 도메인 모델과 애플리케이션 로직에 집중할 수 있도록 돕습니다.
Spring Data R2DBC는 다음과 같은 기능을 제공합니다:
- Java @Configuration 기반의 R2DBC 설정 지원
- Row와 도메인 객체 간 매핑을 처리하는 통합 매핑 기능
- 엔티티 기반 데이터 접근을 위한 R2dbcEntityTemplate
- Repository 인터페이스의 자동 구현 및 메서드 이름 기반 쿼리 지원
- 애노테이션 기반 매핑 메타데이터와 확장 가능한 설계
이 모듈은 Domain-driven design(DDD) 원칙에 따라 저장 및 조회를 수행할 수 있도록 고수준 API를 제공합니다. 특히 R2dbcEntityTemplate과 Repository 지원은 Reactive 환경에서의 CRUD 작업을 단순화하며, R2DBC 드라이버만 사용했을 때 발생하는 반복 작업을 효과적으로 줄여줍니다.
Entity
Spring Data R2DBC에서 말하는 엔티티(Entity)는 이름은 JPA 엔티티와 동일하지만, 그 의미와 동작 방식은 전혀 다릅니다. JPA 엔티티는 Hibernate 같은 ORM 구현체가 관리하는 영속성 기반 모델로, 연관관계 매핑, 지연 로딩, Dirty Checking, 1차 캐시 등 복잡한 ORM 기능을 포함합니다.
반면 Spring Data R2DBC에서 사용되는 엔티티는 Spring Data Relational 매핑 엔진을 기반으로 한 단순 매핑 모델입니다. 이는 Spring Data JDBC와 동일한 철학을 공유하며, ORM 기능을 제공하지 않습니다. R2DBC 엔티티는 다음과 같은 최소한의 매핑 기능만 포함합니다.
- 테이블 ↔ 객체 간의 단순 매핑
- @Id를 통한 식별자 및 신규/기존 엔티티 판별
- Insert/Update/Delete SQL 생성
- Row ↔ Object 변환
- 간단한 aggregate 수준의 관계만 제한적으로 지원
즉, JPA 엔티티가 “도메인의 상태를 ORM 컨텍스트 내에서 관리하는 모델”이라면, R2DBC 엔티티는 Reactive 환경에서 SQL 기반 데이터 접근을 수행하기 위한 가벼운 POJO 매핑 모델에 가깝습니다. 기본적으로 클래스는 테이블명, 필드는 컬럼명으로 대응되며, 변환이 필요하면 R2dbcCustomConversions를 통해 Row ↔ 객체 매핑을 직접 커스터마이징할 수 있습니다.
이 엔티티를 중심으로 동작하는 핵심 구성 요소가 R2dbcEntityTemplate입니다. 템플릿은 Insert, Select, Update, Delete 같은 작업을 직관적인 API 형태로 제공하며, 각 연산은 Fluent 스타일 체이닝으로 이어져 종단 연산에서 SQL을 생성하고 실행합니다. 또한 모든 종단 메서드는 Mono 혹은 Flux를 반환하며, 실제 SQL 실행은 Publisher가 구독(subscription) 되는 시점에 이루어집니다.
Inserting
엔티티 저장 작업은 insert() 또는 update()로 수행되며, 기본 테이블명은 엔티티의 클래스명을 기반으로 결정됩니다.
다음은 Insert() 예제입니다.
Person person = new Person("John", "Doe");
// 1. 단순 insert
Mono<Person> saved = template.insert(person);
// 2. Fluent insert
Mono<Person> insert = template.insert(Person.class)
.using(new Person("John", "Doe"));
// 3. Stream insert
template.insert(Person.class)
.using(Flux.just(
new Person("A", "B"),
new Person("C", "D")
));
Selecting
조회는 select()와 selectOne()으로 수행되며, Query 객체를 통해 WHERE, 정렬, 페이징 등을 정의합니다.
Fluent select 에서는 다음과 같은 종단 연산을 지원합니다.
- all() → Flux
- first() → Mono (첫 행)
- one() → Mono (정확히 한 행, 여러 행이면 예외)
- count() → Mono<Long>
- exists() → Mono<Boolean>
다음은 select() 예제입니다.
// 1. select
Flux<Person> people = template.select(
query(where("firstname").is("John")),
Person.class
);
// 2. selectOne
Mono<Person> person = template.selectOne(
query(where("firstname").is("John")),
Person.class
);
// 3. Fluent select
Flux<Person> people = template.select(Person.class)
.matching(query(where("age").greaterThan(20)))
.all();
Updating
update() 에서는 단순 update와 Fluent update의 반환값이 달라집니다.
- 단순 update → 업데이트 된 엔티티
- Fluent update → 영향받은 행 수
다음은 update() 예제입니다.
Person modified = new Person("John", "Doe");
modified.setAge(42);
// 1. 단순 update
Mono<Person> updated = template.update(modified);
// 2. Fluent update
Mono<Long> update = template.update(Person.class)
.matching(query(where("firstname").is("John")))
.apply(update("age", 42));
Deleting
delete() 는 반환값으로 삭제된 행 수를 반환합니다.
다음은 delete() 예제입니다.
// 1. 단순 delete
Mono<Integer> deleted = template.delete(person);
// 2. Fluent delete
Mono<Long> deleted = template.delete(Person.class)
.matching(query(where("lastname").is("Doe")))
.all();
ID
Spring Data R2DBC에서 엔티티 식별자(ID)는 단순한 컬럼 이상의 의미를 가지며, 엔티티의 상태(state)를 판별하는 핵심 요소입니다. Spring Data R2DBC는 JPA처럼 영속성 컨텍스트나 Dirty Checking을 제공하지 않기 때문에, 엔티티가 신규인지(new) 또는 기존 데이터인지(existing) 여부를 오직 ID 값만으로 판단합니다.
- ID 값이 null 또는 0 → 새 엔티티(insert)
- ID 값이 존재함 → 기존 엔티티(update)
식별자 타입은 Long 또는 Integer를 사용해야 하며, 이는 DB에서 생성된 값을 엔티티 객체에 다시 세팅하기 위해 필요한 제약입니다.
Spring Data R2DBC는 ID를 직접 생성하지 않고, ID 생성 전략은 완전히 데이터베이스에 맡기는 방식을 기본 원칙으로 합니다.
DB가 생성한 식별자는 INSERT 이후 Spring Data가 읽어와 엔티티 객체에 반영합니다. Spring Data는 @Id 애노테이션으로 엔티티의 식별자를 인식하며, Dialect가 지원하는 경우 @Sequence 애노테이션을 통해 시퀀스 기반 생성도 사용할 수 있습니다.
R2dbcEntityTemplate
R2dbcEntityTemplate은 Spring Data R2DBC에서 엔티티 중심의 CRUD 및 쿼리 기능을 제공하는 핵심 컴포넌트입니다.
JPA의 EntityManager, JDBC의 JdbcTemplate에 해당하는 역할을 Reactive 환경에 맞게 구현한 고수준 API입니다.
R2dbcEntityTemplate은 다음과 같이 4개의 생성자를 갖고 있습니다.
public class R2dbcEntityTemplate implements R2dbcEntityOperations, BeanFactoryAware, ApplicationContextAware {
public R2dbcEntityTemplate(ConnectionFactory connectionFactory) {...}
public R2dbcEntityTemplate(DatabaseClient databaseClient, R2dbcDialect dialect) {...}
public R2dbcEntityTemplate(DatabaseClient databaseClient, R2dbcDialect dialect, R2dbcConverter converter) {...}
public R2dbcEntityTemplate(DatabaseClient databaseClient, ReactiveDataAccessStrategy strategy) {...}
...
}ConnectionFactory를 제공하거나 R2dbcDialect와 R2dbcConverter를 제공하여 생성할 수 있습니다.
- R2dbcDialect: 사용 중인 데이터베이스(MySQL, PostgreSQL 등)의 SQL 문법·바인딩 방식·페이징 전략 등의 특성을 정의하는 R2DBC 전용 Dialect입니다.
- R2dbcConverter: 데이터베이스 Row와 엔티티 객체 간의 변환을 담당하며, @Column 매핑 및 타입 변환을 처리하는 Spring Data R2DBC의 매핑 엔진입니다.
Spring Boot 환경에서는 R2dbcDataAutoConfiguration이 자동 구성해 템플릿을 빈으로 제공합니다.
@AutoConfiguration(
after = {R2dbcAutoConfiguration.class}
)
@ConditionalOnClass({DatabaseClient.class, R2dbcEntityTemplate.class})
@ConditionalOnSingleCandidate(DatabaseClient.class)
public class R2dbcDataAutoConfiguration {
private final DatabaseClient databaseClient;
private final R2dbcDialect dialect;
public R2dbcDataAutoConfiguration(DatabaseClient databaseClient) {
this.databaseClient = databaseClient;
this.dialect = DialectResolver.getDialect(this.databaseClient.getConnectionFactory());
}
@Bean
@ConditionalOnMissingBean
public R2dbcEntityTemplate r2dbcEntityTemplate(R2dbcConverter r2dbcConverter) {
return new R2dbcEntityTemplate(this.databaseClient, this.dialect, r2dbcConverter);
}
@Bean
@ConditionalOnMissingBean
public MappingR2dbcConverter r2dbcConverter(R2dbcMappingContext mappingContext, R2dbcCustomConversions r2dbcCustomConversions) {
return new MappingR2dbcConverter(mappingContext, r2dbcCustomConversions);
}
...
}
R2dbcEntityOperations
R2dbcEntityOperations는 Spring Data R2DBC에서 엔티티 기반 데이터 액세스를 정의하는 핵심 추상화 인터페이스입니다.
R2dbcEntityTemplate은 바로 이 인터페이스의 기본 구현체이며, 우리가 실제로 템플릿을 통해 수행하는 모든 CRUD 연산은 결국 이 인터페이스에 정의된 계약(contract)을 따릅니다.
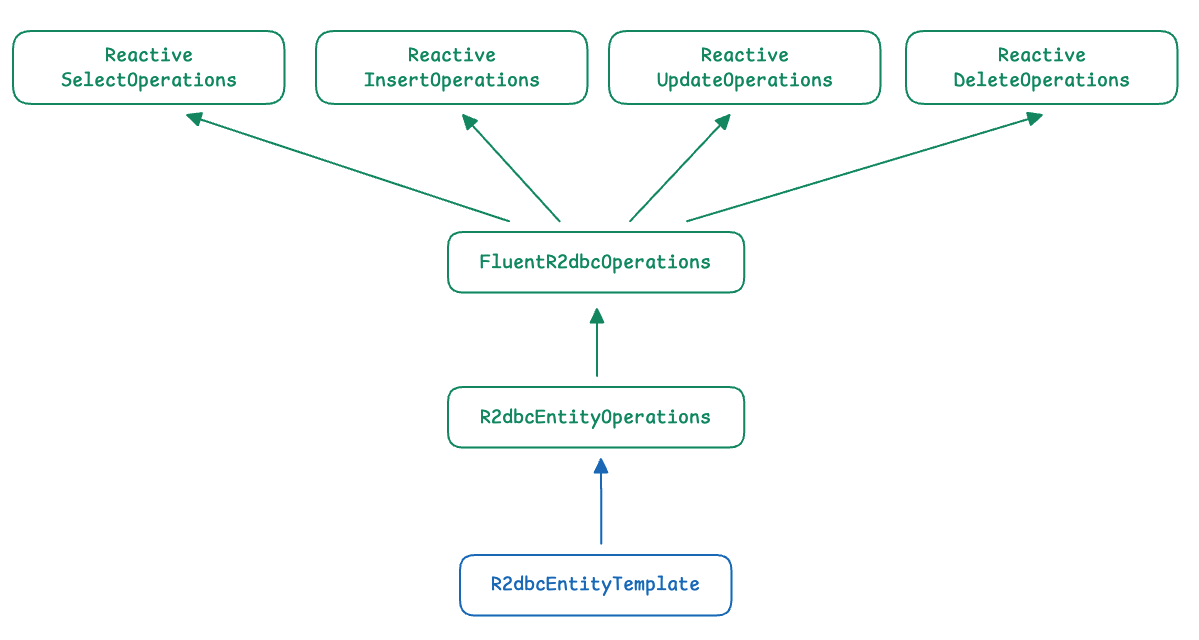
R2dbcEntityOperations는 FluentR2dbcOperations를 상속하고 있고, FluentR2dbcOperations는 4가지 ReactiveOperations를 상속하고 있습니다.
ReactiveSelectOperation
public interface ReactiveSelectOperation {
<T> ReactiveSelect<T> select(Class<T> domainType);
public interface ReactiveSelect<T> extends SelectWithTable<T>, SelectWithProjection<T> {
}
public interface TerminatingSelect<T> {
Mono<Long> count();
Mono<Boolean> exists();
Mono<T> first();
Mono<T> one();
Flux<T> all();
}
public interface SelectWithQuery<T> extends TerminatingSelect<T> {
SelectWithQuery<T> withFetchSize(int fetchSize);
TerminatingSelect<T> matching(Query query);
}
public interface SelectWithProjection<T> extends SelectWithQuery<T> {
<R> SelectWithQuery<R> as(Class<R> resultType);
}
public interface SelectWithTable<T> extends SelectWithQuery<T> {
default SelectWithProjection<T> from(String table) {
return this.from(SqlIdentifier.unquoted(table));
}
SelectWithProjection<T> from(SqlIdentifier table);
}
}
1. select(domainType) – 시작
- select(Person.class) 처럼 조회 대상 엔티티 타입을 지정하면서 시작
2. from() – 조회할 테이블 이름 선택 (선택)
- from()은 쿼리를 실행할 테이블 이름을 지정
- String 또는 SqlIdentifier 형태로 전달
- from("other_person")
- from(SqlIdentifier.quoted("person_table"))
- from()을 생략하면:
- domainType의 클래스명 또는 @Table 애노테이션 정보를 통해 기본 테이블 이름을 사용
3. as() – Projection(부분 매핑) 지정 (선택)
- as()는 엔티티 전체를 매핑하지 않고, 일부 필드만 매핑하고 싶을 때 사용
- 엔티티의 일부 프로퍼티만 담고 있는 DTO / 인터페이스 / 서브클래스를 넘기면, 해당 타입으로 projection
- 예: as(PersonSummary.class)
- as()를 생략하면:
- 기본적으로 엔티티 전체 필드가 매핑
4. matching() – WHERE 절 구성 (선택)
- matching()은 Query 객체를 받아서 WHERE 절에 들어갈 조건을 정의
- matching(query(where("firstname").is("John")))
- matching()을 생략하면:
- 테이블 전체에 대한 요청을 보내는 것과 동일하게 동작
(즉, WHERE 조건이 없는 SELECT)
- 테이블 전체에 대한 요청을 보내는 것과 동일하게 동작
5. 종결 연산(TerminatingSelect) – 실행
최종적으로는 TerminatingSelect<T>에 정의된 종단 메서드들 중 하나를 반드시 호출해야 실제 쿼리가 실행
- count()
- 조건에 맞는 row 개수를 Mono<Long>으로 반환
- exists()
- 조건에 맞는 row 존재 여부를 Mono<Boolean>으로 반환
- first()
- 조건에 맞는 첫 번째 row를 Mono<T>로 반환
- 결과가 없으면 빈 Mono
- one()
- 조건에 맞는 정확히 하나의 row를 Mono<T>로 반환
- 0개면 빈 Mono, 2개 이상이면 예외 발생
- all()
- 조건에 맞는 모든 row를 Flux<T>로 반환
ReactiveInsertOperation
public interface ReactiveInsertOperation {
<T> ReactiveInsert<T> insert(Class<T> domainType);
public interface ReactiveInsert<T> extends InsertWithTable<T> {
}
public interface TerminatingInsert<T> {
Mono<T> using(T object);
}
public interface InsertWithTable<T> extends TerminatingInsert<T> {
default TerminatingInsert<T> into(String table) {
return this.into(SqlIdentifier.unquoted(table));
}
TerminatingInsert<T> into(SqlIdentifier table);
}
}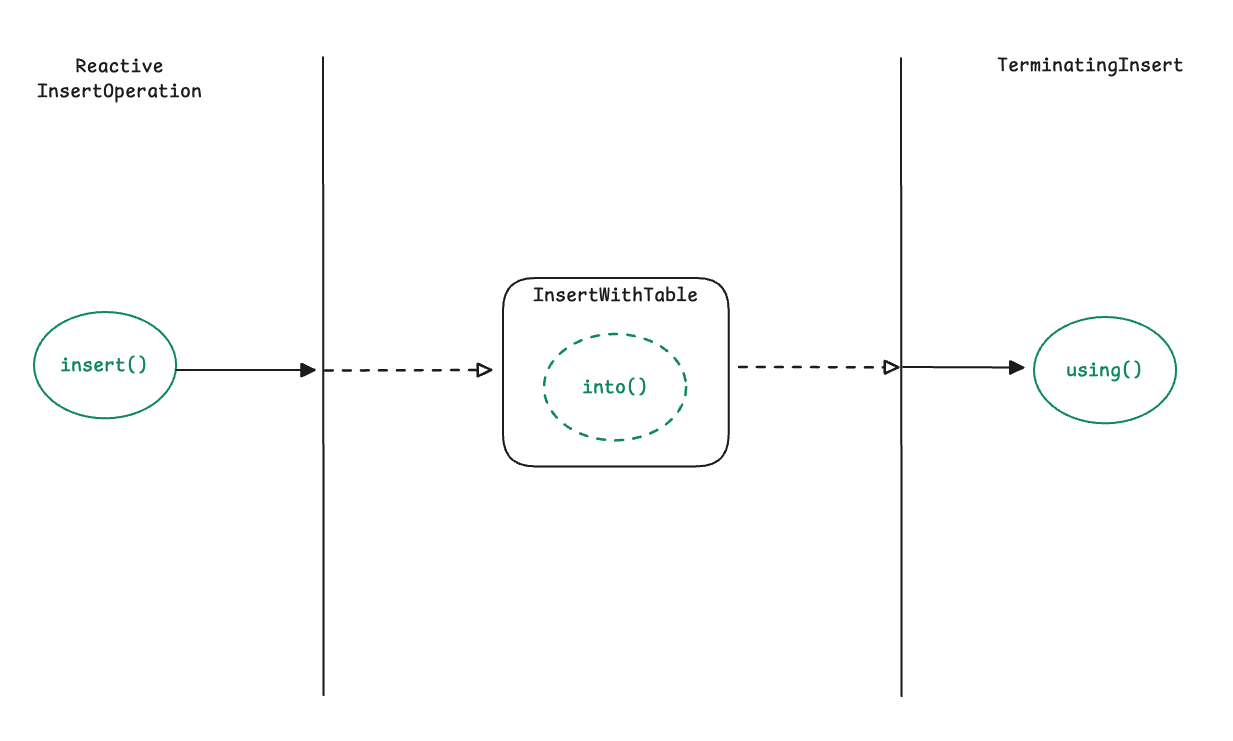
1. insert(domainType) — 시작
- 삽입할 엔티티 타입을 지정하며 시작
- 예: insert(Person.class)
- 테이블명이 지정되지 않으면 domainType의 클래스명 또는 @Table 정보를 기반으로 테이블명 결정
2. into() — INSERT할 테이블 지정 (선택)
- 문자열 또는 SqlIdentifier 형태로 테이블명을 명시
-
into("member_table")
-
- 생략하면 매핑 메타데이터(@Table, 클래스명)를 통해 테이블명 결정
3. using() — 실행
- 객체 1개 또는 Publisher(batch 형태)를 넘겨 INSERT를 수행
- using(new Person("A", "B"))
- using(Flux.just(p1, p2, p3))
- 단일 객체 / 다중 객체 모두 지원
- insert 결과는 Mono<T>로 반환되며, ID가 auto-generated라면 세팅되어 반환
ReactiveUpdateOperation
public interface ReactiveUpdateOperation {
ReactiveUpdate update(Class<?> domainType);
public interface ReactiveUpdate extends UpdateWithTable, UpdateWithQuery {
}
public interface TerminatingUpdate {
Mono<Long> apply(Update update);
}
public interface UpdateWithQuery extends TerminatingUpdate {
TerminatingUpdate matching(Query query);
}
public interface UpdateWithTable extends TerminatingUpdate {
default UpdateWithQuery inTable(String table) {
return this.inTable(SqlIdentifier.unquoted(table));
}
UpdateWithQuery inTable(SqlIdentifier table);
}
}
1. update(domainType) – 시작
- 갱신할 엔티티 타입 지정하면서 시작
- 예: update(Person.class)
2. inTable() – UPDATE할 테이블을 지정 (선택)
- 문자열 또는 SqlIdentifier로 테이블명을 직접 설정
- 생략하면 domainType → @Table → 클래스명 기반으로 테이블명 결정
- inTable("member")
3. matching() – WHERE 조건 지정 (선택)
- Query 객체로 조건을 설정
- matching(query(where("firstname").is("John")))
4. apply(Update) – 실행
- 반환: Mono<Long> (영향받은 row 수)
- apply(update("age", 30))
ReactiveDeleteOperation
public interface ReactiveDeleteOperation {
ReactiveDelete delete(Class<?> domainType);
public interface ReactiveDelete extends DeleteWithTable, DeleteWithQuery {
}
public interface TerminatingDelete {
Mono<Long> all();
}
public interface DeleteWithQuery extends TerminatingDelete {
TerminatingDelete matching(Query query);
}
public interface DeleteWithTable extends TerminatingDelete {
default DeleteWithQuery from(String table) {
return this.from(SqlIdentifier.unquoted(table));
}
DeleteWithQuery from(SqlIdentifier table);
}
}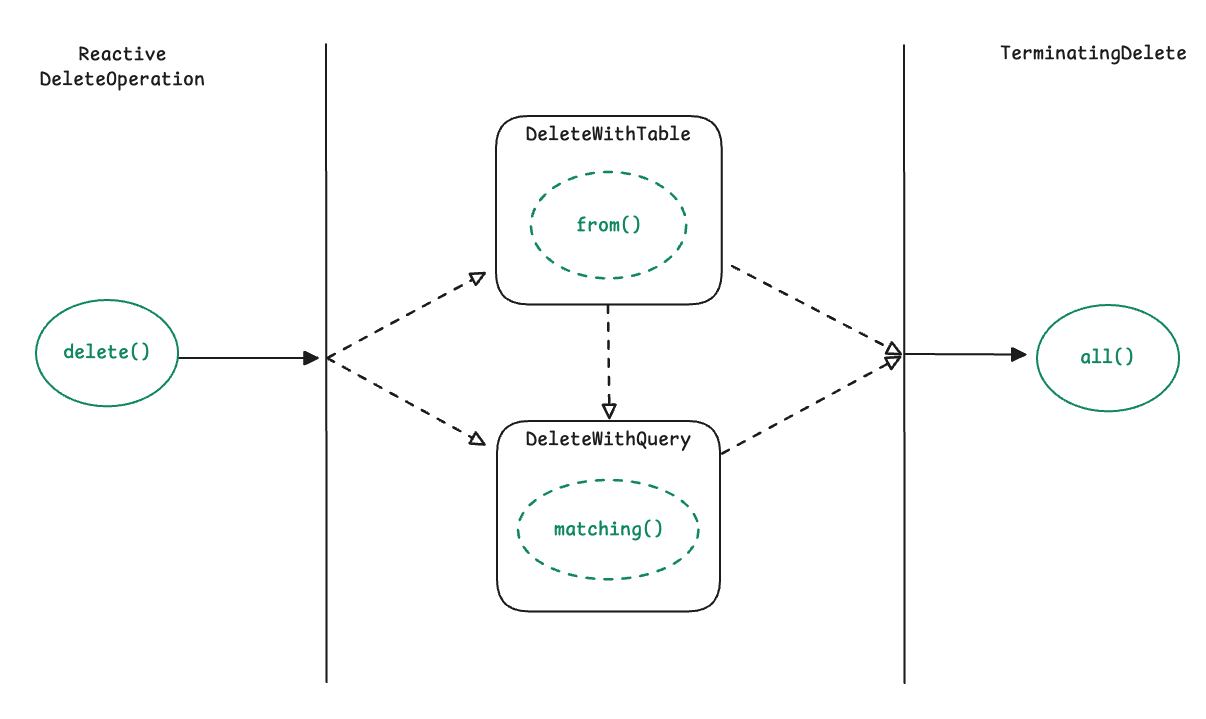
1. delete(domainType) – 시작
- delete(Person.class) 처럼 어떤 엔티티를 삭제할지 지정하면서 시작
- 별도의 테이블 이름을 주지 않으면, domainType의 클래스명 또는 @Table 매핑 정보를 통해 기본 테이블 이름을 사용
- template.delete(Person.class)
2. from() – 삭제 대상 테이블 지정 (선택)
- String 또는 SqlIdentifier 형태로 테이블명을 넘김
- template.delete(Person.class) .from("other_person");
- 생략하면 → 엔티티 매핑 정보(@Table, 클래스명)를 기준으로 테이블을 결정
3. matching() – WHERE 절 구성 (선택)
- Query 객체를 전달받아 WHERE 절에 들어갈 조건을 정의
- template.delete(Person.class) .matching(query(where("firstname").is("John")));
- 조건을 지정하지 않으면 → 테이블 전체에 대한 DELETE가 될 수 있으므로 사실상 필수
4. all() – 실행
- 유일한 종단 메서드
- 호출 시점에 실제 DELETE SQL이 실행
- Mono<Long> deletedCount = template.delete(Person.class)
.matching(query(where("firstname").is("John"))) .all();
- Mono<Long> deletedCount = template.delete(Person.class)
- 반환값은 Mono<Long>이며, 삭제된 row의 개수를 의미
단축 메서드
R2dbcEntityOperations에서는 FluentR2dbcOperations에서 제공하는 조합 방식 대신 단축 메서드를 제공합니다.
단축 메서드는 크게 Query 객체를 인자로 받는 메서드와, Entity를 직접 받는 메서드로 나눠집니다.
public interface R2dbcEntityOperations extends FluentR2dbcOperations {
/**
* Param: Query, Class<?>
*/
Mono<Long> count(Query query, Class<?> entityClass) throws DataAccessException;
Mono<Boolean> exists(Query query, Class<?> entityClass) throws DataAccessException;
<T> Flux<T> select(Query query, Class<T> entityClass) throws DataAccessException;
<T> Mono<T> selectOne(Query query, Class<T> entityClass) throws DataAccessException;
Mono<Long> update(Query query, Update update, Class<?> entityClass) throws DataAccessException;
Mono<Long> delete(Query query, Class<?> entityClass) throws DataAccessException;
/**
* Param: T entity
*/
<T> Mono<T> insert(T entity) throws DataAccessException;
<T> Mono<T> update(T entity) throws DataAccessException;
<T> Mono<T> delete(T entity) throws DataAccessException;
}
DatabaseClient
R2dbcEntityOperations는 getDatabaseClient() 라는 메서드도 갖고 있습니다.
public interface R2dbcEntityOperations extends FluentR2dbcOperations {
DatabaseClient getDatabaseClient();
...
}
DatabaseClient는 R2DBC ConnectionFactory 위에 구축된 고수준 SQL 실행 클라이언트로써 다음과 같은 특징을 제공합니다.
- SQL 문자열 기반 API
- 타입 안전한 바인딩(bind)
- Reactive Streams 기반 실행
- ResultView(fetch) API를 통한 행 매핑
다음은 DatabaseClient 의 소스코드입니다.
기본적으로 내부에 포함된 ConnectionFactory에 접근 가능하며, sql() 메서드를 통해서 GenericExecuteSpec을 반환합니다.
GenericExecuteSpec은 bind()를 통해서 parameter를 sql에 추가할 수 있고, fetch() 를 통해서 FetchSpec을 반환 받습니다.
public interface DatabaseClient extends ConnectionAccessor {
ConnectionFactory getConnectionFactory();
GenericExecuteSpec sql(String sql);
public interface GenericExecuteSpec {
GenericExecuteSpec bind(int index, Object value);
GenericExecuteSpec bindNull(int index, Class<?> type);
GenericExecuteSpec bind(String name, Object value);
GenericExecuteSpec bindNull(String name, Class<?> type);
GenericExecuteSpec bindValues(List<?> source);
GenericExecuteSpec bindValues(Map<String, ?> source);
FetchSpec<Map<String, Object>> fetch();
...
}
}
FetchSpec은 SQL 실행 후 결과 조회(fetch)를 담당하는 API로 다음과 같은 메서드를 가집니다.
- all()
- 여러 행을 Flux<T>로 반환합니다.
- 결과가 0개여도 빈 Flux로 반환됩니다.
- one()
- 정확히 한 행을 Mono<T>로 반환합니다.
- 행이 0개면 빈 Mono, 2개 이상이면 예외가 발생합니다.
- first()
- 여러 행 중 첫 번째 행만 Mono<T>로 반환합니다.
- 결과 개수와 상관없이 첫 행만 필요할 때 사용합니다.
- rowsUpdated()
- INSERT/UPDATE/DELETE 등 변경 쿼리에서 영향을 받은 행 수를 반환합니다.
- 결과가 없을 때에도 항상 숫자로 반환합니다.
public interface FetchSpec<T> extends RowsFetchSpec<T>, UpdatedRowsFetchSpec {
}public interface RowsFetchSpec<T> {
Mono<T> one();
Mono<T> first();
Flux<T> all();
}public interface UpdatedRowsFetchSpec {
Mono<Long> rowsUpdated();
}
다음은 DatabaseClient를 사용하여 Person 테이블을 만들고 1개의 데이터를 insert하고 전체 조회하는 예제입니다.
String createTableSql =
"CREATE TABLE IF NOT EXISTS person (" +
"id INT AUTO_INCREMENT PRIMARY KEY, " +
"name VARCHAR(255), " +
"gender VARCHAR(10), " +
"age INT)";
String insertSql =
"INSERT INTO person(name, age, gender) " +
"VALUES (:name, :age, :gender)";
String selectAllSql = "SELECT * FROM person";
// 1. 테이블 생성
Mono<Long> createTableMono =
client.sql(createTableSql)
.fetch()
.rowsUpdated();
// 2. 데이터 INSERT
Mono<Long> insertMono =
client.sql(insertSql)
.bind("name", "taewoo")
.bind("age", 20)
.bind("gender", "M")
.fetch()
.rowsUpdated();
// 3. 전체 조회
Flux<Map<String, Object>> selectAllFlux =
client.sql(selectAllSql)
.fetch()
.all();
// 4. create → insert → select 순서로 실행
createTableMono
.then(insertMono)
.thenMany(selectAllFlux)
.doOnNext(row -> {
Integer id = (Integer) row.get("id");
String name = (String) row.get("name");
Integer age = (Integer) row.get("age");
String gender = (String) row.get("gender");
log.info("id: {}, name: {}, age: {}, gender: {}",
id, name, age, gender);
})
.subscribe();
R2dbcConverter
R2dbcEntityOperations는 getConverter() 라는 메서드도 갖고 있습니다.
public interface R2dbcEntityOperations extends FluentR2dbcOperations {
R2dbcConverter getConverter();
...
}
R2DBC는 JPA처럼 엔티티 관리 기능을 제공하지 않기 때문에, 매핑 엔진이 필수적입니다.
R2dbcConverter는 다음 기능을 수행합니다.
- Row → 엔티티 변환
- 엔티티 → OutboundRow(SQL 바인딩 값)
- @Column, @Id 등 Spring Data Annotation 반영
Mapping
Spring Data는 도메인 객체와 데이터베이스 행(Row) 간의 변환을 수행하기 위해 기본적으로 Object Mapping 방식을 사용합니다.
Object Mapping은 Spring Data가 도메인 객체를 생성하고, 생성된 객체의 필드에 값을 채우는 전체 매핑 과정을 의미하는 핵심 메커니즘입니다.
Spring 공식 문서에서는 Object Mapping의 역할을 다음 두 가지로 정의합니다.
- 객체 생성(Instance Creation) — 어떤 생성자 또는 팩토리 메서드를 통해 객체를 생성할 것인가
- 객체 필드 채우기(Property Population) — 생성된 객체의 각 속성에 Row의 값을 어떻게 주입할 것인가
Spring Data R2DBC는 JPA처럼 데이터베이스가 제공하는 매핑 엔진에 의존하지 않습니다.
대신, R2dbcConverter의 기본 구현체인 MappingR2dbcConverter 를 중심으로 이 Object Mapping 과정을 Spring Data 내부에서 직접 수행합니다.
이 과정에서 Spring Data R2DBC는 다음과 같은 매핑 전략(Mapping Strategies) 을 사용하여 Row의 값을 도메인 객체의 필드에 어떻게 매핑할지 결정합니다. 매핑 전략은 다음의 우선순위에 따라 적용됩니다.
- Converter-based Mapping
- CustomConversions에 등록된 Custom Converter가 존재하는 경우 가장 우선 적용되며,
기본 매핑 규칙을 재정의할 수 있습니다.
- CustomConversions에 등록된 Custom Converter가 존재하는 경우 가장 우선 적용되며,
- Metadata-based Mapping
- @Table, @Column, @Id 등의 명시적 매핑 메타데이터가 선언된 경우,
해당 정보를 기반으로 매핑이 수행됩니다.
- @Table, @Column, @Id 등의 명시적 매핑 메타데이터가 선언된 경우,
- Convention-based Mapping
- 메타데이터도 없고 Custom Converter도 적용되지 않을 때,
Spring Data가 제공하는 기본 관례(conventions) 를 기반으로 자동 매핑이 이루어집니다.
- 메타데이터도 없고 Custom Converter도 적용되지 않을 때,
Object Mapping
먼저 Object Mapping의 두 가지 스텝에 대해 살펴보겠습니다.
1. Instance Creation
Spring Data는 도메인 객체를 어떻게 생성할지를 결정하기 위해 객체의 생성자, 정적 팩토리 메서드, Java Record 여부 등을 기반으로 다음 생성자 선택 알고리즘을 사용합니다.
생성자 선택 알고리즘
- @PersistenceCreator가 붙은 단일 static factory method가 존재하면 그 메서드를 사용
- 생성자가 하나뿐이라면 그 생성자를 사용
- 여러 생성자 중 @PersistenceCreator가 붙은 생성자가 하나라면 그 생성자를 사용
- Java Record 타입이면 canonical constructor 사용
- no-args 생성자가 있다면 그것을 사용하고, 나머지 생성자는 무시
데이터 매핑 시 생성자의 매개변수명과 엔티티의 프로퍼티명이 일치해야 하며, @Column 등 변경된 필드명도 반영됩니다. 또한 파라미터 이름 정보가 클래스 파일에 존재하거나 @ConstructorProperties가 필요합니다.
Spring Data는 객체를 생성할 때 성능을 위해 리플렉션을 직접 사용하지 않고, 런타임에 생성되는 팩토리 클래스(ObjectInstantiator)를 사용합니다. 다음은 Person 클래스에 대한 런타임 팩토리 클래스 예시입니다.
class Person {
Person(String firstname, String lastname) { … }
}
// Runetime Factory class
class PersonObjectInstantiator implements ObjectInstantiator {
Object newInstance(Object... args) {
return new Person((String) args[0], (String) args[1]);
}
}
이 방법은 리플렉션 대비 약 10% 더 빠른 성능을 제공하는데 이를 위해서는 다음 조건을 만족해야 합니다.
- private 클래스가 아니어야 합니다.
- non-static inner class가 아니어야 합니다.
- CGLib proxy 클래스가 아니어야 합니다.
- 선택된 생성자가 private이 아니어야 합니다.
이 조건을 만족하지 않으면 Spring Data는 리플렉션 방법을 대신 사용합니다.
2. Property Population
객체 인스턴스가 생성된 이후, Spring Data는 Row 값을 객체의 필드/프로퍼티에 채웁니다.
이 과정은 다음 순서를 따릅니다.
- 식별자(id) 속성을 먼저 채움 (순환 참조 해결)
- 생성자에서 채워지지 않은 나머지 필드를 채움
이때 다음과 같은 알고리즘을 사용하여 값을 채웁니다.
값 채우기 알고리즘
- immutable 필드 + withXxx() 존재 → withXxx() 메서드를 사용하여 새로운 객체를 만들어 교체
- 필드 getter + 필드 setter → setter 메서드 사용
- mutable 필드 → 직접 set
- immutable 필드 + withXxx() 없음 → persistence constructor를 사용해 전체 객체를 새로 생성하여 복사
- default → 직접 set
Object Creation과 마찬가지로, Property Population도 성능을 위해 런타임 Accessor를 사용합니다.
다음은 Person 클래스에 대한 런타임 Accessor 예시입니다.
class Person {
private final Long id;
private String firstname;
private @AccessType(Type.PROPERTY) String lastname;
Person() {
this.id = null;
}
Person(Long id, String firstname, String lastname) {
// Field assignments
}
Person withId(Long id) {
return new Person(id, this.firstname, this.lastname);
}
void setLastname(String lastname) {
this.lastname = lastname;
}
}
// Runtime Accessor
class PersonPropertyAccessor implements PersistentPropertyAccessor {
private static final MethodHandle firstname;
private Person person;
public void setProperty(PersistentProperty property, Object value) {
String name = property.getName();
if ("firstname".equals(name)) {
firstname.invoke(person, (String) value);
} else if ("id".equals(name)) {
this.person = person.withId((Long) value);
} else if ("lastname".equals(name)) {
this.person.setLastname((String) value);
}
}
}
이 방법은 리플렉션 대비 약 25% 더 빠른 성능을 제공하는데 이를 위해서는 다음 조건을 만족해야 합니다.
- 클래스는 default package 또는 java 패키지에 있으면 안 됩니다.
- 클래스 및 생성자는 public이어야 합니다.
- inner class는 static이어야 합니다.
- JVM이 클래스 로더에 새로운 클래스를 정의할 수 있어야 합니다. (Java 9+ 모듈 제한 영향 있음)
이 조건을 만족하지 않으면 Spring Data는 리플렉션 방법을 대신 사용합니다.
Best Practice
✔ 1) 가능하면 불변 객체(immutable object) 사용
- 생성자 한 번 호출로 객체를 완전히 구성할 수 있음
- setter를 제거해 도메인 객체의 순수성을 유지
- 생성자 기반 materialization은 property population 대비 최대 30% 빠름
✔ 2) 모든 필드를 받는 all-args 생성자 제공
- immutable하지 않더라도 성능 최적화 가능
- 생성자에서 값이 모두 세팅되면 setter를 생략할 수 있어 매핑 속도 향상
✔ 3) 오버로딩된 생성자 대신 정적 팩토리 메서드 사용
- @PersistenceCreator 필요성을 줄여줌
- 기본 생성 로직을 한 곳에 모을 수 있음
✔ 4) 매핑 최적화 제약 조건 만족
- private class/constructor 피하기
- non-static inner class 피하기
✔ 5) 식별자(id)는 final + withXxx() 방식 권장
- DB에서 id 생성 시 기존 객체 변경이 아니라 새 객체를 만들어 교체
- 불변성을 유지하면서도 DB 기반 id 매핑이 가능
✔ 6) Lombok @AllArgsConstructor 활용 추천
- 필드가 많은 도메인에서 반복되는 생성자 보일러플레이트 제거
Convention-based Mapping
Convention-based Mapping은 Spring Data가 Object Mapping을 수행할 때 적용하는 기본 매핑 전략(Default Mapping Strategy) 입니다.
Spring Data R2DBC의 MappingR2dbcConverter는 매핑 메타데이터(@Table, @Column, @Id 등)가 제공되지 않은 경우, 이 기본 전략에 정의된 관례(conventions)를 기반으로 도메인 객체와 데이터베이스 Row 간의 매핑을 자동으로 결정합니다.
Convention
- 도메인 클래스의 짧은 이름(short class name) 을 기반으로 테이블 이름을 생성합니다.
- CamelCase → SNAKE_CASE 변환
- 모두 대문자로 변환
- 기본적으로 SQL에서 따옴표 없이(unquoted) 사용
- 필드명 역시 동일한 규칙(CamelCase → 대문자 SNAKE_CASE)으로 컬럼명에 매핑됩니다.
- 중첩 객체(Nested Object) 는 지원하지 않습니다.
- CustomConversions에 등록한 Converter 를 통해 기본 매핑 규칙을 재정의할 수 있습니다.
- 필드 기반(Field-based) 접근 방식을 사용합니다. (JavaBean getter/setter 기반 아님)
- Convention 기반 매핑에서도 Object Mapping의 생성자 선택 규칙이 동일하게 적용됩니다.
Naming Strategy
위에서 설명한 Convention들은 내부적으로 NamingStrategy를 사용하여 테이블명과 컬럼명을 생성하기 때문에, NamingStrategy 인터페이스를 직접 구현해 Bean으로 등록하면 Convention-based Mapping의 이름 생성 규칙을 원하는 방식으로 커스터마이징할 수 있습니다.
public interface NamingStrategy {
default String getSchema() {
return "";
}
default String getTableName(Class<?> type) {
return ParsingUtils.reconcatenateCamelCase(type.getSimpleName(), "_");
}
default String getColumnName(RelationalPersistentProperty property) {
return ParsingUtils.reconcatenateCamelCase(property.getName(), "_");
}
default String getReverseColumnName(RelationalPersistentProperty property) {
return property.getOwner().getTableName().getReference();
}
default String getReverseColumnName(RelationalPersistentEntity<?> owner) {
return this.getTableName(owner.getType());
}
default String getKeyColumn(RelationalPersistentProperty property) {
String var10000 = this.getReverseColumnName(property);
return var10000 + "_key";
}
}
Metadata-based Mapping
Metadata-based Mapping은 Spring Data가 Object Mapping을 수행할 때 도메인 클래스에 매핑 메타데이터가 제공된 경우 적용되는 명시적 매핑 전략(Explicit Mapping Strategy) 입니다.
Spring Data R2DBC의 MappingR2dbcConverter는 엔티티에 @Table, @Column, @Id, @Embedded 등과 같은 매핑 애노테이션이 선언되어 있으면, Convention 기반 규칙보다 이 메타데이터를 우선 적용하여 도메인 객체와 데이터베이스 Row 간의 매핑을 결정합니다.
주요 매핑 애노테이션
- @Table
- 클래스가 특정 테이블에 매핑됩니다.
필수는 아니지만, 선언할 경우 Spring Data가 메타데이터를 미리 스캔해 초기 매핑 비용을 줄일 수 있습니다.
- 클래스가 특정 테이블에 매핑됩니다.
- @Id
- 엔티티의 PK를 나타내며,
@Embedded 와 함께 사용하면 복합 키도 구성할 수 있습니다.
- 엔티티의 PK를 나타내며,
- @Column
- 필드를 특정 컬럼 이름에 매핑합니다.
컬럼 이름은 항상 따옴표로 감싸져(case-sensitive) SQL에서 사용됩니다.
- 필드를 특정 컬럼 이름에 매핑합니다.
- @Embedded
- 중첩 객체를 하나의 테이블 컬럼들로 확장하여 매핑합니다.
Prefix 지정 및 복합 키 구성 가능.
- 중첩 객체를 하나의 테이블 컬럼들로 확장하여 매핑합니다.
- @InsertOnlyProperty
- insert 시에만 저장되고 update 시 무시됩니다.
- @MappedCollection
- 컬렉션이나 중첩 엔티티가 부모와 어떻게 매핑되는지 정의합니다.
- @Transient
- DB에 저장하지 않을 필드를 지정합니다.
- @PersistenceCreator
- Row → Object 변환 시 사용할 생성자/팩토리 메서드를 명시합니다.
- @Value
- 생성자 파라미터에 SpEL 기반 변환을 적용할 수 있습니다.
- @Version
- 낙관적 락을 위한 버전 관리 필드입니다.
기본 타입 매핑(Default Type Mapping)
Spring Data R2DBC는 다양한 자바 타입을 SQL 컬럼 타입으로 자동 변환합니다.
| Source Type | Target Type | 설명 |
| Primitive, Wrapper | Passthru | 그대로 저장/조회됨 |
| String, BigDecimal, UUID | Passthru | |
| JSR-310 Date/Time | Passthru | |
| Enum | String | 기본적으로 문자열로 저장됨 |
| byte[], ByteBuffer | Binary | 바이너리로 처리 |
| Collection | Array | 드라이버가 지원할 경우 |
| Complex Object | Converter 필요 | Converter 없으면 매핑 불가 |
Convention-based Mapping
Convention 기반 규칙이나 매핑 애노테이션만으로는 표현하기 어려운 매핑 요구가 있습니다.
예를 들어 특정 타입을 DB의 원시 값으로 저장하거나, Row를 읽을 때 값을 가공해야 하거나, 기본 매핑 규칙 대신 “개발자가 정의한 매핑 로직”을 적용하고 싶은 경우가 그렇습니다.
이러한 상황에서 사용하는 전략이 바로 Converter-based Mapping입니다.
Spring Data R2DBC는 MappingR2dbcConverter 내부에 두 가지 종류의 Converter를 등록하여 Row ↔ Object 변환 과정을 원하는 방식으로 완전히 재정의할 수 있도록 지원합니다.
- Reading Converter : Row → Object
- Writing Converter : Object → OutboundRow
Converter를 사용하면 Spring Data의 Object Mapping 과정을 우회하여 도메인 객체의 생성 방식과 저장 방식을 모두 직접 제어할 수 있습니다.
Converter 기반 매핑을 사용하려면 AbstractR2dbcConfiguration을 확장하여 원하는 Converter만 등록하면 됩니다.
public abstract class AbstractR2dbcConfiguration implements ApplicationContextAware {
public abstract ConnectionFactory connectionFactory();
public R2dbcDialect getDialect(ConnectionFactory connectionFactory) {
return DialectResolver.getDialect(connectionFactory);
}
@Bean({"r2dbcDatabaseClient", "databaseClient"})
public DatabaseClient databaseClient() {
ConnectionFactory connectionFactory = this.lookupConnectionFactory();
return DatabaseClient.builder().connectionFactory(connectionFactory).bindMarkers(this.getDialect(connectionFactory).getBindMarkersFactory()).build();
}
@Bean
public MappingR2dbcConverter r2dbcConverter(R2dbcMappingContext mappingContext,
R2dbcCustomConversions r2dbcCustomConversions) {
return new MappingR2dbcConverter(mappingContext, r2dbcCustomConversions);
}
@Bean
public R2dbcCustomConversions r2dbcCustomConversions() {
return new R2dbcCustomConversions(this.getStoreConversions(), this.getCustomConverters());
}
protected List<Object> getCustomConverters() {
return Collections.emptyList();
}
...
}
MappingR2dbcConverter는 생성 시점에 mappingContext와 r2dbcCustomConversions를 생성자 인자로 받아 초기화되며,
커스텀 변환 로직을 적용하고 싶다면 AbstractR2dbcConfiguration에서 getCustomConverters() 메서드를 오버라이드하여 원하는 Converter를 등록하면 됩니다.
여기서 중요한 점은, AbstractR2dbcConfiguration을 구현할 때 반드시 connectionFactory() 메서드를 구현해야 한다는 것입니다. 이는 R2dbcDialect 결정 과정과 DatabaseClient 생성 과정에서 ConnectionFactory가 필수적으로 사용되기 때문입니다.
다음은 공식 문서에 소개된 예제입니다.
@Configuration
public class MyAppConfig extends AbstractR2dbcConfiguration {
public ConnectionFactory connectionFactory() {
return ConnectionFactories.get("r2dbc:…");
}
// the following are optional
@Override
protected List<Object> getCustomConverters() {
return List.of(new PersonReadConverter(), new PersonWriteConverter());
}
}@ReadingConverter
public class PersonReadConverter implements Converter<Row, Person> {
public Person convert(Row source) {
Person p = new Person(source.get("id", String.class),source.get("name", String.class));
p.setAge(source.get("age", Integer.class));
return p;
}
}
@WritingConverter
public class PersonWriteConverter implements Converter<Person, OutboundRow> {
public OutboundRow convert(Person source) {
OutboundRow row = new OutboundRow();
row.put("id", Parameter.from(source.getId()));
row.put("name", Parameter.from(source.getFirstName()));
row.put("age", Parameter.from(source.getAge()));
return row;
}
}
R2dbcRepository
앞서 R2DBC의 핵심 구성 요소인 DatabaseClient, R2dbcEntityTemplate, 그리고 매핑/컨버터 구조를 살펴보았습니다. 이들은 모두 낮은 수준의 제어와 높은 유연성을 제공하지만, 반대로 말하면 반복적인 CRUD 코드를 매번 직접 작성해야 한다는 의미이기도 합니다.
Spring Data R2DBC는 이러한 반복을 줄이기 위해 Repository 추상화 계층을 제공하며, 그 중심에 있는 인터페이스가 바로 R2dbcRepository입니다.
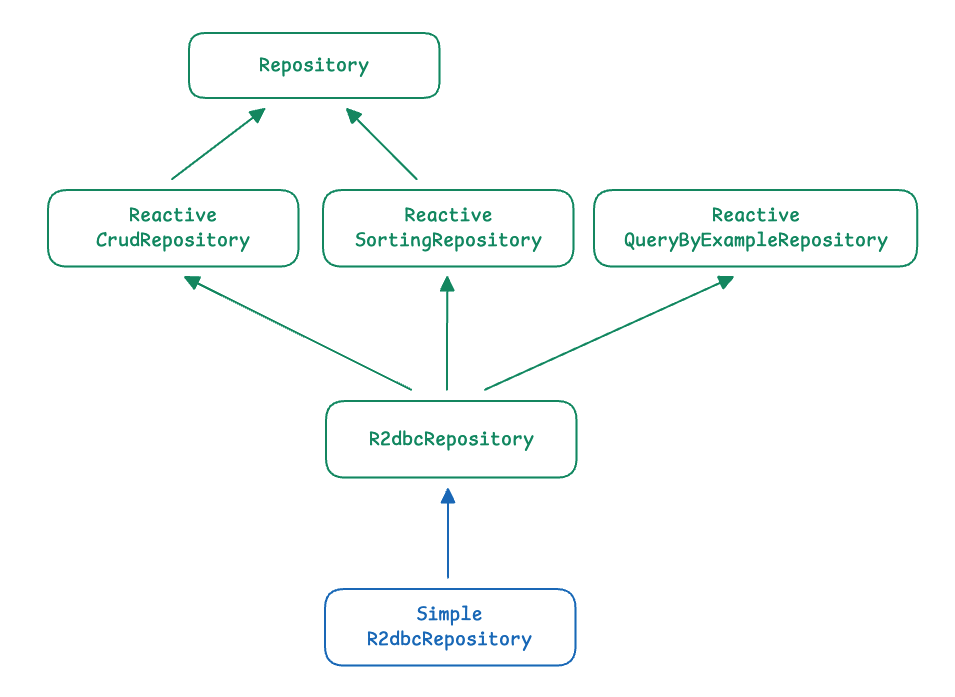
Repository
Repository는 메서드를 전혀 정의하지 않는 마커 인터페이스입니다.
@Indexed
public interface Repository<T, ID> {
}
ReactiveCrudRepository
Spring data reactive에서는 CrudRepository의 Reactive 버전인 ReactiveCrudRepository 지원합니다. 이 인터페이스는 R2DBC 전용이 아닌, MongoDB, Cassandra 등 다른 Reactive Store에서도 동일하게 사용됩니다.
@NoRepositoryBean
public interface ReactiveCrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> Mono<S> save(S entity);
<S extends T> Flux<S> saveAll(Iterable<S> entities);
<S extends T> Flux<S> saveAll(Publisher<S> entityStream);
Mono<T> findById(ID id);
Mono<T> findById(Publisher<ID> id);
Mono<Boolean> existsById(ID id);
Mono<Boolean> existsById(Publisher<ID> id);
Flux<T> findAll();
Flux<T> findAllById(Iterable<ID> ids);
Flux<T> findAllById(Publisher<ID> idStream);
Mono<Long> count();
Mono<Void> deleteById(ID id);
Mono<Void> deleteById(Publisher<ID> id);
Mono<Void> delete(T entity);
Mono<Void> deleteAllById(Iterable<? extends ID> ids);
Mono<Void> deleteAll(Iterable<? extends T> entities);
Mono<Void> deleteAll(Publisher<? extends T> entityStream);
Mono<Void> deleteAll();
}
ReactiveSortingRepository
ReactiveSortingRepository는 이름 그대로 Reactive 환경에서 정렬(Sort)을 지원하기 위한 인터페이스입니다.
@NoRepositoryBean
public interface ReactiveSortingRepository<T, ID> extends Repository<T, ID> {
Flux<T> findAll(Sort sort);
}
findAll은 Sort 를 인자로 받으며, 내부적으로 Order 객체를 포함하고 있습니다.
public class Sort implements Streamable<Order>, Serializable {
public static Sort by(String... properties) {...}
public static Sort by(List<Order> orders) {...}
public static Sort by(Order... orders) {...}
public static Sort by(Direction direction, String... properties) {...}
...
public static enum Direction {
ASC,
DESC;
...
}
public static class Order implements Serializable {
public static Order by(String property) {...}
public static Order asc(String property) {...}
public static Order desc(String property) {...}
...
}
}
SimpleR2dbcRepository
Spring Data R2DBC가 런타임에 생성하는 기본 R2dbcRepository 구현체입니다. R2dbcEntityOperations를 기반으로 SQL 쿼리를 실행하고 결과를 Entity로 mapping합니다. 또한 기본적으로 모든 메서드에 ReadOnly 가 적용되어 있습니다.
@Transactional(
readOnly = true
)
public class SimpleR2dbcRepository<T, ID> implements R2dbcRepository<T, ID> {
private final RelationalEntityInformation<T, ID> entity;
private final R2dbcEntityOperations entityOperations;
private final Lazy<RelationalPersistentProperty> idProperty;
private final RelationalExampleMapper exampleMapper;
...
@Transactional
public <S extends T> Mono<S> save(S objectToSave) {
return this.entity.isNew(objectToSave) ?
this.entityOperations.insert(objectToSave) : this.entityOperations.update(objectToSave);
}
}public abstract class AbstractEntityInformation<T, ID> implements EntityInformation<T, ID> {
...
public boolean isNew(T entity) {
ID id = this.getId(entity);
Class<ID> idType = this.getIdType();
if (!idType.isPrimitive()) {
return id == null;
} else if (id instanceof Number) {
Number n = (Number)id;
return n.longValue() == 0L;
} else {
throw new IllegalArgumentException(String.format("Unsupported primitive id type %s", idType));
}
}
}
save() 메서드를 보면 entity가 isNew() 를 기준으로 insert와 update를 구분하고 있으며, isNew()는 @Id 에 해당하는 필드를 확인하여 null이거나 0이라면 새로운 entity로 간주합니다.
이렇듯 R2dbcRepository는 기본적으로 CRUD를 수행할 수 있는 메서드를 제공하지만, join이나 집계와 관련된 함수들은 제공하지 않습니다.
Query Methods
Spring Data는 쿼리를 Repository 인터페이스에 메서드를 선언하는 것만으로 정의할 수 있도록 지원합니다.
시작 키워드
| 시작 키워드 | 의미 | 예시 |
| find…By | 조회 | findByLastname(String) |
| read…By | 조회 | readByStatus(String) |
| get…By | 조회 | getByEmail(String) |
| query…By | 조회 | queryByAge(int) |
| search…By | 조회 | searchByName(String) |
| stream…By | 조회(스트리밍 의도) | streamByType(String) |
| count…By | 개수 집계 | countByStatus(String) |
| exists…By | 존재 여부 | existsByEmail(String) |
| delete…By | 삭제 | deleteByLastname(String) |
| remove…By | 삭제(동의어) | removeByStatus(String) |
제한 키워드
| 제한 키워드 | 의미 | 예시 |
| First | 첫 1건 | findFirstByLastname(String) |
| Top | 상위 N건 | findTop3ByStatus(String) |
| Distinct | 중복 제거 | findDistinctByLastname(String) |
| OrderBy…Asc/Desc | 정렬 | findByStatusOrderByCreatedAtDesc(String) |
| IgnoreCase | 대/소문자 무시 | findByEmailIgnoreCase(String) |
| AllIgnoreCase | 모든 String 조건에 대소문자 무시 | findByFirstNameAndLastNameAllIgnoreCase(String, String) |
조건 키워드
| 조건 키워드 | 예시 | 의미 |
| After | findByBirthdateAfter(date) | birthdate > date |
| GreaterThan | findByAgeGreaterThan(age) | age > age |
| GreaterThanEqual | findByAgeGreaterThanEqual(age) | age >= age |
| Before | findByBirthdateBefore(date) | birthdate < date |
| LessThan | findByAgeLessThan(age) | age < age |
| LessThanEqual | findByAgeLessThanEqual(age) | age <= age |
| Between | findByAgeBetween(from, to) | age BETWEEN from AND to |
| NotBetween | findByAgeNotBetween(from, to) | age NOT BETWEEN from AND to |
| In | findByAgeIn(ages) | age IN (…) |
| NotIn | findByAgeNotIn(ages) | age NOT IN (…) |
| IsNotNull / NotNull | findByFirstnameNotNull() | firstname IS NOT NULL |
| IsNull / Null | findByFirstnameNull() | firstname IS NULL |
| Like / StartingWith / EndingWith | findByFirstnameLike(name) | firstname LIKE ? |
| NotLike / IsNotLike | findByFirstnameNotLike(name) | firstname NOT LIKE ? |
| Containing | findByFirstnameContaining(name) | LIKE '%name%' |
| NotContaining | findByFirstnameNotContaining(name) | NOT LIKE '%name%' |
| (키워드 없음) | findByFirstname(name) | firstname = name |
| Not | findByFirstnameNot(name) | firstname != name |
| IsTrue / True | findByActiveIsTrue() | active IS TRUE |
| IsFalse / False | findByActiveIsFalse() | active IS FALSE |
@Query, @Modifying
query가 메서드 이름으로 전부 표현되지 않는 경우나 복잡한 query문을 사용하는 경우 @Query 를 사용하여 직접 SQL을 지정할 수도 있습니다.
interface UserRepository extends ReactiveCrudRepository<User, Long> {
@Query("select firstName, lastName from User u where u.emailAddress = :email")
Flux<User> findByEmailAddress(@Param("email") String email);
}
문자열 기반 쿼리(@Query)는 페이징을 지원하지 않으며, Sort, PageRequest, Limit 같은 값을 쿼리 파라미터로 받지도 않습니다.
또한 @Query 를 사용하여 UPDATE/DELETE 를 하는 경우 @Modifying 어노테이션을 같이 사용해야 합니다.
파라미터와 반환 타입
DB 조회를 수행하는 쿼리의 경우 다음과 같은 파라미터를 가질 수 있습니다.
Flux<Person> findByFirstname(String firstname);
Flux<Person> findByFirstname(Publisher<String> firstname);
Flux<Person> findByFirstnameOrderByLastname(String firstname, Pageable pageable);
DB 변경을 수행하는 쿼리의 경우 다음과 같은 반환 타입을 가질 수 있습니다.
Mono<Integer> deleteByLastname(String lastname); // 영향받은 row 수
Mono<Void> deletePersonByLastname(String lastname); // 결과 무시
Mono<Boolean> deletePersonByLastname(String lastname); // 1건 이상 성공하면 true