

C 언어
C 언어의 탄생
C 언어는 1972년, 유닉스(UNIX) 시스템에 사용하기 위해 켄 톰슨(Ken Tompson)이 만든 B 언어를 데니스 리치(Dennis Ritchie)가 발전시켜 만든 언어입니다. 1969년에 개발된 초기 유닉스는 대부분 어셈블리어로 작성되어 컴퓨터의 하드웨어가 바뀌면 유닉스를 다시 개발해야 하는 문제가 있었습니다. 이런 불편을 해결하고자 데니스 리치는 하드웨어에 상관없이 사용할 수 있는 C 언어를 만들었습니다.
이러한 C 언어의 장점으로는 다음의 3가지가 있습니다.
- 하드웨어를 제어하는 시스템 프로그래밍이 가능합니다.
- 기종이 다른 컴퓨터에서도 올바르게 작동하는 이식성을 갖춘 프로그램을 만들 수 있습니다.
- 함수를 사용해 개별 프로그래밍이 가능합니다.
앞으로 학습할 C 언어는 1999년에 제정된 ISO/IEC 9899:1999 (C99) 표준을 기준으로 하겠습니다.
컴파일과 컴파일러
프로그램을 만들려면 먼저 소스 파일(source file)을 만들어야 하는데 이는 C 언어와 같은 프로그래밍 언어로 작성한 문서를 뜻합니다. 대부분의 프로그래밍 언어는 사람이 읽고 쓰는데 중점을 두었기에 컴퓨터는 이를 그대로 이해하지 못합니다. 컴퓨터는 0과 1로 된 특별한 신호인 기계어만을 이해하기 때문입니다. 따라서 소스 파일을 컴퓨터가 이해하는 언어, 다시 말해 기계어로 바꾸는 과정이 필요한데 이를 컴파일(compile)이라고 합니다.
컴파일은 컴파일러(compiler)라는 프로그램을 사용하여 수행하며, 컴파일러에는 다양한 종류가 있습니다. 컴파일 과정을 좀 더 자세히 살펴보면 다음과 같이 3단계(전처리, 컴파일, 링크)로 나눠집니다.
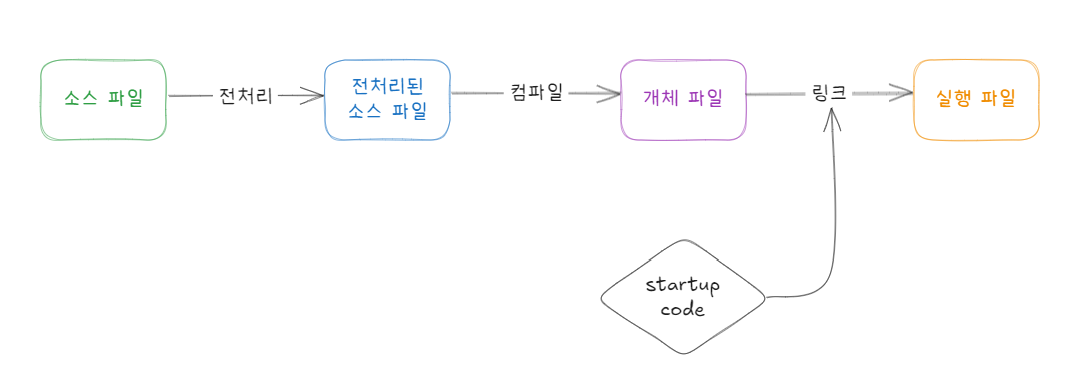
- 전처리(preprocess)과정은 전처리 지시자에 따라 소스 파일을 가공하는 과정입니다. 예를 들어 프로그램에 필요한 함수 중 외부에 있는 함수를 불러들이는 #include가 있습니다. 전처리 과정을 수행해도 파일의 형태는 달라지지 않습니다.
- 컴파일은 전처리가 끝난 소스 파일을 개체 파일(object file)로 만듭니다. 개체 파일은 CPU가 해석할 수 있는 명령어(instruction)들로 이루어진 기계어 파일이지만, 바로 실행하는 것은 불가능합니다. 프로그램은 운영체제에 의해서 실행되므로 개체 파일을 설치된 운영체제가 인식할 수 있는 형태의 실행 파일로 바꿔야 합니다.
- 링크는 컴파일된 개체 파일, 라이브러리, 그리고 startup code 를 하나의 실행 파일로 결합하는 과정입니다. startup code는 프로그램을 실행하기 전에 필요한 준비 작업을 수행하며 main 함수를 호출해 우리가 작성한 프로그램의 코드가 실행되도록 합니다.
상수
C 프로그램의 구조
C 프로그램은 함수로 만들어지며 함수는 일정한 기능을 수행하는 코드 단위를 의미합니다. 함수 중 main 함수는 프로그램의 시작을 의미하며 프로그램에 반드시 있어야 합니다.

main 함수는 머리(head)와 몸통(body)으로 구성됩니다. 머리는 함수 원형(function prototype)이라고 하며 함수의 이름과 필요한 데이터등을 표시합니다. 몸통에는 함수에서 실행할 일을 작성하며 마지막에는 return 0; 을 넣어 프로그램을 종료합니다.
화면에 데이터를 출력할 때는 다음과 같이 printf 함수를 사용할 수 있습니다. 이 함수는 print formatted라는 뜻을 가지며 일정한 형식에 따라 출력을 수행합니다.
참고로 JetBrain의 CLion을 IDE로 사용할 경우 한글 인코딩이 깨지는 문제가 발생할 수 있는데, 이때 모든 설정의 인코딩은 UTF-8로 하고, 해당 파일 하단의 인코딩만 직접 EUC-KR로 Convert 해주면 콘솔창에 제대로 출력됩니다.
#include <stdio.h> // stdio.h 파일의 내용을 프로그램 안에 복사
int main(void)
{
printf("Hello ");
printf("world");
return 0;
}1행에서의 stdio.h 는 standard input output(표준입출력)을 의미하며 여기에는 C 언어에서 기본으로 사용하는 입출력 함수가 들어있습니다.
제어 문자
제어 문자란 문자는 아니지만, 출력 방식에 영향을 주는 문자를 의미합니다. 제어 문자를 문자열 안에 포함시키면 그 기능에 따라 출력 형태를 바꿉니다. 이러한 제어 문자는 일반 문자와 구분하기 위해 백슬래시(\)와 함께 사용합니다.
printf("\n"); // new line
printf("\t"); // tab
printf("\b"); // backspace
printf("\r"); // carriage return (맨 앞으로 이동)
printf("\a"); // alert (경보 소리)
변환 문자
printf 함수는 기본적으로 문자열을 출력합니다. 따라서 숫자를 출력할 때는 변환 문자를 사용해서 문자열로 변환하는 과정이 필요합니다. 이 변환 문자는 데이터의 형태에 따라 달라지며, 정수는 %d(decimal), 실수는 %lf(long float)를 사용합니다.
printf("%d\n", 10); // 10
printf("%lf\n", 3.4); // 3.400000
printf("%.2lf\n", 3.455); // 3.462행의 %lf 의 경우 기본적으로 소수점 여섯째 자리까지 출력합니다.
3행의 %.2lf 의 경우 소수점 둘째 자리까지 출력하겠다는 의미로 소수점 셋째 자리에서 반올림을 하여 출력합니다.
상수와 데이터
프로그램은 일의 순서를 적은 것이며, 데이터는 프로그램이 처리하는 대상입니다. C 언어에서 다루는 데이터에는 정수, 실수, 문자, 문자열이 있습니다. 그리고 데이터의 형태로는 값을 바꿀 수 있는 변수와 바꿀 수 없는 상수 2가지가 있습니다.
그중 상수(constant)를 먼저 살펴보겠습니다.
정수 상수
정수 상수는 기본적으로 아라비아 숫자 0~9, +, - 기호를 사용합니다. 그리고 이를 3가지 진법, 10진수, 8진수, 16진수로 표현할 수 있습니다. 그런데 숫자만으로는 10진수인지 8진수인지를 구분할 수 없습니다. 수학에서는 밑수를 사용하여 표기하지만, 프로그래밍 언어에서는 밑수를 표기할 수 없기 때문에 숫자 앞에 8진수는 0(영), 16진수는 0x(영엑스)를 붙여 구분합니다.
참고로 컴퓨터는 모든 값을 2진수로 값을 저장하지만 2진수는 단위 숫자가 0과 1뿐이라서 표현 형태가 길어지므로 사람이 사용하기에는 비효율적이라 일반적으로 16진수를 사용하여 표기합니다.
실수 상수
실수는 소수점 형태와 지수 형태로 표현할 수 있습니다. 소수점 형태로 표현할 때 실수는 아라비아 숫자 0~9, +, - 기호와 소수점을 사용합니다. 그런데 이공계열에서 다루는 크고 작은 숫자는 지수 형태(지수 표기법)으로 표기합니다. 이러면 소수점 부분에서 무의미한 0이나 소수점은 생략할 수 있습니다.
(C 언어에서는 지수 표기법으로 나타낼 때 e 또는 E를 사용해 10의 거듭제곱을 표현하며, 예를 들어 1e3은 1 × 10³을, 1e-3은 1 × 10⁻³을 의미합니다.)

지수 형태를 지수 값의 크기에 따라 무수히 많은 방법으로 표현할 수 있습니다. 그중 소수점 앞에 0이 아닌 유효 숫자 한 자리를 사용해 지수 형태로 바꾼 것을 정규화 표기법이라고 합니다.
문자와 문자열
문자는 작은따옴표(' ')로 묶고, 문자열은 큰따옴표(" ")로 묶습니다. 문자와 문자열을 출력할 때는 각각 %c(character), %s(string) 변환 문자를 사용합니다. 물론 문자열은 변환 문자 없이도 바로 출력할 수 있습니다.
컴파일 후의 비트 형태
지금까지 정수, 실수, 문자, 문자열 상수에 대해 살펴보았습니다. IDE에 코드를 입력하면 이 코드는 모두 컴퓨터가 이해하는 형태의 이스키 코드 값으로 저장됩니다.

위 그림과 같이 모두 하나의 문자로 저장됩니다. 이것이 컴파일 과정이 없으면 코드가 컴퓨터에서 실행되지 않는 이유입니다. 컴퓨터에서는 +는 '덧셈을 하라'는 명령이 아니라 그저 '+' 문자이며, 10과 20도 연산이 가능한 값이 아니라 그냥 문자일 뿐입니다.
아스키(ASCII) 코드는 사람이 사용하는 문자와 기호를 컴퓨터에서 표현하기 위해 약속한 문자 인코딩 방식으로, 각 문자에 고유한 숫자를 할당한 것입니다. 원래 7bit(0~127)로 정의되어 있으며, 실제 컴퓨터에서는 1byte(8bit)를 사용해 저장합니다.
코드가 컴파일러를 거쳐 컴파일되어야 비로소 연산자는 명령어가 되고 상수는 연산이 가능한 형태로 바뀝니다. 상수는 종류에 따라 각기 다른 형태로 바뀝니다.
컴퓨터는 모든 데이터를 비트(bit)로 변환하는데, 1비트는 0과 1, 이렇게 2개의 값을 갖습니다. 비트가 8개면 이를 1바이트(byte)라고 하고 2^8 = 256 이니 1바이트의 값은 256가지입니다.
정수 상수를 컴파일하면 4바이트로 표현됩니다. 반면, 실수 상수는 8바이트로 표현됩니다.

정수 상수
먼저, 정수는 0을 포함한 양수와 음수로 나뉩니다.
컴퓨터에서 양수를 표현할 때는 정수를 2진수로 변환하여 표현하고, C 언어에서는 4바이트(32비트)의 크기로 표현하기 때문에 사용하지 않는 상위 비트는 0으로 채워집니다.
1바이트(8비트)로 표현할 수 있는 정수의 최댓값은 255이며, 4바이트(32비트)에서는 4294967295가 최대값입니다. 이보다 큰 상수를 사용하면 컴파일러는 해당 상수를 8바이트(long long)로 처리합니다. 값의 크기와 상관없이 8바이트 크기로 명시적으로 사용하고 싶다면, 상수 뒤에 LL 또는 ll 접미사를 붙여 사용합니다.
컴퓨터에서 음수를 표현할 때는 절대값을 2의 보수로 바꾸어 처리합니다. 2의 보수란 2진수의 0과 1을 바꾼 상태(1의 보수)에서 1을 더한 값을 말합니다.

음수를 2의 보수로 처리하는 이유는 특별한 변환 과정 없이 바로 양수와 음수를 더할 수 있기 때문입니다.

실제로 10과 -10의 모든 비트를 더하면 가장 왼쪽의 비트에서 자리 올림이 발생하고 남은 32비트는 모두 0이 되어 결과적으로 값 자체가 0이 됩니다. (정수는 4바이트이기 때문에 자리 올림된 상위 1비트는 버려지게 됩니다.)
Java와 달리 C에서는 int와 unsigned int로 구분됩니다.
int는 약 -21억부터 +21억까지의 범위를 가지며, unsigned int는 0부터 약 42억까지의 범위를 가집니다.
실수 상수
2진수로 값을 표현하는 방식은 값의 크기에 비례해 데이터의 크기도 커지므로 아주 큰 값이나 소수점 이하를 표현하는 데 한계가 있습니다. 따라서 데이터를 표현하는 효과적인 방법을 만들고 그 규칙에 따라 실수를 표현합니다.
실수의 경우 제한된 데이터 크기에 수를 표현하기 위해 IEEE 754 표준을 따릅니다. 이 표준에는 single, double, quad의 3가지 형식이 있는데, 그중 가장 많이 사용하는 double 형식만 간단히 살펴보겠습니다. double 형식은 실수를 8바이트, 즉 64비트로 표현하며 64비트는 다음과 같이 구성됩니다.

- 부호 비트: 가장 왼쪽 비트는 부호 비트이며 양수는 0, 음수는 1로 표시합니다.
- 지수부: 부호 비트 다음부터 11비트는 지수값을 의미합니다.
- 소수부: 나머지 52비트는 소수값을 의미합니다.
예를 들어, 숫자 10.0은 다음과 같이 표현할 수 있습니다.

부동소수점을 표현할 때는 실수를 2진수로 변환해 정규화된 형태인 1.xxxxxx × 2^n으로 나타냅니다. 이때 소수점 앞의 1은 정규화된 수에서는 항상 1이기 때문에, 저장 공간을 절약하기 위해 메모리에 따로 기록하지 않습니다. 이를 숨은 비트(Hidden Bit, Implicit Bit) 라고 하며, 이렇게 함으로써 저장 공간은 줄이면서도 정밀도는 유지할 수 있습니다.
또한 부동소수점 표현에서 지수는 음수도 표현해야 하지만, 지수부는 부호 없는 정수로 저장됩니다. 이를 위해 Bias(편향) 를 사용하여 지수에 일정한 값을 더해 양수로 만들어 저장합니다. 64비트(double) 부동소수점에서는 11비트의 지수부를 사용하며, Bias로 2^(11−1) −1 = 1023을 더해 저장합니다. 예를 들어 실제 지수가 0이라면 1023으로 저장하고, 실제 지수가 3이라면 1026으로 저장하여 음수 지수도 쉽게 표현할 수 있도록 합니다.
정수는 2의 보수로 음수를 표현하고, 실수는 부호 비트로 음수를 표현합니다.
+) 실수 상수의 오차
컴퓨터에서 실수 상수를 표현할 때는 유한한 비트로 값을 저장하기 때문에, 10진수를 2진수로 변환하는 과정에서 무한소수나 순환소수가 되는 값들은 정확하게 표현할 수 없으며 근사값으로 저장됩니다. 이로 인해 실수 연산 시 미세한 오차가 발생하고, 반복 연산이나 비교 연산을 할 때 주의가 필요합니다.
예를 들어 10진수 0.09는 2진수로 변환할 때 0.000111001...과 같이 끝없이 반복되는 순환소수가 되어 정확히 표현할 수 없기 때문에, 컴퓨터는 이를 유한한 비트로 근사해 저장하게 됩니다. 이러한 이유로 0.09를 사용하는 계산에서도 실제 메모리에는 근사값이 저장되어 연산 시 미세한 오차가 발생하게 됩니다.
문자 상수
문자 상수를 컴파일하면 2진수 형태의 아스키 코드 값으로 번역됩니다. 예를 들어 문자 'A'의 아스키 코드 값은 65이므로 정수 상수 65와 같은 형태로 번역됩니다.

결국 문자 상수는 소스 코드에서 문자임을 표현하는 방법이며, 컴퓨터 안에서는 정수와 같은 방식으로 처리됩니다.
변수
프로그램에서 데이터를 메모리에 저장해 놓으면 필요할 때마다 꺼내 사용할 수 있습니다. 이때 변수 선언을 통해 메모리에 저장 공간을 확보합니다. 변수는 데이터의 종류에 따라 각각 다른 형태를 사용하는데, 정수는 int, 실수는 double, 문자는 char, 문자열은 char 배열을 사용합니다.
변수 선언 방법
변수는 다음과 같이 데이터 종류에 맞는 자료형과 변수명을 나란히 쓰면 됩니다.
int a;정수를 넣을 공간으로 int를 사용합니다. 정수를 의미하는 영어 integer의 앞글자입니다. 이렇게 쓰면 정수를 저장할 공간을 a라 이름 붙여 메모리에 4바이트 할당하겠다고 컴파일러에 알려 주는 것과 같습니다. 변수명은 메모리에 붙이는 임시 주소와 같은 개념입니다.
변수를 선언하면 메모리에 저장 공간이 생기는데 처음 그 안에는 어떤 값이 들어 있을지는 알 수 없습니다. 컴퓨터의 메모리 공간은 재활용되기 때문에 프로그램이 종료되면 사용하던 메모리 공간을 반납하고 새로 실행된 프로그램이 그 공간을 사용합니다. 이때 종료된 프로그램이 어떤 값을 메모리 공간에 남겨 놓았는지는 알 수 없습니다. 새 프로그램에서 이 값은 의미가 없으므로 이를 쓰레기 값(garbage value)이라고 합니다. 자칫 이 쓰레기 값 때문에 프로그램에 오류가 생길 수 있으므로 반드시 원하는 값으로 바꾸는 초기화 과정이 필요합니다. 초기화 방법은 다음과 같습니다.
a = 10;이는 대입 연산자(=)를 사용하여 오른쪽 값을 왼쪽에 저장(할당)한다는 의미입니다.
변수 선언과 대입에는 4가지 규칙이 있습니다.
- 중괄호 블록({ }) 안에 변수를 선언하며 선언한 위치부터 블록 끝까지 사용할 수 있습니다.
- 변수의 자료형이 같으면 동시에 둘 이상의 변수를 선언할 수 있습니다.
- 대입 연산자는 연산자 왼쪽의 변수에 오른쪽의 값을 저장합니다.
- 변수는 대입 연산자 왼쪽(left-value)에서는 저장 공간이 되고, 오른쪽(right-value)에서는 값이 됩니다.
정수 자료형
같은 정수형이라고 메모리 저장 공간의 크기에 따라 char(1바이트), short(2바이트), int(2 or 4바이트), long(4 or 8바이트), long long(8바이트)으로 구분됩니다.
예를 들어 char형은 크기가 1바이트로 8비트입니다. 따라서 값의 저장 범위는 -128 ~ 127의 값을 저장할 수 있습니다. (0은 양수 범위에 포함되기 때문에 +127까지만 표현 가능합니다.)
int와 long 자료형은 컴파일러나 플랫폼에 따라 달라집니다.
일반적으로 int는 4바이트지만 간혹 2바이트로 구현된 컴파일러가 있는데, 이때 long 자료형을 사용할 수 있습니다.
만약 int와 long 자료형의 크기를 동일하게 인식하는 컴파일러를 사용한다면 long형을 쓸 필요가 없습니다.
(현재 사용하는 컴파일러에서 구현된 자료형의 크기는 sizeof 연산자로 확인할 수 있습니다.)
정수형은 보통 양수와 음수를 모두 저장하지만, 양수만 저장하면 두 배 더 넓은 범위의 값을 저장할 수 있습니다. 따라서 나이와 같이 음수가 없는 데이터를 저장할 때는 unsigned를 사용합니다.
unsigned 자료형을 사용할 때는 출력 시 변환 문자 사용에 주의해야 합니다. 다음 그림과 같이 unsigned 변수에 큰 양수를 저장하고 %d(decimal)로 출력하거나, 일반 자료형에 음수를 저장하고 %u(unsigned)로 출력하면 정상적으로 동작하지 않을 수 있습니다.

실수 자료형
실수는 데이터를 구현하는 방법이 정수와 다르므로 이를 표현할 때는 별도의 자료형을 사용합니다. 크기에 따라 float(4바이트/ 7개), double(8바이트/ 15개), long double(8바이트 이상/ 15개 이상)로 구별하며, 값을 저장할 수 있는 범위가 다릅니다. 실수 자료형의 경우 값이 범위보다 유효 숫자의 개수에 주목해야 합니다.
정수형 기본 자료형을 int를 사용하듯이, 실수형 기본 자료형은 double을 사용합니다.
문자열
문자열의 경우 char형을 배열 형태로 만들어 저장합니다.
char 배열명[문자열길이 + 1] = 문자열;문자열의 길이보다 배열의 크기를 하나 더 크게 설정하는 이유는 컴파일러가 문자열 끝에 널 문자(null character)인 \0을 자동으로 추가하기 때문입니다. 널 문자는 문자열의 끝을 표시하는 특별한 문자인데 이에 관해서는 추후에 알아보겠습니다. 이렇게 기본 자료형을 여러 개 묶어 사용하는 것을 배열(array)이라고 합니다.
배열에 새로운 문자열을 저장할 때에는 대입 연산자를 사용할 수 없습니다. 이에 관해서는 추후 배열에 관해 공부할 때 알아보겠습니다. 다음과 같이 배열에 초기화 이외에 문자열을 저장할 때에는 string copy라는 의미의 strcpy 함수를 사용합니다.
#include <stdio.h>
#include <string.h>
int main(void)
{
char fruit[20] = "strawberry";
printf("%s\n", fruit);
strcpy(fruit, "banana");
printf("%s\n", fruit);
return 0;
}
Const 변수
앞서 변수는 저장 공간이므로 언제든지 그 값을 바꿀 수 있다고 했습니다. 그러나 const를 사용한 변수는 예외입니다. 변수를 선언할 때 그 앞에 const를 붙이면 초기화된 값을 바꿀 수 없습니다.
const double tax_rate = 0.12;위와 같이 const를 사용하면 이후에는 값을 바꿀 수 없으므로 반드시 선언과 동시에 초기화해야 합니다. 초기화하지 않으면 변수의 쓰레기 값이 계속 사용되며, 만약 초기화 이후에 값을 바꾸고자 하면 컴파일 과정에서 에러가 발생하게 됩니다.
이런식으로 변수에 const를 사용하면 복잡한 값에 의미 있는 이름을 붙여 상수처럼 사용할 수 있습니다.
예약어와 식별자
예약어(reserved word)는 컴파일러와 사용 방법이 약속된 단어이며, 식별자(identifier)는 필요에 따라 만들어 사용하는 단어입니다. 예를 들어 변수 선언문에서 자료형 이름은 예약어이고, 변수명은 식별자입니다.
int age;
자료형 int는 정수를 저장할 메모리 공간을 확보하도록 지시하는 예약어이므로 단어를 마음대로 바꿀 수 없지만, 변수명 age는 확보한 저장 공간에 이름을 붙이는 것이므로 원하는 단어를 사용해 만들 수 있습니다. 식별자는 만들어 사용하는 단어이므로 다음 규칙만 지키면 어떤 것이든 사용할 수 있습니다.
- 알파벳 대문자 A~Z, 소문자 a~z, 숫자 0~9, _(밑줄)로 만듭니다.
- 숫자로 시작할 수 없습니다.
- 대문자와 소문자는 서로 다른 식별자로 인식합니다.
- 예약어는 식별자로 사용할 수 없습니다.
데이터 입력
키보드에서 타이핑하는 모든 내용은 문자로 인식됩니다. 따라서 입력한 데이터를 연산이 가능한 정수나 실수로 사용하려면 변환 과정이 필요합니다. 이때 사용하는 것이 바로 scanf 함수입니다. 이 함수는 입력 문자들을 스캔해 원하는 형태의 데이터로 바꿔 줍니다. 어떤 데이터로 변환할 것인지는 변환 문자를 통해 결정됩니다. scanf 함수에서 자료형에 따라 사용하는 변환 문자는 printf 함수로 출력할 때 사용하는 변환 문자와 거의 같습니다.
scanf 함수 사용법
scanf 함수는 키보드에서 입력한 값을 변수에 저장할 때 사용합니다. 사용법은 변수의 형태에 맞는 변환 문자를 사용하고 입력할 변수 앞에 &(ampersand)를 붙이면 됩니다.
#include <stdio.h>
int main(void)
{
int a;
scanf("%d", &a);
printf("입력된 값: %d\n", a);
return 0;
}이렇게 scanf 함수를 사용할 때에는 2가지 점을 유의해야 합니다.
- scanf 함수에서 변수명을 지정할 때는 &를 붙여야 합니다.
- scanf 함수에서 사용한 변환 문자와 맞는 형태의 데이터를 입력해야 합니다.
scanf 함수를 사용할 때 가장 많이 하는 실수는 변수명 앞에 &를 빠뜨리는 것입니다. 변수의 값을 출력할 때는 변수명만 사용하지만, 입력할 때는 변수명 앞에 &를 붙여야 합니다. &는 변수의 주소를 구하는 연산자로 포인터에 대해 학습할 때 자세히 알아보겠습니다.
scanf 연속 입력
다음과 같이 연속으로 데이터를 입력할 때에는 space bar, tab, enter 키를 눌러 값을 구분해야 합니다.
#include <stdio.h>
int main(void)
{
int age;
double height;
printf("나이와 키를 입력하세요: ");
scanf("%d%lf", &age, &height);
printf("나이는 %d살, 키는 %.1lfcm입니다\n", age, height);
return 0;
}
scanf 문자, 문자열 입력
char 형 변수에 문자를 입력할 때는 키보드로 입력하는 모든 문자가 대상이 됩니다. 즉, space bar(공백 문자)나 enter(개행 문자)도 하나의 문자로 전달됩니다.
문자열은 char 배열에 %s 변환 문자를 사용해 입력하는데, 문자열을 입력할 때는 배열명에 &를 붙이지 않습니다. 또한 스페이스나 엔터, 탭 등을 만나면 바로 전까지만 저장되므로 공백 없이 연속으로 입력해야 합니다.
#include <stdio.h>
int main(void)
{
char grade;
char name[20];
printf("학점 입력: ");
scanf("%c", &grade);
prinf("이름 입력: ");
scanf("%s", name);
prinf("%s의 학점은 %c입니다.\n", name, grade);
return 0;
}
scanf_s 함수
Visual Studio에서 사용하는 컴파일러인 cl compiler를 사용하는 경우 scanf 함수에서 다음과 같은 경고가 나옵니다.
Function 'scanf' is deprecated, reason: 'This function or variable may be unsafe. Consider using scanf_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.
이는 scanf가 배열의 크기를 확인하지 않아, 입력 시 배열의 크기를 초과하는 값이 들어가면 버퍼 오버플로우가 발생할 수 있어 안전하지 않기 때문이며, 이를 방지하기 위해 scanf_s 함수 사용을 권장한다는 의미입니다.
이러한 경고를 보지 않으려면 #define _CRT_SECURE_NO_WARNINGS를 선언하거나, 템플릿을 만들어 사용하는 것이 좋습니다.
'Lang > C' 카테고리의 다른 글
| C (6) - 문자와 문자열 (2) | 2025.08.18 |
|---|---|
| C (5) - 배열과 포인터 ② (2) | 2025.08.15 |
| C (4) - 배열과 포인터 ① (3) | 2025.08.11 |
| C (3) - 제어문과 함수 (4) | 2025.08.07 |
| C (2) - 연산자 (3) | 2025.08.03 |