

함수 정의와 호출
이번 글에서는 모든 프로그램에서 핵심이라 할 수 있는 함수 선언과 호출을 코틀린이 어떻게 개선했는지 살펴보겠습니다. 추가로 확장 함수와 프로퍼티를 사용해 혼합 언어 프로젝트에서 코틀린의 이점을 모두 살릴 수 있는 방법도 알아보겠습니다.
컬렉션
fun main() {
val set = setOf(1, 7, 53)
val list = listOf(1, 7, 53)
val map = mapOf(1 to "one", 7 to "seven", 53 to "fifty-three")
println(set.javaClass) // class java.util.LinkedHashSet
println(list.javaClass) // class java.util.Arrays$ArrayList
println(map.javaClass) // class java.util.LinkedHashMap
}위 코드에서 javaClass 는 자바의 getClass()에 해당하는 코틀린 표현입니다. 실행 결과에서 알 수 있는 것처럼 코틀린은 표준 자바 컬렉션 클래스를 사용합니다. 하지만 자바와 달리 코틀린 컬렉션 인터페이스의 디폴트는 읽기 전용입니다. 읽기 전용 인터페이스와 각각 대응하는 가변 인터페이스는 나중에 자세히 살펴보겠습니다.
코틀린 컬렉션은 자바 컬렉션과 똑같은 클래스이긴 하지만 코틀린에서는 자바보다 더 많은 기능을 쓸 수 있습니다. 예를 들어 리스트의 마지막 원소를 가져오거나 원소를 뒤섞은 버전을 얻거나, 컬렉션의 합계를 계산할 수 있습니다.
fun main() {
val strings = listOf("first", "second", "fourteenth")
strings.last()
strings.shuffled()
val numbers = setOf(1, 14, 2)
numbers.sum()
}이번 글에서는 이런 기능들이 어떻게 동작하는지 알아보고 자바 클래스에 없는 새로운 메서드들이 어디에서 비롯되었는지 살펴보겠습니다. 우선 last나 sum과 같은 함수를 어떻게 자바 컬렉션에 적용할 수 있는지 살펴보기 전에 함수 선언에 대한 새로운 개념을 살펴보겠습니다.
함수 호출
컬렉션의 모든 원소를 출력한다 가정하겠습니다. 자바 컬렉션에는 디폴트 toString 구현이 들어있지만, 그 디폴트 toString의 출력 형식은 고정돼 있고, 필요한 형식이 아닐 수도 있습니다.
fun main() {
val list = listOf(1, 2, 3)
println(list) // [1, 2, 3]
}만약 자바 프로젝트에서 디폴트 구현([1, 2, 3])과 달리 (1; 2; 3) 처럼 괄호로 둘러싸고 각 원소 사이를 세미콜론으로 구분하고 싶다면, 구아바(Guava)나 아파치 커먼즈(Apache Commons)같은 서드파티 프로젝트를 추가하거나 직접 관련 로직을 구현해야 합니다.
하지만 코틀린에서는 이런 요구 사항을 처리할 수 있는 함수가 표준 라이브러리에 이미 들어있습니다.
비교를 위해 우선 코틀린이 지원하는 기능들을 사용하지 않고 함수를 직접 구현해보겠습니다.
fun <T> joinToString(
collection: Collection<T>,
separator: String,
prefix: String,
postfix: String
): String {
val result = StringBuilder(prefix)
for ((index, element) in clollection.withIndex()) {
if (index > 0) result.append(separator)
result.append(element)
}
result.append(postfix)
return result.toString()
}위와 같이 제네릭 함수로 선언해서 작성할 수 있습니다.
이름 붙인 인자
위에서 만든 joinToString 함수를 호출해보겠습니다.
joinToString(collection, " ", " ", ".")호출한 코드만 보고 각 인자가 어떤 역할을 하는지 구분하기는 힘들어보입니다. 물론 함수 시그니처를 확인하거나 IDE의 도움을 받을 수 있겠지만, 함수 호출 코드 자체는 여전히 모호합니다. 이런 문제는 특히 인자로 Boolean 플래그(flag) 값을 전달해야 하는 경우에 흔히 발생합니다. 이를 해결하기 위해 일부 자바 코딩 스타일에서는 enum 타입을 사용하거나 주석을 달아놓으라고 합니다.
joinToString(
postfix = ".",
separator = " ",
collection = collection,
prefix = " "
)하지만 코틀린에서는 함수에 전달하는 인자의 일부 또는 전부에 이름을 명시할 수 있습니다. 심지어 전달하는 모든 인자에 이름을 지정하는 경우 전달하는 인자의 순서를 변경할 수도 있습니다.
디폴트 파라미터
자바에서는 일부 클래스에서 오버로딩(overloading)한 메서드가 너무 많아진다는 문제가 자주 발생합니다. 그 예로 java.lang.Thread는 8개의 생성자를 갖고 있습니다. 이 여러 개의 오버로딩 메서드들은 하위 호환성을 유지하거나 API 사용자에게 편의를 더하거나 등등 여러 이유로 만들어집니다. 하지만 어느 경우던지 중복이라는 결과는 같습니다. 그리고 인자 중 일부가 생략된 오버로드 함수를 호출할 때는 어떤 함수가 호출될지 모호한 경우가 생깁니다.
코틀린에서는 함수 선언에서 파라미터의 기본값을 지정할 수 있으므로 이런 오버로드 중 상당수를 피할 수 있습니다.
기본값을 사용해 joinToString 함수의 시그니처를 개선해보겠습니다.
fun <T> joinToString(
collection: Collection<T>,
separator: String = ", ",
prefix: String = "",
postfix: String = ""
): String위와 같이 정의하면 앞으로 함수를 호출 할 때 모든 인자를 쓸 수도 있고, 일부를 생략할 수도 있습니다. 또한 이름 붙인 인자를 사용할 때도 인자 목록 중간에 있는 인자를 생략하고, 지정하고 싶은 인자에 이름을 붙여서 순서와 관계없이 지정할 수도 있습니다.
@JvmOverLoads
자바에는 디폴트 파라미터라는 개념이 없어 기본값을 제공하는 코틀린 함수라도 자바에서 호출할 때는 모든 인자를 명시해야 합니다. 이때 조금 더 편하게 코틀린 함수를 호출하고 싶다면 @JvmOverLoads 어노테이션을 함수에 추가할 수 있습니다. 이 어노테이션을 추가하면 코틀린 컴파일러가 자동으로 맨 마지막 파라미터부터 하나씩 생략한 형태의 오버로딩 메서드를 추가해줍니다.
최상위 함수
객체지향 언어인 자바에서는 모든 코드를 클래스의 메서드로 작성해야만 합니다. 보통 그런 구조는 잘 작동하지만 실전에서는 어느 한 클래스에 포함시키기 어려운 코드가 많이 생깁니다. 어떤 연산은 두 개 이상의 클래스와 밀접하게 연관될 수 있고, 반대로 중요한 객체는 하나뿐이지만 그 연산을 해당 객체의 인스턴스 메서드로 넣으면 API가 불필요하게 비대해지는 문제도 발생할 수 있습니다.
그 결과 특별한 상태나 인스턴스 메서드가 없는 이른바 유틸리티 클래스가 생겨납니다. 이런 클래스는 다양한 정적 메서드(static method)를 모아두는 역할만 담당합니다. JDK의 Collections 클래스가 전형적인 예입니다.
하지만 코틀린에서는 이런 무의미한 클래스가 필요 없습니다. 대신 함수를 직접 소스 파일의 최상위 수준, 모든 다른 클래스의 밖에 위치시키면 됩니다. 그런 함수들은 여전히 그 파일의 맨 앞에 정의된 패키지의 멤버 함수이므로 다른 패키지에서 그 함수를 사용하고 싶을 때는 그 함수가 정의된 패키지를 임포트(import)해야만 합니다. 하지만 불필요한 유틸리티 클래스는 더 이상 존재하지 않습니다.
앞서 만들었던 joinToString 함수를 다음과 같이 strings 패키지의 join.kt 파일에 직접 넣어보겠습니다.
// join.kt
package strings
fun joinToString( ... ): String { ... }
JVM은 클래스 안에 들어있는 코드만을 실행할 수 있는데 이 함수가 어떻게 실행될 수 있을까요?
그 이유는 컴파일 과정에서 파일 이름의 새로운 클래스가 생성되고 최상위 함수가 정적 메서드로 선언되기 때문입니다.
위 파일을 컴파일한 결과를 자바로 작성하면 다음과 같습니다.
package strings;
public class JoinKt {
public static String joinToString( ... ) { ... }
}@file:JvmName(" ")
코틀린에서 최상위 함수를 정의하면, 컴파일러는 해당 함수를 담는 클래스를 자동으로 생성하는데, 기본적으로는 파일 이름 + Kt 접미사 형태로 클래스 이름을 만듭니다. 만약 코틀린 최상위 함수가 있는 클래스의 이름을 바꾸고 싶다면 파일 수준의 어노테이션을 추가합니다. 이 어노테이션은 파일의 맨 앞, 패키지 이름 선언 이전에 위치합니다.
최상위 프로퍼티
함수와 마찬가지로 프로퍼티도 파일 최상위 수준에 놓을 수 있습니다. 어떤 데이터를 클래스 밖에 위치시켜야 하는 경우는 흔치 않지만, 그래도 가끔 유용할 때가 있습니다. 또한 최상위 프로퍼티를 활용해 코드에서 상수를 정의할 수도 있습니다.
// property.kt
var opCount = 0
const val UNIX_LINE_SEPARATOR = "\n"
fun performOperation() {
opCount++
...
}위 코드는 다음의 자바 코드와 동등한 바이트코드를 만들어냅니다.
public class PropertyKt {
private static int opCount = 0; // + getter, setter
public static final String UNIX_LINE_SEPARATOR = "\n";
}다음과 같이 최상위 프로퍼티에 대해 정리할 수 있습니다.
- val (최상위) → private static 필드 + public static getter (var은 setter까지)
- const val (최상위) → public static final 필드
확장 함수와 학장 프로퍼티
기존 코드와 코틀린 코드를 자연스럽게 통합하는 것은 코틀린의 핵심 목표 중 하나입니다. 완전히 코틀린으로만 이뤄진 프로젝트조차도 JDK나 안드로이드 프레임워크 또는 다른 서드파티 프레임워크 등의 자바 라이브러리를 기반으로 만들어집니다. 또한 코틀린은 기존 자바 프로젝트에 통합하는 경우에는 코틀린으로 직접 변환할 수 없거나 미처 변환하지 못한 기존 자바 코드를 처리할 수 있어야 합니다. 이런 기존 자바 API를 재작성하지 않고도 사용할 수 있게 해주는 것이 확장 함수(extension function)입니다.
개념적으로 확장 함수는 단순합니다. 확장 함수는 어떤 클래스의 멤버 메서드인 것처럼 호출할 수 있지만 그 클래스 밖에 선언된 함수입니다.
예시로 어떤 문자열의 마지막 문자를 돌려주는 메서드를 작성해보겠습니다.

확장 함수는 이름 앞에 그 함수가 확장할 클래스의 이름을 덧붙이면 됩니다. 덧붙이는 클래스 이름을 수신 객체 타입(receiver type)이라 부르며, 확장 함수 호출 시 호출하는 대상 값을 수신 객체(receiver object)라고 부릅니다. 수신 객체는 수신 객체 타입의 인스턴스 객체입니다.
이 함수를 호출하는 구문은 일반적인 클래스 멤버를 호출하는 구문과 같습니다.
fun main() {
println("Kotlin".lastChar()) // n
}위 예제에서 String이 수신 객체 타입이고, "Kotlin"이 수신 객체입니다.
어떤 면에서 이는 String 클래스에 정적 메서드(static method)를 추가하는 것과 같습니다. 심지어는 String이 자바나 코틀린 등의 언어 중 어떤 것으로 쓰였는가는 중요하지 않습니다. 예를 들어 그루비(Groovy)와 같은 다른 JVM 언어로 작성된 클래스도 확장할 수 있고, final로 상속을 할 수 없는 클래스로 선언된 경우에도 가능합니다.

인스턴스 메서드 본문에서 this를 사용할 때와 마찬가지로 확장 함수 본문에도 this를 쓸 수 있습니다. 그리고 인스턴스 메서드와 마찬가지로 확장 함수 본문에서도 this를 생략할 수 있습니다. 또한 일반적인 인스턴스 메서드와 동일하게 함수 내부에서 수신 객체의 메서드나 프로퍼티를 바로 사용할 수 있습니다.
하지만 확장 함수가 캡슐화를 깨지는 않습니다. 클래스 안에서 정의한 메서드와 달리 확장 함수 안에서는 클래스 내부에서만 사용할 수 있는 private 멤버나 protected 멤버를 사용할 수는 없습니다.
함수를 호출하는 쪽에서는 확장 함수와 멤버 메서드를 구분할 수도 없고, 그 여부가 중요한 경우도 거의 없기 때문에 앞으로는 클래스의 멤버 메서드와 확장 함수를 모두 통틀어 '메서드'라고 부르겠습니다.
임포트와 확장 함수
확장 함수를 정의했다고 해도 자동으로 프로젝트 안의 모든 소스코드에서 그 함수를 쓸 수 있는 것은 아닙니다. 확장 함수를 쓰려면 다른 클래스나 함수나 마찬가지로 해당 함수를 임포트(import)해야 합니다. 이는 이름 충돌을 막기 위함입니다. 코틀린에서는 클래스를 임포트할 때와 같은 구문을 사용해 개별 함수를 임포트할 수 있습니다.
import strings.lastChar
val c = "Kotlin".lastChar()물론 *을 사용한 와일드카드 임포트도 동작합니다.
import strings.lastChar as last
val c = "Kotlin".last()as 키워드를 사용하면 임포트한 클래스나 함수를 다른 이름으로 부를 수 있습니다. as 키워드는 다른 여러 패키지에 이름이 같은 함수들이 많은 경우, 한 파일 안에서 그런 함수들을 써야할 때 별칭을 줘서 임포트하면 편리합니다.
자바에서의 확장 함수 호출
내부적으로 확장 함수는 수신 객체를 첫 번째 인자로 받는 정적 메서드(static method)입니다. 따라서 확장 함수를 호출해도 다른 어댑터(adapter) 객체나 실행 시점 부가 비용이 들지 않습니다. 이런 설계로 인해 자바에서 확장 함수를 사용하기도 편합니다. 단지 정적 메서드를 호출하면서 첫 번째 인자로 수신 객체를 넘기면 됩니다.
다른 최상위 함수와 마찬가지로 확장 함수가 들어있는 자바 클래스 이름도 확장 함수가 들어있는 파일 이름에 따라 결정됩니다. 따라서 확장 함수를 StringUtil.kt 파일에 정의했다면 다음과 같이 호출할 수 있습니다.
char c = StringUtilKt.lastChar("Java");이 확장 함수는 최상위 함수로 선언되어 정적 메서드로 컴파일되기 때문에 자바에서는 lastChar를 정적으로 임포트(static import)해서 단순히 lastChar("Java")라고 호출할 수도 있습니다.
유틸리티 함수 정의
이제 위에서 살펴본 확장 함수 기능을 사용해서 joinToString 함수를 컬렉션에 대한 확장 함수로 정의해보겠습니다.
fun <T> Collection<T>.joinToString(
separator: String = ", ",
prefix: String = "",
postfix: String = ""
): String {
val result = StringBuilder(prefix)
for ((index, element) in this.withIndex()) {
if (index > 0) result.append(separator)
result.append(element)
}
result.append(postfix)
return result.toString()
}이제 joinToString을 클래스의 멤버인 것처럼 호출할 수 있습니다.
fun main() {
val list = listOf(1, 2, 3)
println(list.joinToString(" ")) // 1 2 3
}
확장함수는 단지 정적 메서드 호출에 대한 문법적인 편의(syntatic sugar)일 뿐이기 때문에 클래스가 아닌 더 구체적인 타입을 수신 객체 타입으로 지정할 수도 있습니다.
예를 들어 문자열 컬렉션에 대해서만 호출할 수 있는 join 함수를 정의하고 싶다면 다음과 같이 할 수 있습니다.
fun Collection<String>.join(
separator: String = ", ",
prefix: String = "",
postfix: String = ""
) = joinToString(separator, prefix, postfix)
함장 함수의 오버라이드
코틀린의 메서드 오버라이드도 일반적인 객체지향의 메서드 오버라이드와 마찬가지입니다. 하지만 확장 함수는 오버라이드 할 수 없는데 이는 자바에서 정적 메서드(static method)를 오버라이드 할 수 없는 이유와 동일합니다.
class Parent {...}
class Child extends Parent {...}
public static void main(String[] args) {
Parent p = new Child();
p.instanceMethod(); // 인스턴스 메서드
Parent.staticMethod(); // 클래스 메서드 (정적 메서드)
}확장 함수는 정적 메서드인데, 정적 메서드는 인스턴스(객체)에 속한 메서드가 아닌 클래스에 속한 메서드입니다. 오버라이딩이란 '상속받은 인스턴스 메서드의 동작을 재정의'하는 것으로, 정적 메서드는 인스턴스와 무관하기 때문에 오버라이딩이 불가능합니다.
참고로 클래스 메서드와 확장 함수의 이름과 시그니처가 같다면 클래스 메서드가 더 높은 우선순위를 가집니다.
확장 프로퍼티
확장 함수와 마찬가지로 확장 프로퍼티를 사용하면 프로퍼티의 형식으로 클래스에 API를 추가할 수 있습니다. 하지만 프로퍼티라는 이름으로 불릴 뿐, 상태(값)를 저장할 방법이 없기 때문에 실제로 확장 프로퍼티는 아무 상태도 가질 수 없습니다. 따라서 확장 프로퍼티는 항상 커스텀 접근자(getter)를 정의합니다. 접근자를 호출할 때 함수 호출 문법 대신 프로퍼티 문법으로 더 짧게 코드를 작성할 수 있어서 편한 경우가 있습니다.
앞에서 정의한 lastChar() 라는 함수를 프로퍼티로 바꾸면 다음과 같습니다.

확장 함수의 경우와 마찬가지로 확장 프로퍼티도 단지 프로퍼티에 수신 객체 클래스가 추가됐을 뿐입니다. 뒷받침 필드(Backing Field)가 없어 기본 getter를 생성할 수 없으므로 반드시 커스텀 getter를 정의해야 합니다.
위에서 정의한 확장 프로퍼티는 다음과 같이 사용할 수 있습니다.
fun main() {
println("Kotlin".lastChar) // n
}
그리고 이 확장 프로퍼티를 자바에서 사용하고 싶다면, StringUtil.kt 라는 파일에 확장 프로퍼티를 정의했다고 가정했을 때 다음과 같이 호출해야 합니다.
StringUtilKt.getLastChar("Java");
컬렉션 처리 함수
이번에는 컬렉션을 처리할 때 쓸 수 있는 코틀린 표준 라이브러리 함수 몇 가지를 살펴보겠습니다.
자바 컬렉션 API 확장
앞에서 말했듯 코틀린 컬렉션은 자바와 같은 클래스를 사용하지만 더 확장된 API를 제공합니다. 이 API들은 모두 확장 함수로 정의되고 항상 코틀린 파일에서 디폴트로 임포트됩니다.
코틀린 표준 라이브러리는 수많은 확장 함수를 포함하므로 이들을 모두 알 필요는 없습니다. 컬렉션이나 다른 객체에 대해 사용할 수 있는 메서드나 함수가 무엇인지 궁금할 때마다 IDE의 코드 완성 기능을 통해 그런 메서드나 함수를 살펴볼 수 있습니다. IDE가 표시해주는 목록은 일반 함수와 확장 함수를 모두 포함합니다.
가변 인자 함수
다음과 같이 리스트를 생성하는 함수를 호출할 때 원하는 만큼 많이 원소를 전달할 수 있습니다.
val list = listOf(1, 2, 3, 4, 5)
표준 라이브러리에서 이 함수가 어떻게 정의되었는지 보면 다음과 같은 시그니처를 볼 수 있습니다.

이 함수는 호출할 때 원하는 개수만큼 여러 값을 인자로 넘기면 배열에 그 값들을 넣어주는 언어 기능인 가변 길이 인자(vararg)를 사용합니다. 코틀린의 가변 길이 인자도 자바와 비슷하지만 문법이 조금 다릅니다. 자바에서는 타입 뒤에 ...을 붙이지만, 코틀린에서는 파라미터 앞에 vararg 제어자를 붙입니다.
이미 배열에 들어있는 원소를 가변 길이 인자로 넘길 때도 코틀린과 자바 구문이 다릅니다. 자바에서는 배열을 그냥 넘기면 되지만, 코틀린에서는 배열을 명시적으로 풀어 배열의 각 원소가 인자로 전달되게 해야 합니다. 이런 기능을 스프레드(spread) 연산자(*)라고 합니다.
스프레드 연산은 다음 코드처럼 배열 앞에 *를 붙이기만 하면 됩니다.
val arr = arrayOf("second", "third", "fourth")
val list = listOf("first", *arr)위 예제는 스프레드 연산자를 통해 배열에 들어있는 값들과 다른 값도 함께 리스트에 넣을 수 있음을 보여줍니다.
중위 호출
맵을 만들때는 다음처럼 mapOf 함수를 사용합니다.
val map = mapOf("one" to 1, "two" to 2, "seven" to 7)여기서 사용되는 'to' 라는 단어는 코틀린 키워드가 아닙니다. 이 코드는 중위 호출(infix call)이라는 특별한 방식으로 to라는 확장 함수를 호출한 것입니다.
'중위(infix)'란 연산자나 함수가 피연산자(인자) 사이에 놓이는 표기법을 말합니다.
중위 호출 시에는 수신 객체 뒤에 메서드 이름을 위치시키고 그 뒤에 유일한 메서드 인자를 넣습니다.
다음 두 호출은 동일합니다.
"one".to(1)
"one" to 1
인자가 하나뿐인 멤버 함수나 확장 함수에만 중위 호출을 사용할 수 있습니다. 추가로 함수의 중위 호출 사용을 허용하고 싶으면 infix 제어자를 함수 선언 앞에 추가해야 합니다. 다음은 to 함수의 정의입니다.

이 to 함수는 Pair의 인스턴스를 반환합니다. Pair는 코틀린 표준 라이브러리 클래스로, 이름 그대로 두 원소로 이뤄진 순서쌍을 표현합니다.
다음과 같이 이 Pair 인스턴스를 갖고 두 변수를 동시에 초기화할 수도 있습니다.
val (number, name) = 1 to "one"이런 기능을 구조 분해 선언(destructuring declaration)이라고 부릅니다.
다음 그림으로 구조 분해가 어떻게 작동하는지 살펴보겠습니다.
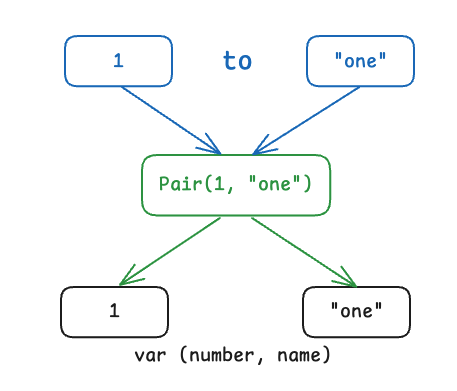
구조 분해는 순서쌍(Pair)에만 한정되지 않습니다. 예를 들어 map이나 루프에서도 구조 분해 선언을 활용할 수 있습니다.
val (key, value) = mapOf(1 to "one", 2 to "two")
for ((index, element) in collection.withIndex()) { ... }to 함수는 확장 함수로, to 함수를 사용하면 타입과 관계없이 임의의 순서쌍을 만들 수 있습니다.
이제 mapOf 함수의 시그니처를 살펴보겠습니다.

mapOf 함수는 키와 값으로 이루어진 Pair 객체들을 임의의 개수만큼 인자로 받아 맵을 생성한다는 것을 알 수 있습니다.
문자열과 정규식
코틀린 문자열은 자바 문자열과 똑같습니다. 코틀린 코드가 만들어낸 문자열을 아무 자바 메서드에 넘겨도 되며, 자바 코드에서 받은 문자열을 아무 코틀린 표준 라이브러리 함수에 전달해도 전혀 문제가 없습니다. 특별한 변환도 필요 없고 자바 문자열을 감싸는 별도의 래퍼(wrapper) 객체도 생기지 않습니다.
코틀린은 다양한 확장 함수를 제공함으로써 표준 자바 문자열을 더 즐겁게 다루게 해줍니다. 또한 혼동이 야기될 수 있는 일부 메서드에 대해 더 명확한 코틀린 확장 함수를 제공함으로써 프로그래머의 실수를 줄여줍니다. 두 API의 차이를 알아보겠습니다.
문자열 나누기
자주 사용하는 메서드로 String 클래스의 split 메서드가 있습니다.
String str = "12.345-6.A";
String[] arr = str.split(".");자바에서 위와 같은 코드가 있을 때 많은 개발자들이 arr 배열이 [12, 345-6, A] 이라고 생각하는 실수를 합니다. 하지만 실제로 arr은 빈 배열을 가집니다. 그 이유는 split은 정규식(regular expression)을 구분 문자열로 받아 그 정규식에 따라 문자열을 나누기 때문입니다. 정규식 표현에서 마침표(.)는 모든 문자를 나타내는 정규식으로 해석됩니다.
코틀린에서는 자바의 split 대신에 여러 가지 다른 조합의 파라미터를 받는 split 확장 함수를 제공함으로써 혼동을 야기하는 메서드를 감춥니다. 정규식을 파라미터로 받는 함수는 String 타입이 아닌 Regex 타입의 값을 받습니다. 따라서 코틀린에서는 split 함수에 전달하는 값의 타입에 따라 정규식이나 일반 텍스트 중 어느 것으로 문자열을 분리하는지 쉽게 알 수 있습니다.
val str: String = "12.345-6.A"
println(str.split("[-.]".toRegex())) // [12, 345, 6, A]
println(str.split(".")) // [12, 345-6, A]위 코드와 같이 코틀린에서는 toRegex 확장 함수를 사용해 문자열을 정규식으로 변환합니다.
하지만 이렇게 간단한 경우에는 꼭 정규식을 쓸 필요가 없습니다. split 확장 함수를 오버로딩한 버전 중에는 인자로 하나 이상의 구분 문자열을 받는 함수가 있습니다.
println(str.split("-", ".")) // [12, 345, 6, A]
substring
코틀린 표준 라이브러리에는 어떤 문자열에서 구분 문자열이 맨 마지막(또는 처음)에 나타난 곳 뒤(또는 앞)의 부분 문자열을 반환하는 함수가 있습니다.
- substringBefore()
- substringBeforeLast()
- substringAfter()
- substringAfterLast()
위 함수를 사용하면 정규식을 사용하지 않고 다음처럼 파일의 경로를 디렉터리, 파일 이름, 확장자로 쉽게 구분할 수 있습니다.
val path: String = "/Users/yole/kotlin-book/chapter.adoc"
val directory = path.substringBeforeLast("/")
val fullName = path.substringAfterLast("/")
val fileName = fullName.substringBeforeLast(".")
val extension = fullName.substringAfterLast(".")
Raw String과 정규식
문자열을 로우 문자열 리터럴(raw string)과 정규식을 사용해 구분할 수도 있습니다. (자바에서는 텍스트 블럭이라고 합니다.)
로우 문자열 리터럴에서는 백슬래시(\)를 포함한 어떤 문자도 이스케이프(escape)할 필요가 없습니다.
val path: String = "/Users/yole/kotlin-book/chapter.adoc"
val regex = """(.+)/(.+)\.(.+)""".toRegex()
val matchResult = regex.matchEntire(path)
if (matchResult != null) {
val (directory, filename, extension) = matchResult.destructured
}위 예제에서 쓴 정규식은 슬래시와 마침표를 기준으로 경로를 세 그룹으로 분리합니다.
마침표(.)는 임의의 문자 한 개를 의미하고, 더하기(+)는 앞의 패턴을 1회 이상 반복한다는 의미입니다. 즉, (.+) 은 아무 문자열을 뜻합니다.

정규식을 만들고 path에 매치하여 성공하면 그룹별로 분해한 매치 결과를 의미하는 destructured 프로퍼티를 구조 분해해 각 변수에 대입합니다.
trimIndent
로우 문자열 리터럴에서는 코드를 보기 좋게 하기 위해 넣은 줄 바꿈과 들여쓰기가 모두 포함됩니다. 이런 경우 trimIndent 함수를 호출하면 문자열의 최소 들여쓰기를 찾아 그만큼의 공백을 일괄 제거해줍니다. 또한 맨 첫 줄과 마지막 줄에 있는 불필요한 개행도 제거해줍니다.
val text = """
Line1
Line2
Line3
"""
println(text)
println(text.trimIndent())
파일에서 줄 끝을 표현하기 위해 운영체제마다 서로 다른 문자들을 사용합니다. 예를 들어 윈도우는 CRLF(\r\n), 리눅스와 맥OS는 LF(\n)를 사용합니다. 코틀린은 사용한 운영체제와 관계없이 모두 줄 끝으로 취급합니다.
프로그래밍 시 여러 줄 문자열이 요긴한 분야로는 테스트를 꼽을 수 있습니다. 테스트에서는 여러 줄의 텍스트 출력을 만들어내는 연산을 실행하고 그 결과를 예상 결과과 비교해야 하는 경우가 자주 있습니다. 이때 복잡하게 이스케이프를 쓰거나 외부 파일에서 텍스트를 불러올 필요가 없습니다. 단지 로우 문자열 리터럴에 HTML, XML, JSON 등의 텍스트를 넣고 trimIndent 확장 함수를 사용하면 됩니다.
+) Raw String Highlighting
인텔리제이 IDEA에서는 로우 문자열 리터럴 내부에 대해 문법 하이라이팅을 지원합니다. 하이라이팅은 다음과 같이 활성화 할 수 있습니다.
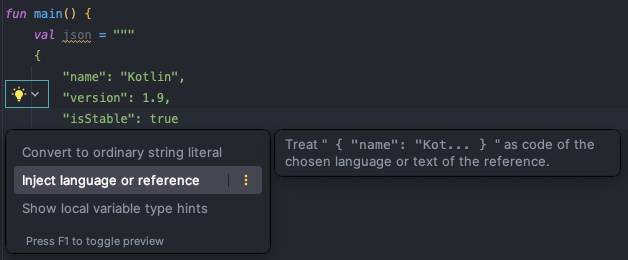


또는 항상 어떤 언어로 로우 문자열 리터럴을 주입하고 싶은 경우에는 @Language 어노테이션을 사용할 수 있습니다.

로컬 함수와 확장
많은 개발자가 좋은 코드의 중요한 특징 중 하나가 중복이 없는 것이라고 생각합니다. 심지어 이런 원칙에 대해 '반복하지 말라(DRY: Don't Repeat Yourself)' 라는 이름도 붙어 있을 정도입니다. 하지만 자바 코드를 작성할 때 DRY 원칙을 따르기는 쉽지 않습니다.
많은 경우 메서드 추출(Extract Method) 리팩터링을 적용해서 긴 메서드를 부분부분 나눠 각 부분을 재활용 할 수 있습니다. 하지만 그렇게 코드를 리팩터링하면 클래스 안에 작은 메서드가 많아지고, 각 메서드 사이의 관계를 파악하기 힘들어서 코드를 이해하기 더 어려워질 수도 있습니다.
여기서 리팩터링을 더 진행해서 추출한 메서드를 별도의 내부 클래스(inner class)안에 넣으면 코드를 깔끔하게 조직할 수는 있지만, 그에 따른 불필요한 준비 코드가 늘어납니다.
하지만 코틀린에는 더 깔끔한 해법이 있습니다. 코틀린에서는 함수에서 추출한 함수를 원래의 함수 내부에 내포시킬 수 있습니다. 그렇게 하면 문법적인 부가 비용을 들이지 않고도 깔끔하게 코드를 조직할 수 있습니다. 흔히 발생하는 코드 중복을 로컬 함수를 통해 어떻게 제거할 수 있는지 살펴보겠습니다.
class User(val id: Int, val name: String, val address: String)
fun saveUser(user: User) {
if (user.name.isEmpty()) {
throw IllegalArgumentException("Empty name")
}
if (user.address.isEmpty()) {
throw IllegalArgumentException("Empty address")
}
// 데이터베이스에 저장
}위와 같이 데이터베이스에 저장하는 함수가 있다고 가정해보겠습니다.
여기서는 코드 중복이 그리 많지는 않지만, 사용자의 필드를 검증할 때 필요한 경우를 모두 처리하는 큰 메서드를 원하지는 않을 것입니다.
이런 경우 검증 코드를 로컬 함수로 분리하면 중복을 없애는 동시에 코드 구조를 깔끔하게 유지할 수 있습니다.
또한 로컬 함수는 자신이 속한 바깥 함수의 모든 파라미터와 변수를 사용할 수 있습니다.
class User(val id: Int, val name: String, val address: String)
fun saveUser(user: User) {
fun validate(value: String,
fieldName: String) {
if (value.isEmpty()) {
throw IllegalArgumentException("Empty $fieldName, Id: ${user.id}")
}
}
validate(user.name, "name")
validate(user.address, "address")
// 데이터베이스에 저장
}
위 예제를 더 개선하고 싶다면 User 클래스를 확장한 함수로 만들 수 있습니다.
class User(val id: Int, val name: String, val address: String)
fun User.validateBeforeSave() {
fun validate(value: String,
fieldName: String) {
if (value.isEmpty()) {
throw IllegalArgumentException("Empty $fieldName, Id: ${id}")
}
}
validate(user.name, "name")
validate(user.address, "address")
}
fun saveUser(user: User) {
user.validateBeforeSave()
// 데이터베이스에 저장
}위와 같이 User 클래스의 확장 함수로 정의할 경우 User의 프로퍼티를 직접 사용할 수도 있습니다.
'Lang > Kotlin' 카테고리의 다른 글
| [Kotlin In Action] (2) - basics (0) | 2025.10.13 |
|---|---|
| [Kotlin In Action] (1) - what and why? (0) | 2025.10.09 |