

함수 고급
가변 인수 함수
fmt 패키지의 Println() 함수와 같이 인수의 개수가 정해져 있지 않은 함수를 가변 인수 함수라고 합니다.
인수 타입 앞에 ...를 붙여서 해당 타입 인수를 여러 개 받는 가변 인수임을 표시하면 됩니다.
package main
func sum(nums ...int) int {
//
}
func Print(args ...interface{}) string {
//
}여러 타입의 인수를 가변 인수로 받으려면 모든 타입이 구현하고 있는 빈 인터페이스를 사용하면 됩니다.
defer 지연 실행
때론 함수가 종료되기 직전에 실행돼야 하는 코드가 있을 수 있습니다. 대표적으로 파일이나 소켓 핸들처럼 OS 내부 자원을 사용하는 경우입니다. 파일을 생성하거나 읽을 때 OS에 파일 앤들을 요청하면 OS는 파일 핸들을 만들어서 프로그램에 알려줍니다. 하지만 이 같은 자원은 OS 내부 자원이기 때문에 반드시 쓰고 나서 OS에 되돌려줘야 합니다. 당연히 프로그램이 종료되면 자동으로 모든 자원이 반환되지만 프로그램 실행 중에는 직접 반환해줘야 합니다. 이때 defer를 사용해 함수 종료 직전에 함수를 실행시킬 수 있습니다.
package main
import (
"fmt"
"os"
)
func main() {
f, err := os.Create("test.txt")
if err != nil {
fmt.Println("Failed to create a file")
return
}
defer fmt.Println("파일 닫은 후") // 1
defer f.Close()
defer fmt.Println("파일을 닫았습니다.") // 2
fmt.Println("파일 닫기 전") // 3
}defer는 역순으로 호출되기 때문에 실행 순서는 3 -> 2 -> 1 순으로 실행됩니다.
함수 타입 변수

CPU 내부에는 다음 명령어을 실행할 라인을 나태내는 레지스터인 프로그램 카운터가 있습니다. 1번 라인 명령을 실행하면 프로그램 카운터는 1이 증가하여 2를 가리키고 다음에 2번 라인을 실행하게 됩니다. 만약 3번 라인에서 f() 함수가 호출되면 프로그램 카운터는 f() 함수의 시작 표인트 즉, 100번 라인으로 변경되어서 다음 번에 100번 라인부터 명령을 실행하게 됩니다. 이것이 바로 함수 호출 과정입니다.
즉, 함수 시작 지점 역시 숫자로 표현할 수 있습니다. 이 함수 시작 지점이 바로 함수를 가리키는 값이고, 마치 포인터처럼 함수를 가리킨다고 해서 함수 포인터(function pointer)라고 부릅니다.
이처럼 함수도 숫자처럼 값으로 취급될 수 있기 때문에 변수에 할당할 수 있습니다.
함수 타입은 함수명과 본문을 제외한 함수 시그니처(function signature)로 표현됩니다.
package main
import "fmg"
func add(a, b int) int {
return a + b
}
func mul(a, b int) int {
return a * b
}
func getOperator(op string) func (int, int) int {
i op == "+" {
return add
} else if op == "*" {
return mul
} else {
return nil
}
}
func main() {
var operator func (int, int) int
operator = getOperator("*")
var result = operator(3,4)
}
함수 정의는 일반적으로 길기 때문에 매번 함수 정의를 쓰면 코드 가독성이 떨어집니다. 이 경우 별칭 타입을 써서 함수 정의를 짧게 줄일 수 있습니다.
type opFunc func (int, int) int
func getOperator(op string) opFunc {
//
}
func main() {
var operator opFunc
}
함수 리터럴
함수 리터럴(function literal)은 이름 없는 함수로 함수명을 적지 않고 함수 타입 변수값으로 대입되는 함수값을 의미합니다.
함수명이 없기 때문에 함수명으로 직접 함수를 호출할 수 없고 함수 타입 변수로만 호출됩니다. 다른 프로그래밍 언어에서는 익명 함수 또는 람다라고 불리기도 합니다.
위에서 함수 타입 변수로 만들어봤던 예시를 함수 리터럴을 사용해서 다시 작성해보겠습니다.
package main
type opFunc func(a, b int) int
func getOperator(op string) opFunc {
if op == "+" {
return func(a, b int) int {
return a + b
}
} else if op == "*" {
return func(a, b int) int {
return a * b
}
} else {
return. nil
}
}
func main() {
fn := getOperator("*")
returl := fn(3, 4)
}
◎ 함수 리터럴 내부 상태
함수 리터럴은 필요한 변수를 내부 상태로 가질 수 있으며 내부에서 사용되는 외부 변수는 자동으로 함수 내부 상태로 저장됩니다.
package main
func main() {
i := 0 // 외부 변수
f := func() { // 함수 리터럴 정의
i += 10
}
i++
f() // 함수 호출 -> i = 11
}i 값이 함수 리터럴이 정의되는 시점이 아닌 함수가 호출되는 시점 값으로 사용됩니다.
이렇게 함수 리터럴 외부 변수를 내부 상태로 가져오는 것을 캡쳐(capture)라고 합니다. 캡쳐는 값 복사가 아닌 참조 형태로 가져오게 되니 주의해야 합니다. 참조 형태로 가져온다는 것은 변수의 주소값을 포인터 형태로 내부 상태로 가져와 나중에 캡쳐된 내부 상채를 사용할 때 메모리 주소값을 통해 외부 변수에 접근하게 됩니다.
◎ 캡쳐(capture) 주의점
package main
import "fmt"
func CaptureLoop() {
f := make([]func(), 3)
for i := 0; i < 3; i++ {
f[i] = func() {
fmt.Println(i)
}
}
for i := 0; i < 3; i++ {
f[i]()
}
}
func CaptureLoop2() {
f := make([]func(), 3)
for i := 0; i < 3; i++ {
v := i
f[i] = func() {
fmt.Println(v)
}
}
for i := 0; i < 3; i++ {
f[i]()
}
}
func main() {
CaptureLoop() // 3, 3, 3
CaptureLoop2() // 0, 1, 2
}
CaptureLoop() 함수에서는 함수 리터럴을 정의할 때 사용한 외부 변수 i 는 for문의 초기문에서 정의된 변수로 차례로 0 -> 1 -> 2 -> 3 으로 값이 변경되고, 마지막 3일 때에는 for문 조건에 만족하지 못하여 for문을 종료하게 됩니다. 이때 변수 i 의 최종값이 3이었기 때문에 함수 슬라이스 변수 f 에 담긴 3개의 함수는 모두 최종값 3을 출력하는 함수를 갖고 있습니다.
CaptureLoop2() 함수에서는 함수 리터럴을 정의할 때 별도의 외부 변수 v 를 할당해서 정의하였는데, for문이 반복될 때마다 새롭게 변수 v 가 생성되기 때문에 각각 0, 1, 2 의 값을 갖는 총 3개의 v 변수가 생성됩니다. 함수 슬라이스 변수 f 에 담긴 3개의 함수는 각각 0, 1, 2 를 출력하는 함수를 갖고 있습니다.
이렇게 외부 변수를 함수 리터럴에서 사용할 경우 참조 형태로 가져온다는 것을 염두하지 않으면 예기치 못한 버그가 발생할 수 있습니다.
자료구조
리스트
리스트(list)는 기본 자료구조로서 여러 데이터를 보관할 수 있습니다. 배열과 가장 큰 차이점은 배열은 연속된 메모리에 데이터를 저장하는 반면, 리스트는 불연속된 메모리에 데이터를 저장한다는 것입니다.
리스트는 각 데이터를 담고 있는 요소들을 포인터로 연결한 자료구조입니다. 요소들이 포인터로 연결됐다고 해서 링크드 리스트(linked list)라고 부르기도 합니다.
type Element struct {
Value interface{ }
Next Element
Prev Element
}
Element는 리스트의 각 요소 데이터를 저장하는 구조체입니다.
Value는 실제 요소의 데이터를 저장하는 필드로 interface{ } 타입이기 때문에 어떤 타입값도 저장할 수 있습니다.
Next는 Element 타입으로 다음 Element 인스턴스의 메모리 주소를 갖고 있습니다. Next를 사용해 다음 요소 인스턴스로 접근할 수 있는데 이를 포인터를 통해 연결했다고 말합니다. 물론, 이전 요소의 Prev 포인터도 갖고 있습니다.
다음은 리스트의 기본 사용법에 대해 알아보겠습니다.
package main
import "container/list"
func main() {
v := list.New() // 새로운 리스트 생성
e4 := v.PushBack(4) // 리스트 뒤에 요소 추가
e1 := v.PushFront(1) // 리스트 앞에 요소 추가
v.InsertBefore(3, e4) // e4 요소 앞에 요소 삽입
v.InsertAfter(2, e1) // e1 요소 뒤에 요초 삽입
for e := v.Front(); e != nil; e = e.Next(){
// 각 요소 순회
}
for e := v.Back(); e != nil; e = e.Prev() {
// 각 요소 역순 순회
}
}
Front() 와 Back() 은 각각 첫 번째 요소와 마지막 요소를 반환합니다.
◎ 배열 vs 리스트
배열과 리스트는 모두 여러 요소들을 저장할 수 있는 자료구조입니다. 또 이 둘은 스택, 큐, 트리 등 다른 자료구조의 기본적인 형태로 사용되기 때문에 모든 자료구조의 기본이 되는 자료구조라고 볼 수 있습니다. 그래서 둘의 차이점을 이해하면 상황에 알맞게 자료구조를 선택할 수 있습니다.
1. 맨 앞에 데이터 추가하기
배열은 맨 앞에 요소를 추가할 때 맨 뒤에서부터 한 칸씩 값들을 뒤로 밀고 맨 앞의 값을 변경해야합니다. 이것을 Big-O 표기법으로 표기하면 O(N) 알고리즘이 됩니다.
반면 리스트는 맨 앞에 요소를 추가할 때 각 요소를 밀어낼 필요없이 맨 앞에 요소를 추가하고 연결만 만들어주면 됩니다. 이 경우는 Big-O 표기법으로 O(1)이라고 표기합니다. 결론적으로 배열보다 리스트가 맨 앞에 요소를 추가할 때 더 빠릅니다.
Big-O 표기법
Big-O 표기법은 알고리즘이 걸리는 시간의 최악의 경우를 나타내는 표기법입니다.
N개 요소를 처리하는 알고리즘의 처리 시간이 an³ + bn² + c 와 같은 방정식으로 표현된다면 상수인 a, b, c를 생략하고 가장 높은 차수인 O(n³)으로 표기합니다.
2. 특정 요소에 접근하기
배열은 배열 "시작 주소 + (인덱스 * 타입 크기)" 를 통해서 메모리의 위치를 찾아서 요소에 접근합니다. 위 공식으로 인해 요소 개수와 상관없이 상수 시간이 걸리기 때문에 Big-O 표기법으로 O(1)입니다.
반면 리스트에서는 각 요소가 포인터로 연결되어 있기 때문에 앞 요소들을 모두 거쳐야 네번째 요소에 접근할 수 있습니다. 특정 요소에 접근하려면 N-1번 링크를 거쳐야 하기 때문에 Big-O 표기법으로 O(n)입니다.
데이터 지역성(data locality)
데이터 지역성은 데이터가 밀접한 정도를 말합니다. 컴퓨터는 연산할 때 읽어온 데이터를 캐시라는 임시 저장소에 보관합니다. 이때 정확히 필요한 데이터만 가져오는게 아니라 그 주변 데이터를 같이 가져옵니다. 그 이유는 보통 연산이 일어난 다음에 높은 확률로 주변 데이터에 대한 연산이 이어지기 때문입니다. 그래서 필요한 데이터가 인접해 있을수록 처리 속도가 빨라지는데, 이를 데이터 지역성이 좋다고 말합니다. 배열은 연속된 메모리로 이뤄진 자료구조이고 리스트는 불연속이기 때문에 배열이 리스트에 비해서 데이터 지역성이 월등하게 좋습니다.
그래서 삽입과 삭제가 빈번하면 리스트가 배열보다 좋다고 말하지만, 요소 수가 적으면 데이터 지역성 때문에 오히려 배열이 리스트보다 효율적입니다.
실습: 큐 구현하기
리스트로 큐(queue)를 만들어보겠습니다. 큐는 먼저 입력된 값이 먼저 출력되는 FIFO(first in first out)자료구조입니다. 대표적으로 대기열(waiting queue)가 있습니다.

큐는 다음과 같은 특징이 있습니다.
- 들어간 순서 그대로 빠져나오기 때문에 순서가 유지됩니다.
- 새로운 요소는 항상 맨 마지막에 추가됩니다.
- 출력값은 맨 앞에서 하나씩 빼내게 됩니다.
큐는 대기열 작업이나 명령 큐처럼 순서가 유지되어야 하는 경우에 자주 사용됩니다. 큐는 배열과 리스트 중 무엇으로도 만들 수 있으나 출력값이 맨 앞에서 발생하기 때문에 대체로 리스트가 더 효율적입니다.
package main
import "container/list"
type Queue struct {
v *list.List
}
func (q *Queue) Push(val interface{}) {
q.v.PushBack(val)
}
func (q *Queue) Pop() interface{} {
front := q.v.Front()
if front != nil {
return q.v.Remove(front)
}
return nil
}
func NewQueue() *Queue {
return &Queue{ list.New() }
}
func main() {
queue := NewQueue()
for i := 1; i < 5; i++ {
queue.Push(i)
}
v := queue.Pop()
}
실습: 스택 구현하기
스택(stack)은 큐와 달리 LIFO(last in first out) 자료구조입니다. 즉 첫 번째 입력한 요소가 가장 마지막에 출력됩니다.
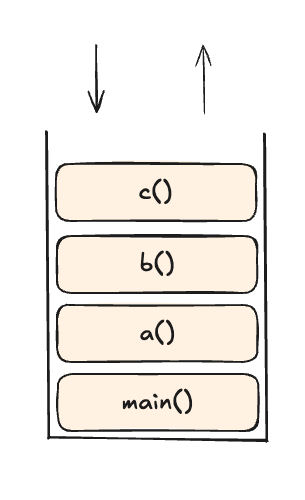
스택은 다음과 같은 특징을 갖습니다.
- 가장 최근에 넣은 것부터 역순으로 나오게 됩니다.
- 요소는 맨 뒤로 추가합니다.
- 요소를 뺄 때도 맨 뒤에서 빼냅니다.
스택은 순서가 반대가 되기 때문에 가장 최신 것부터 하나씩 되돌릴 때 주로 사용됩니다. 예를 들어 a() -> b() -> c() 순서로 함수를 호출하면 c() 함수가 종료되면 이전 호출 함수인 b()로 돌아가야 합니다. 호출 순서와 역순으로 진행되어야 하기 때문에 스택을 사용합니다.
package main
import "container/list"
type Stack struct {
v *list.List
}
func NewStack() *Stack {
return &Stack{ list.New() }
}
func (s *Stack) Push(val interface{}) {
s.v.PushBack(val)
}
func (s *Stack) Pop() interface{} {
back := s.v.Back()
if back != nil {
return s.v.Remove(back)
}
}
func main() {
stack := NewStack()
for i := 1; i < 5; i++ {
stack.Push(i)
}
val := stack.Pop()
}스택은 요소의 추가, 삭제가 항상 맨 뒤에서 발생하기 때문에 배열로 만들어도 성능의 손해가 없기 때문에 배열과 리스트 모두 구현 가능하지만 보통 큐는 리스트로, 스택은 배열로 구현합니다.
링
링(ring)은 맨 뒤의 요소와 맨 앞의 요소가 서로 연결된 자료구조입니다. 리스트를 기반으로 만들어진 자료구조로, 원형으로 연결되어 있기 때문에 환형 리스트라고 부릅니다. 그래서 링 자료구조에서는 시작도 없고 끝도 없습니다. 다만 현재 위치만 있을 뿐입니다.
링은 저장할 개수가 고장되고, 오래된 요소는 지워도 되는 경우에 적합합니다. 예를 들어 MS 워드는 Ctrl + z 를 눌러서 실행 취소를 할 수 있습니다. 이 기능을 지원하려면 지금까지 쓴 내용을 보관하고 있어야 하기 때문에 링이 적합합니다.
다음은 링 자료구조를 사용하는 예시입니다.
package main
import "container/ring"
func main() {
r := ring.New(5)
n := r.Len()
for i := 0; i < n; i++ {
r.Value = 'A' + i
r = r.Next()
}
for j := 0; j < n; j++ {
// 출력
r = r.Next()
}
for j := 0; j < n; j++ {
// 출력
r =. .Prev()
}
}
r 은 현재 위치를 나타내는 포인터로서 링 생성 시에는 첫 번째 요소를 가리킵니다.
링은 다음과 같은 경우에 사용합니다.
- 실행 취소 기능: 문서 편집기 등에서 일정한 개수의 명령을 저장하고 실행 취소하는 경우
- 고정 크기 버퍼 기능: 데이터에 따라 버퍼가 증가되지 않고 고정된 길이로 쓸 때
- 리플레이 기능: 게임 등에서 최근 플레이 10초를 다시 리플레이할 때와 같이 고정된 길이의 리플레이 기능을 제공할 때
맵
맵(map)은 키와 값 형태로 데이터를 저장하는 자료구조입니다. 언어에 따라서 dictionary, hash table, hash map 등으로 부릅니다.
맵은 리스트나 링과 달리 container 패키지가 아닌 Go 기본 내장 타입입니다.
다음은 맵을 사용하는 예시입니다.
package main
func main() {
m := make(map[string]string) // map[key]value
m["홍길동"] = "남자"
m["송하나"] = "여자"
for k, v := range m {
// 순회
}
delete(m, "홍길동") // delete(m, key)
delete(m, "김길동")
a := m["홍길동"]
}
없는 키값을 삭제할 때에는 동작하지 않습니다. 그리고 이미 삭제한 요소를 할당하면 value 타입의 기본값이 할당됩니다.
그런데 만약 value 타입이 int 라면 value가 0 인지, 기본값인 0이 할당된건지 어떻게 구분할까요?
v, ok := m[key]
위와 같이 반환값을 두 개로 받으면 값뿐 아니라 해당 요소가 존재하는지 여부도 boolean으로 알려줍니다.
◎ 맵, 배열, 리스트 속도 비교
- 맵은 삭제, 추가, 읽기에서 요소 개수와 상관없이 속도가 매우 빠르고 일정합니다.
- 배열은 추가, 삭제에서 요소 개수가 많아질수록 오래 걸립니다.
- 리스트는 요소 읽기에서 요소 개수가 많아질수록 오래 걸립니다.
맵의 원리(심화)
맵을 이해하려면 먼저 해시 함수(hash fucntion)의 동작을 이해해야 합니다. 맵을 다른 말로 해시맵 또는 해시테이블이라고 부를 만큼 맵과 해시는 뗄레야 뗄 수 없습니다.
해시(hash)란 잘게 부순다는 뜻으로 다음과 같은 3가지 특징을 만족해야 해시 함수라고 부를 수 있습니다.
- 같은 입력이 들어오면 같은 결과가 나온다.
- 다른 입력이 들어오면 되도록 다른 결과가 나온다.
- 입력값의 범위는 무한대이고 결과값은 특정 범위를 갖는다.
예를 들어 sin(x) 함수는 해시 함수의 조건을 만족합니다. 하지만 삼각함수는 계산이 복잡하고 결과가 실수로 나오기 때문에 해시 함수를 사용하지 않고 일반적으로 나머지 연산을 주로 사용합니다.
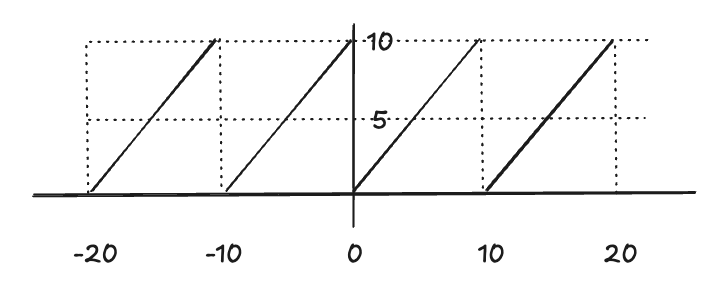
- 같은 입력값이면 항상 같은 결과값을 가진다
- 입력값이 다르면 왠만하면 다른 결과값을 갖고, 10마다 같은 결과값을 갖습니다.
- 입력값은 무한대이지만 결과값은 0~9 사이 정수입니다.
◎ 해시로 맵 만들기
해시 함수는 결과값이 항상 일정한 범위(개수)를 가집니다. 같은 입력에서는 같은 결과를 보장하고, 일정 범위에서 반복됩니다. 이러한 특징을 고려하면 범위와 같은 요소 개수를 갖는 배열이 적합합니다.
package main
const M = 10
func hash(d int) int {
return d % M
}
func main() {
var m [M]int{}
m[hash(23)] = 10 // 23, 10
m[hash(259)] = 50 // 259, 50
m[hash(33)] = 30 // 33, 30 -> 충돌
}
나머지 연산에 사용될 나누는 수를 설정하고 이 값을 배열의 크기로 지정합니다. 왜냐하면 해시 함수의 결과가 0 ~ 9 까지인 10개이기 때문입니다.
그런데 이렇게 예제로 간단히 만들어 본 맵은 해시 충돌이라는 치명적인 단점을 갖고 있습니다. 해시 함수는 다른 입력임에도 같은 결과를 낼 수 있습니다. 이에 대한 가장 단순한 해결 방법은 값이 아닌 리스트를 저장하는 것 입니다.
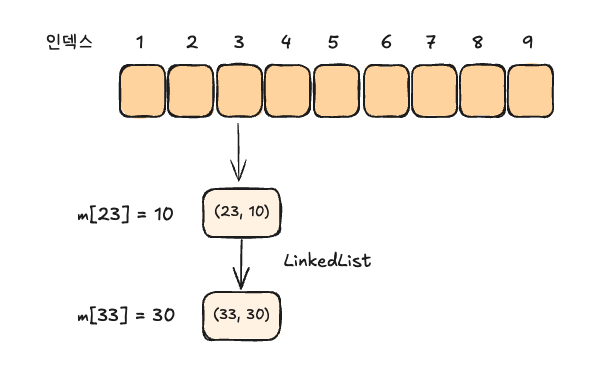
이렇게 리스트로 저장하면 기존 값을 보존할 수 있습니다. 따라서 값을 읽을 때 해당 인덱스에 링크된 모든 리스트를 조사해 매칭되는 키의 값을 반환하면 해시 충돌 문제에서 벗어나게 됩니다.
간단하게 맵의 동작 원리를 알아봤는데 실제로는 매우 복잡하고 다양한 해시 함수가 사용되며 암호화, 비트코인 등에서 광법위하게 사용되고 있습니다. 해시 함수는 요소 개수와 상관없이 고정된 시간을 갖는 함수이기 때문에 해시 함수를 이용하는 맵의 읽기, 쓰기에서 O(1)의 시간값을 갖게 됩니다. 또한 key 값이 크다고 함수 결과값이 커지는게 아니기 때문에 맵은 key와 무관하고 입력 순서와도 무관한 순서로 순회하게 됩니다.
정리하자면 배열은 인덱스만 알고 있다면 O(1)의 시간복잡도를 가지지만 인덱스가 0부터 시작하는 정수여야 하고, 미리 정해진 크기를 가지거나 동적 배열이더라도 연속된 메모리 공간을 요구한다는 제약이 있습니다. 그래서 맵에서는 해시 함수를 사용해 모든 키 값을 정수로 변환시키고, 이 정수를 배열의 인덱스로 매핑해서 값을 저장함으로써 문제를 해결한 것입니다.
즉, 맵은 배열을 일반적인 키(인덱스)로 접근하여 사용하고 싶다는 요구로부터 나오게 된 것입니다.
에러 핸들링
에러 반환
에러를 처리하는 가장 기본 방식은 에러를 반환하고 알맞게 처리하는 방식입니다. 예를 들어 ReadFile() 함수로 파일을 읽을 때 해당하는 파일이 없어 에러가 발생했다면, 이때 프로그램이 강제 종료되는 것보다는 적절한 메시지를 출력하고 다른 파일을 읽거나 임시 파일을 생성한다면 훨씬 사용자 경험이 좋을 것입니다.
func ReadFile(filename string) (string, error) {
file, err := os.Open(filename)
if err != nil {
return "", err
}
defer file.Close()
rd := bufio.NewReader(file)
line, _ := rd.ReadString('\n')
return line, nil
}
func WriteFile(filename string, line string) error {
file, err := os.Create(filename)
if err != nil {
return err
}
defer file.Close()
_, err = fmt.Fprintln(file, line)
return err
}
◎ 사용자 에러 반환
fmt 패키지와 errors 패키지에서 사용자 에러를 반환하는 함수를 제공하고 있습니다.
fmt.Errorf("format", a)
errors.New("message")Go 언어에서의 에러는 자바에서와 달리 프로그램을 종료시키면서 콜 스택(stack trace)를 보여주지 않습니다.
에러 타입(심화)
error는 사실 인터페이스로 문자열을 반환하는 Error() 메서드로 구성되어 있습니다.
type error interface {
Error() string
}
즉 어떤 타입이든 문자열을 반환하는 Error() 메서드를 포함하고 있다면 에러로 사용할 수 있습니다.
package main
type PasswordError struct {
Len int
RequireLen int
}
func (err passwordError) Error() string {
return "암호 길이가 짧습니다."
}
func RegisterAccount(name, password string) error {
if len(password) < 8 {
return PasswordError( len(password), 8 }
}
return nil
}
func main() {
err := RegisterAccount("myID", "myPw")
if err != nil {
if errInfo, ok := err.(PasswordError); ok {
//
}
} else {
//
}
}
때로는 발생한 에러를 추가적인 정보와 함께 감싸서 사용할 때도 있는데, 이 경우에는 아래의 코드처럼 Errorf() 함수의 %w 서식문자를 통해서 에러를 래핑할 수 있습니다. 그리고 래핑된 에러를 다시 꺼내올 때에는 errors.As() 함수를 사용합니다.
fmt.Errorf("message, Error: %w", err)
var pathErr *os.PathError
if errors.As(err, &pathErr) { }
패닉
패닉(panic)은 프로그램을 정상 진행시키기 어려운 상황을 만났을 때 프로그램 흐름을 중지시키는 기능입니다. Go언어는 내장 함수 panic()으로 패닉 기능을 제공합니다. 지금까지 error 인터페이스를 사용해 에러 처리를 하고, 호출자에게 에러가 발생한 이유를 알려줬습니다. 그런데 프로그램을 수행하다 보면 예기치 못한 에러에 직면하는데, 이 경우에는 프로그램을 강제 종료해서 문제를 빠르게 파악하는 편이 나을 수도 있습니다.
panic() 내장 함수를 호출하고 인수로 에러 메시지를 입력하면 프로그램을 즉시 종료하고 에러 메시지를 출력한 후 함수 호출 순서를 나타내는 콜 스택(call stack)을 표시합니다.
func panic(interface{})
panic(42)
panic("unreachable")
panic(fmt.Errorf("This is error num:%d", num))
panic(SomeType{SomeData})
panic() 내장 함수는 인수로 interface{} 타입 즉 모든 타입을 사용할 수 있습니다. 일반적으로는 string 타입 메시지나 fmt.Errorf() 함수로 만들어진 에러 타입을 주로 사용합니다.
복구
프로그램을 배포하고 난 뒤에는 문제가 발생하더라도 프로그램이 종료되는 대신 에러 메시지를 표시하고 복구를 시도하는 게 더 나은 선택일 수 있습니다. 예를 들어 게임을 하는데 게임이 시도 때도 없이 종료되면 사용자는 곧 바로 게임을 삭제할 겁니다.
panic은 호출 순서를 거슬러 올라가며 전파되는데 만약 함수 호출 과정이 main() -> f() -> g() -> h() 순이 었다면 패닉이 발생하면 그 역순으로 전파됩니다. 결국 최종적으로 main() 함수까지 패닉이 복구되지 않고 전파되면 프로그램이 그제서야 강제 종료되며, 어느 단계에서든 패닉이 복구되면 프로그램은 계속됩니다.
내장 함수 recover()는 함수가 호출되는 시점에 패닉이 전파 중이면 panic 객체를 반환하고 그렇지 않으면 nil을 반환합니다. 그리고 앞서 panic() 함수의 인수로 interface{} 타입 즉 모든 타입이 가능했듯이, 발생한 panic 객체를 반환하는 recover() 역시 interface{} 타입을 반환합니다. 그래서 recover()로 반환한 타입을 실제 사용하려면 아래와 같이 타입 검사를 해야 합니다.
func recover() interface{}
if r, ok := recover().(net.Error); ok {
//
}recover() 는 제한적으로 사용하는 것이 좋습니다. 패닉이 발생되면 그 즉시 호출 순서를 역순으로 전파하기 때문에 복구가 되더라도 프로그램이 불안정할 수 있습니다. 예를 들어 파일에 데이터를 쓰는 프로그램에서 데이터를 일부만 쓴 상태에서 패닉이 발생하고 다시 복구하면 데이터가 비정상적으로 저장된 상태로 남게 됩니다. 이럴 때는 그냥 복구하지 않거나 데이터가 비정상적으로 남아있지 않도록 확실히 지워줘야 합니다. 즉, 복구는 조심해서 사용해야 하며 복구가 되면 내부 상태를 깨끗하게 저일해서 다른 오류가 발생하지 않도록 해야 합니다.
'Lang > Go' 카테고리의 다른 글
| Go (7) - 테스트와 벤치마크, 웹 서버 (1) | 2025.04.17 |
|---|---|
| Go (6) - 고루틴과 동시성 프로그래밍, 채널과 컨텍스트, Generic (0) | 2025.04.17 |
| Go (4) - 슬라이스, 메서드, 인터페이스 (0) | 2025.04.13 |
| Go (3) - 배열, 구조체, 포인터, 문자열, 패키지 (1) | 2025.04.13 |
| Go (2) - If문, switch문, for문 (0) | 2025.04.13 |