

가상 쓰레드 (virtual thread)
자바는 오랫동안 널리 사용되면서 독점적인 지위를 누려왔지만, 그만큼 여러 진보된 새로운 기술로부터 많은 도전을 받기도 했습니다. 특히 자바의 성능에 있어서 개선 요구사항이 많았는데, 오라클은 이러한 요구사항을 반영하기 위해 부단히 노력해왔습니다.
그 결과로 JDK 9에서 새로운 방식의 가비지 컬렉터인 G1을 도입하면서 큰 개션이 있었고, JDK 21에서는 가상 쓰레드를 도입하면서 또 다른 눈에 띄는 개선을 달성하였습니다.
가상 쓰레드란?
가상 쓰레드는 기존의 쓰레드보다 가벼운 '경량 쓰레드(light thread)'입니다. 가볍다는 것은 더 적은 자원을 사용한다는 것을 의미하며, 기존의 쓰레드들보다 훨씬 더 많은 수의 가상 쓰레드를 생성할 수 있습니다. 그리고 가상 쓰레드는 이름에서 알 수 있듯이 '가짜(virtual)'입니다. 결국 실제로 작업을 처리하는 것은 진짜 쓰레드지만 가짜 쓰레드를 내세우는 것은 여러가지 장점이 있기 때문입니다.
이와 같은 특징을 제외하면 가상 쓰레드는 기존의 쓰레드와 별반 다르지 않습니다. 가상 쓰레드를 정의한 VirtualThread클래스는 기존의 Thread클래스를 확장한 것으로 최소한의 변경만으로 구현하는 것이 목표였습니다.

가운데의 BaseVirtualThread는 추상 클래스로 아래와 같이 단순히 park(), unpark(), parkNanos()를 정의하고 있을뿐입니다.
abstract sealed class BaseVirtualThread extends Thread
permits VirtualThread, ThreadBuilders.BoundVirtualThread {
BaseVirtualThread(String name, int characteristics, boolean bound) {
super(name, characteristics, bound);
}
abstract void park();
abstract void parkNanos(long var1);
abstract void unpark();
}위 메서드들은 뒤에서 자세히 살펴보겠습니다.
가상 쓰레드의 생성과 사용
가상 쓰레드와 구별하기 위해, 기존의 쓰레드를 '플랫폼 쓰레드(platform thread)'라고 부릅니다. 플랫폼 쓰레드를 생성하는 방법은 다음과 같습니다.
Runnable r = () -> { System.out.println("Hello"); };
Thread t = Thread.ofPlatform().start(r);
Thread t = new Thread(r).start();
여기서 ofPlatform() 대신 ofVirtual()을 사용하면 가상 쓰레드를 생성하고 실행할 수 있습니다.
Runnable r = () -> { System.out.println("Hello"); };
Thread t = Thread.ofVirtual().start(r);
가상 쓰레드의 특징
앞서 살펴본 것처럼 가상 쓰레드는 기존의 플랫폼 쓰레드와 생성과 사용 방법이 거의 같지만 몇 가지 차이점이 있습니다. 먼저 가상 쓰레드는 항상 데몬 쓰레드로만 가능합니다. 그래서 다음과 같이 일반 쓰레드로 실행하면 예외가 발생합니다.
vt.setDaemon(false); // Error: 'false' not legal for virtual threads
그리고 가상 쓰레드의 우선 순위는 항상 NORM_PRIORITY인 5로 고정되어 있습니다. 아래와 같이 가상 쓰레드의 우선 순위를 바꾸려고해도 에러만 나지 않을 뿐 변경되지 않습니다. 가상 쓰레드는 아주 많이 생성될 것을 가정하기 때문에, 이 많은 쓰레드의 우선순위를 관리하는 것이 어렵기만하고 별 효과가 없기 때문입니다.
vt.setPriority(10); // 동작 X
애초에 setPriority()의 내부를 보면 다음과 같이 가상 스레드가 아닐 때에만 우선 순위가 바뀌도록 작성되어 있습니다.
public final void setPriority(int newPriority) {
if (newPriority <= 10 && newPriority >= 1) {
if (!this.isVirtual()) {
this.priority(newPriority);
}
} else {
throw new IllegalArgumentException();
}
}이처럼 가상 쓰레드가 도입되면서 기존 쓰레드와 다른 부분은 if문을 이용해서 가상 쓰레드일 때는 다르게 동작하도록 작성되었습니다. 가상 쓰레드의 구현 목표가 기존 쓰레드를 대체가 아닌, 기존 쓰레드를 최소한으로 변경하면서 새로운 기능인 가상 쓰레드를 추가하기 위한 것이었기 때문입니다.
public static void main(String[] args) throws InterruptedException {
Runnable r = () -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("Hello");
};
Thread vt = Thread.ofVirtual().start(r);
System.out.println("Name: " + vt.getName());
System.out.println("Id: " + vt.threadId());
System.out.println("Group: " + vt.getThreadGroup());
System.out.println("Count: " + vt.getThreadGroup().activeCount());
vt.join();
}Name:
Id: 21
Group: java.lang.ThreadGroup[name=VirtualThreads,maxpri=10]
Count: 0
위 코드의 실행결과를 보면 가상 쓰레드는 기본적으로 이름이 없고, id만 부여됩니다. 이름이 필요하면 setName()으로 지정할 수는 있지만, 메모리 절약을 위해 보통 지정하지 않습니다. 가상 쓰레드는 수천만개 이상 생성할 수 있기 때문에 이름을 부여하지 않는 것만으로도 적지않은 메모리가 절약됩니다. threadId는 JDK 19부터 추가되었습니다.
그리고 가상 쓰레드의 쓰레드 그룹이 VirtualThreads인데, activeCount()가 1이 아니라 0입니다. 그 이유는 VirtualThreads 그룹은 명목상으로 존재할 뿐, 어떠한 쓰레드도 이 그룹에 속하지 않기 때문입니다. 가상 쓰레드는 아주 많이 생성할 수 있어서 그룹으로 다루는 것이 별 의미가 없고 관리하는데 부담만 되므로 그룹으로 묶어서 관리하지 않습니다.
플랫폼 쓰레드와 가상 쓰레드
플랫폼 쓰레드는 OS 쓰레드를 감싼 것으로 OS 쓰레드와 1:1로 연결됩니다. 그래서 플랫폼 쓰레드를 생성하면 OS로 요청이 전달되어 새로운 OS 쓰레드가 생성됩니다. 엄밀히 말하면 Thread객체를 생성하는 것은 단순히 자바 객체를 생성하는 것 뿐이고, start()를 호출해야 플랫폼 쓰레드가 생성됩니다. 아래는 Thread클래스의 start()의 내용입니다.
public void start() {
synchronized(this) {
if (this.holder.threadStatus != 0) {
throw new IllegalThreadStateException();
} else {
this.start0(); // native method
}
}
}
쓰레드의 상태가 NEW가 아닌 경우, 즉 이미 start()가 호출된 적이 있으면 예외를 발생시키고 그렇지 않으면 네이티브 메서드 start0()을 호출합니다. start0()은 다시 JVM_StartThread라는 네이티브 메서드를 호출하는데, 이 메서드가 OS의 라이브러리를 이용해서 OS 쓰레드를 생성하고 플랫폼 쓰레드와 연결합니다.
그렇기 때문에 쓰레드 객체를 만드는 시간은 비슷하나, 실행하는 시간에서는 많은 차이가 발생합니다.
다음 예제를 통해 쓰레드의 실행 시간을 비교해보겠습니다.
public static void main(String[] args) {
final int THREAD_COUNT = 10_000;
Thread[] thArr = new Thread[THREAD_COUNT];
long ptTime = startThread(thArr, false);
System.out.println("플랫폼 쓰레드: " + ptTime + " ms");
long vtTime = startThread(thArr, true);
System.out.println("가상 쓰레드: " + vtTime + " ms");
}
static long startThread(Thread[] thArr, boolean isVirtual) {
Runnable r = () -> {};
long start = System.currentTimeMillis();
for (int i = 0; i < thArr.length; i++) {
if (isVirtual)
thArr[i] = Thread.ofVirtual().start(r);
else
thArr[i] = Thread.ofPlatform().start(r);
}
long end = System.currentTimeMillis();
return end - start;
}플랫폼 쓰레드: 261 ms
가상 쓰레드: 12 ms
실행 결과를 보면 꽤 많은 차이가 나는 것을 알 수 있습니다. 플랫폼 쓰레드는 쓰레드의 start()를 호출하면, JVM이 OS에게 OS 쓰레드의 생성을 요청하기 때문에 시간이 많이 걸립니다. 즉 비용이 큽니다. 반면에 가상 쓰레드의 start()를 호출하면, OS에게 요청하지 않고 JVM내에 가짜 쓰레드를 생성하기 때문에 시간이 훨씬 적게 걸립니다. 다만 가상 쓰레드의 작업을 실제로 수행하는 것은 플랫폼 쓰레드이므로 코어의 개수만큼의 플랫폼 쓰레드도 함께 생성됩니다.
가상 쓰레드의 기본 스케줄러는 ForkJoinPool입니다.
다음 코드를 실행해보겠습니다.
public static void main(String[] args) {
int count = 0;
Runnable r = () -> {
try {
Thread.sleep(Integer.MAX_VALUE);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
};
try {
while (true) {
Thread.ofPlatform().start(r); // 플랫폼 쓰레드
if (++count % 1000 == 0)
System.out.println("count = " + count);
}
} catch (OutOfMemoryError error) {
error.printStackTrace();
}
System.out.println("max count = " + count);
}
이 예제는 최대로 생성할 수 있는 플랫폼 쓰레드의 수를 알아내기 위한 것이었습니다. 실행 결과에서 일 수 있듯이, 4074개를 생성하고 시스템 제한으로 종료되었습니다. 쓰레드마다 할당되는 기본 호출 스택의 사이즈는 2048K(2M)인데, 이 값은 실행시 옵션으로 변경할 수 있으며 이 값을 줄이면 생성할 수 있는 쓰레드의 수가 늘어납니다.
위 코드를 가상 쓰레드를 생성하도록 변경하고 실행해보겠습니다.
public static void main(String[] args) {
int count = 0;
Runnable r = () -> {
try {
Thread.sleep(Integer.MAX_VALUE);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
};
try {
while (true) {
Thread.ofVirtual().start(r); // 가상 쓰레드
if (++count % 1000 == 0)
System.out.println("count = " + count);
}
} catch (OutOfMemoryError error) {
error.printStackTrace();
}
System.out.println("max count = " + count);
}
동일한 환경에서 가상 쓰레드는 대략 1200만개를 생성할 수 있었습니다. 플랫폼 쓰레드의 개수보다 대략 3000배 정도 더 많은 숫자입니다. 이렇게 많은 수의 가상 쓰레드를 생성할 수 있는 이유는 플랫폼 쓰레드보다 더 적은 메모리를 사용하기 때문입니다.
플랫폼 쓰레드는 start()가 호출되면 쓰레드마다 호출 스택(2M)이 할당되지만, 가상 쓰레드는 고정된 OS 호출 스택이 필요없습니다. 대신 호출 스택의 내용을 임시로 저장할 공간은 필요한데, 이 공간은 아주 작은 크기의 메모리(4KB)인 '스택 청크(StackChunk)'를 필요한 개수만큼 생성해서 연결하는 구조이므로 호출 스택보다 훨씬 적은 메모리를 사용합니다. 게다가 종료된 가상 쓰레드가 사용하던 스택 청크를 재사용하기 때문에 메모리 할당과 제거에 걸리는 시간이 적습니다.
CPU-bound task vs I/O-bound task
단순히 쓰레드의 수가 많다고 작업이 빨리 끝나는 것은 아닙니다. CPU의 코어의 수는 쓰레드보다 훨씬 적기 때문에 쓰레드를 너무 많이 생성하면, 작업을 전환(컨텍스트 스위칭)하는 횟수가 늘어나서 오히려 작업을 완료하는데 시간이 더 걸릴 수도 있습니다.
주로 CPU를 집중적으로 이용하는 계산 위주의 작업(CPU instensive task), 즉 외부와 입출력의 횟수가 적은 작업은 컨텍스트 스위칭이 잦을 수록 작업 시간이 더 걸립니다. 그래서 이런 작업은 쓰레드의 개수를 적게, CPU의 코어 수와 비슷하게 생성해서 처리하는 것이 보통입니다.
이와 반대로 웹서버나 인터넷으로 대화를 주고 받는 메신저와 같은 프로그램은 작업의 대부분이 CPU는 적게 사용하면서 짧은 시간동안 빈번하게 단순히 데이터를 주고 받기 때문에 I/O 집중적인 작업(Input & Output intensive task)라고 합니다. 이런 작업은 I/O 블로킹이 자주 발생하며, 이때 CPU가 대기하게 됩니다. 따라서 입출력이 빈번한 경우, I/O 블로킹도 자주 발생하기 때문에 CPU라는 값비싼 자원을 낭비하지 않으려면 쓰레드의 개수가 아주 많아야 합니다. 그러나 플랫폼 쓰레드는 OS의 쓰레드와 일대일이므로 비용도 높고 생성할 수 있는 쓰레드의 개수가 제한적이어서 적합하지 않습니다.
쓰레드 풀을 이용해서 여러 개의 쓰레드를 미리 만들어 놓고 재사용하는 방법도 있으나, 이 방법은 쓰레드의 생성비용을 줄일 수 있을 뿐 많은 수의 쓰레드를 생성할 수 없다는 단점을 여전히 가지고 있습니다.
또 다른 방법은 소수의 플랫폼 쓰레드로 여러 작업을 비동기로 처리하는 것인데, 하나의 작업을 여러 쓰레드가 나눠서 처리하는 것이라 문제가 발생했을 때 원인을 추적하기 어렵다는 단점이 있습니다.
가상 쓰레드는 이러한 문제들을 해결해줍니다. 하나의 쓰레드가 작업을 시작부터 끝까지 전담하기 때문에 문제 해결이나 디버깅이 쉽습니다. 게다가 쓰레드를 많이 생성할 수 있고, 쓰레드 간의 작업 전환, 즉 컨텍스트 스위칭 비용도 낮습니다.
컨텍스트 스위칭
'컨텍스트 스위칭(context switching)'이란 말그대로 컨텍스트를 바꾸는 것입니다. 컨텍스트는 쓰레드가 작업을 수행하는데 필요한 정보를 의미하며, 쓰레드가 바뀌면 그에 맞게 컨텍스트도 같이 바뀌어야 합니다. 즉 현재 쓰레드가 사용하던 컨텍스트는 따로 저장해 놓고, 새로운 쓰레드를 위한 컨텍스트를 읽어와야 합니다. 이 과정에서 정보를 읽거나 쓰는 비용이 발생하며, 쓰레드가 많을 수록 컨텍스트 스위칭이 자주 발생해서 비용이 커집니다.
플랫폼 쓰레드는 컨텍스트 스위칭할 때 OS로의 요청, 즉 JVM의 외부로 요청해야 하므로, JVM 내부에서 컨텍스트 스위칭을 하는 가상 쓰레드보다 훨씬 많은 비용이 듭니다.
쓰레드는 Thread.sleep()을 만나면 진행중이던 작업을 중단하고 대기상태(TIMED_WAITING)가 되며 그 다음 차례의 쓰레드가 작업을 수행하는데, 이 과정에서 컨텍스트 스위칭이 발생합니다.
가상 쓰레드의 상태
플랫폼 쓰레드는 OS의 스케줄러가 관리하지만 가상 쓰레드는 JDK가 제공하는 스케줄러에 의해 스케줄링됩니다. 별도의 스케줄러를 지정하지 않으면 기본적으로 ForkJoinPool 스케줄러가 사용되는데, 이 스케줄러는 이름에서 알 수 있듯이 소수의 워커 쓰레드(플랫폼 쓰레드)를 미리 생성해놓고 재사용하는 쓰레드 풀입니다. 각 워커 쓰레드는 자신의 작업큐의 작업을 처리하는데, 앞서 fork & join 프레임워크에서 알아본 것처럼 work-stealing 방식으로 동작합니다.
final class VirtualThread extends BaseVirtualThread {
...
private static final ForkJoinPool DEFAULT_SCHEDULER = createDefaultScheduler();
...
}
가상 쓰레드가 시작되면, 가상 쓰레드의 작업이 ForkJoinPool 스케줄러에게 전달되고, 이 작업은 워커 쓰레드의 작업큐에 저장됩니다. 워커 쓰레드는 자신의 작업큐에 있는 작업을 꺼내서 처리합니다. 이 과정에서 가상 쓰레드의 상태가 변경되는데, 앞서 배운 플랫폼 쓰레드의 상태와 유사하지만 몇 개가 더 추가되었습니다.
private volatile int state;
private static final int NEW = 0;
private static final int STARTED = 1;
private static final int RUNNABLE = 2; // runnable-unmounted
private static final int RUNNING = 3; // runnable-mounted
private static final int PARKING = 4;
private static final int PARKED = 5; // unmounted
private static final int PINNED = 6; // mounted
private static final int YIELDING = 7; // Thread.yield
private static final int TERMINATED = 99; // final state
mount(), unmout()
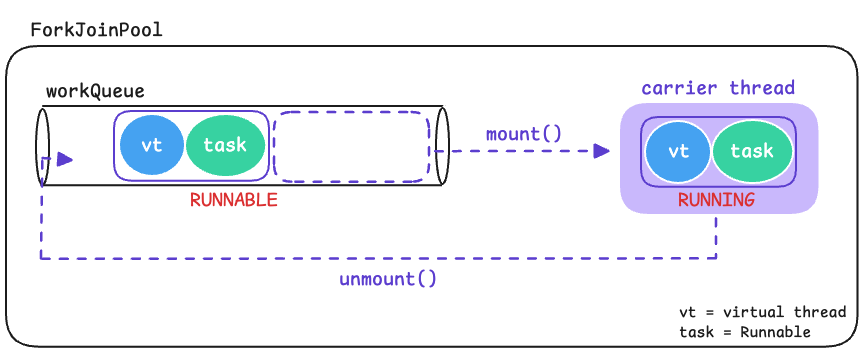
가상 쓰레드를 생성하고 시작하면 스케줄러의 워커 쓰레드(플랫폼 쓰레드) 중의 하나와 연결되는데, 이를 가상 쓰레드의 '캐리어(carrier) 쓰레드'라고 합니다. 그리고 가상 쓰레드의 상태는 실행가능(RUNNABLE)에서 실행중(RUNNING)으로 바뀝니다.
이때 캐리어 쓰레드에 가상 쓰레드를 연결하는 것을 마운팅(mounting), 분리하는 것을 언마운팅(unmounting)이라고 합니다.
private final Continuation cont;
private volatile Thread carrierThread;
private void mount() {
// sets the carrier thread
Thread carrier = Thread.currentCarrierThread();
setCarrierThread(carrier);
...
}가상 쓰레드의 작업을 실제로 처리하는 캐리어 쓰레드는 여러 가장 쓰레드의 작업을 번갈아 가며 처리합니다. 이것이 가능한 것은 컨티뉴에이션(continuation) 때문으로, 이는 작업을 중단했다가 나중에 다시 재개할 수 있게 해줍니다.
실행중(RUNNING)이던 가상 쓰레드에 yield()가 호출되면, unmount()가 호출되어 캐리어에서 분리되고 실행대기(RUNNABLE) 상태가 되고, 대기중이던 다른 가상 쓰레드가 캐리어와 연결됩니다.
park(), unpark()
이처럼 가상 쓰레드는 스케쥴러가 정한 스케쥴에 따라 실행과 실행대기를 반복하면서 작업을 처리합니다. 그러나 가상 쓰레드가 실행중에 작업을 계속할 수 없는 상황이되면, 캐리어로부터 분리되어야 하고 스케줄링 대상에서도 잠시 제외되어야 합니다.
park()는 가상 쓰레드를 스케쥴링 대상에서 제외시키고, 반대로 unpark()는 다시 스케줄링 대상으로 포함시킵니다.
아래는 Thread.sleep()의 일부로, 가상 쓰레드인 경우에 VirtualThread의 sleepNanos()를 호출합니다.
public static void sleep(long millis) throws InterruptedException {
...
try {
if (currentThread() instanceof VirtualThread vthread) {
vthread.sleepNanos(nanos);
} else {
sleep0(nanos);
}
}
...
}
그리고 sleepNanos()는 parkNanos()를 호출합니다. 이 메서드는 지정된 시간동안 가상 쓰레드를 스케줄 대상에서 제외된 상태(PARKED)로 만듭니다.
void sleepNanos(long nanos) throws InterruptedException {
...
while (remainingNanos > 0) {
parkNanos(remainingNanos);
...
}
}
스케줄링에서 제외된(PARKED) 상태의 가상 쓰레드는 지정된 시간이 지나거나 다시 작업을 재개할 상황이 되면, unpark()가 호출되어 다시 실행가능(RUNNABLE) 상태로 바뀌어 스케줄링 대상에 포함됩니다.
void parkNanos(long nanos) {
...
Future<?> unparker = scheduleUnpark(this::unpark, nanos);
...
}
가상 쓰레드가 작업을 진행할 수 없는 상황은 Thread클래스의 sleep(), join() 메서드와 Object클래스의 wait() 메서드, 그리고 I/O 블로킹 등이 발생한 경우입니다.

고정된(pinned) 가상 쓰레드
가상 쓰레드가 작업을 진행할 수 없는 상황일 때 park()가 호출되어 캐리어 쓰레드로부터 언마운트, 즉 분리되어야 합니다. 그런데 언마운트되지 않고 캐리어 쓰레드에 마운트된 상태로 유지되는 상황을 '가상 쓰레드의 고정(pinning)'이라고 합니다. 이때 가상 쓰레드는 캐리어 쓰레드에 마운트되어 있지만 작업이 멈춰있는 상태(mounted & pinned)가 됩니다.
가상 쓰레드의 고정이 발생하면, 캐리어 쓰레드에 다른 가상 쓰레드가 마운트될 수 없어서 사용할 수 있는 플랫폼 쓰레드의 개수가 줄어듭니다. 가변 크기의 쓰레드 풀을 사용하면 새로운 플랫폼 쓰레드가 생성되지만, 플랫폼 쓰레드는 비용이 크고 생성할 수 있는 개수의 제한이 있기 때문에 '가상 쓰레드의 고정 문제'를 해결해야 합니다.
public class Continuation {
...
/** Reason for pinning */
public enum Pinned {
/** Native frame on stack */ NATIVE,
/** Monitor held */ MONITOR,
/** In critical section */ CRITICAL_SECTION }
}Continuation클래스에 열거형 Pinned로 가상 쓰레드가 고정되는 이유가 정의되어 있습니다. 네이티브 메서드 내에서 I/O 블로킹이 발생하는 경우는 할 수 있는 일이 없지만, 나머지 2개 MONITOR와 CRITICAL_SECTION은 synchronized블럭 내에서 발생하는 것이기 때문에 다음과 같이 synchronized블럭을 ReentrantLock으로 변경하여 해결할 수 있습니다.
private static synchronized void syncMethod() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {}
}
private static void lockMethod() {
lock.lock()
try {
Thread.sleep(1000);
} catch (InterruptedException e) {}
lock.unlock();
}synchronized는 JVM이 관리하는 OS 수준의 모니터 기반 락이기 때문에, Continuation을 사용하여 언마운트가 불가능합니다.
주의사항
1. 가상 쓰레드 고정(pinning) 주의
위에서 살펴본 것과 같이 synchronized블럭을 사용하면 가상 쓰레드가 캐리어 쓰레드(플랫폼 쓰레드)에 고정되어 사용할 수 있는 캐리어 쓰레드의 수가 줄어듭니다. 가상 쓰레드가 고정되지 않게 synchronized 대신에 ReentrantLock을 사용해야 합니다.
2. ThreadLocal 사용 주의
ThreadLocal은 쓰레드마다 개별 저장공간을 제공해주는 유틸 클래스입니다. 락을 걸지 않고 저장공간을 사용할 수 있다는 것이 장점이지만, 변수를 사용하고 난 후에 직접 메모리를 해제해야하므로 메모리 누스가 발생할 수 있습니다. 가상 쓰레드는 아주 많이 생성할 수 있으므로 약간의 메모리 누수도 심각한 문제가 될 수 있습니다.
JDK 21부터 프리뷰 기능으로 추가된 ScopedValue는 ThreadLocal의 단점을 개선한 것으로 자동으로 메모리를 관리해주므로 가상 쓰레드와 같이 사용하기에 좋습니다.
| 항목 | ThreadLocal | ScopedValue |
| 목적 | 쓰레드의 개별 값 저장 | 쓰레드의 개별 값 저장 |
| 값의 변경 | 가능 | 불가능 |
| 값의 제거 | 수동 | 자동 |
| 메모리 | 수동 | 자동 |
| 자료구조 | HashMap | Stack |
| 읽기 성능 | 느림 | 빠름 |
3. 가상 쓰레드 풀링(pooling) 금지
쓰레드 풀링의 장점은 미리 생성해서 저장해놨다가 반복해서 재사용함으로써 생성시간을 절약하는 것인데, 가상 쓰레드는 생성비용이 플랫폼 쓰레드의 1/100정도이므로 필요할 때 생성해도 충분합니다. 게다가 많은 수의 가상 쓰레드를 풀링하려면, 이들을 관리하기 위한 저장공간이 커야하므로 비용이 많이 듭니다. 그래서 가상 쓰레드를 풀링하기보다는 일회용으로 필요할 때마다 생성해서 사용하는 것이 낫습니다.
만약 쓰레드 풀의 크기를 고정시킴으로써 공유 자원에 요청이 갑자기 몰리는 것을 막기 위한 용도로 쓰려면, 쓰레드 풀 대신에 세마포어(semaphore)를 사용합니다. 세마포어는 공유 자원을 동시에 사용할 수 있는 쓰레드의 수를 제어할 수 있습니다.
Continuation과 StackChunk
플랫폼 쓰레드가 여러 가상 쓰레드를 번갈아가면서 실행할 수 있는 이유는 가상 쓰레드의 작업을 중단할 수 있고, 작업 진행 상황(호출 스택)을 저장할 수 있기 때문입니다. 이를 가능하게 하는 것이 컨티뉴에이션(Continuation)과 스택청크(StackChunk)입니다.
컨티뉴에이션은 가상 쓰레드와 작업을 하나로 묶은 것으로 실행을 중단했다가 다시 재개하는 것이 가능하고, 스택청크는 중단할 때 진행중이던 작업의 진행 상황, 즉 호출스택의 내용을 저장하는데 사용합니다. 스택청크에 저장된 내용은 나중에 중단되었던 작업이 재개될 때 다시 호출스택으로 복사됩니다.

호출스택의 내용을 하나의 스택청크에 담을 수 없을 때는 새로운 스택청크를 생성해서 연결합니다. 스택청크의 생성시간을 절약하기 위해 이미 종료된 작업에서 사용했던 스택청크를 재사용합니다.
아래는 StackChunk클래스의 실제 코드인데, 호출스택의 정보를 저장하기 위한 인스턴스 변수가 몇개 없습니다. 그 이유는 C++로 구현된 진짜 StackChunk를 자바에서 사용할 수 있게 작성한 껍데기 클래스이기 때문입니다.
public final class StackChunk {
private StackChunk parent; // 이전 StackChunk
private int size;
private int sp;
private int argsize;
...
}
Continuation과 Coroutine

일반적으로는 위 그림처럼 routine()이 subroutine()을 호출하면, subroutine()은 종료될 때까지 수행을 멈출 수 없고, 수행이 종료되어야 routine()으로 되돌아갑니다.

반면에 코루틴(coroutine)은 위 그림처럼 수행을 중단했다가 다시 수행하기를 반복할 수 있습니다. 코루틴은 이미 오래전부터 여러 언어에서 구현되어 사용해 왔으며, 코루틴을 자바에서 구현한 것이 Continuation입니다.
Continuation은 jdk.internal.vm 패키지의 클래스로 안정성·호환성·보안 리스크가 크기 때문에 공식 API로 제공되지는 않고, 가상 쓰레드 내부 구현용으로만 사용됩니다.
다음은 Continuation의 실제 코드인데, 수행할 작업과 호출스택을 저장할 스택청크 그리고 작업의 진행 상태를 저장하기 위한 변수들이 선언되어 있습니다.
public class Continuation {
private final Runnable target;
private StackChunk tail;
private boolean done;
private boolean preempted;
private volatile boolean mounted;
...
}
아래의 코드를 보면 VirtualThread는 Continutaion을 포함하고 있으며, Continuation은 가상 쓰레드와 작업을 함께 묶은 것이라는 것을 확인할 수 있습니다.
final class VirtualThread extends BaseVirtualThread {
private final Continuation cont;
private final Runnable runContinuation;
VirtualThread(Executor scheduler, String name, int characteristics, Runnable task) {
...
this.scheduler = (Executor)scheduler;
this.cont = new VThreadContinuation(this, task);
this.runContinuation = this::runContinuation;
}
...
}
VirtualThread의 인스턴스 변수 runContinuation은 Continuation을 Runnable로 감싼 것으로 메서드 참조로 작성되어 있습니다.
기존의 쓰레드, 즉 플랫폼 쓰레드는 작업을 Runnable로 다루기 때문에 가상 쓰레드의 작업인 Continuation을 Runnable로 감싸는 것입니다. 이렇게 함으로써 기존의 코드를 변경없이 재사용할 수 있습니다.
가상 쓰레드를 시작하면, 즉 start()를 호출하면 스케줄러에 가상 쓰레드의 작업이 전달되고 스케줄러의 워커 쓰레드(플랫폼 쓰레드) 중의 하나와 연결됩니다. 연결된 워커 쓰레드는 cont.run()을 호출하여 이 작업을 시작합니다.

Continuation의 중단과 재개
수행중이던 작업이 중단될 수 있는 이유는 가상 쓰레드의 작업을 Continuation으로 처리하기 때문인데, Continuation은 run()으로 시작해서 yield()를 호출하면 작업이 일시적으로 중단됩니다. Continuation의 yield()는 직접 호출하거나 작업을 진행할 수 없는 경우에 간접적으로 호출됩니다.
- 명시적 중단: 직접 Continuation.yield() 호출
- 간접적 중단(대기상황 발생): I/O 블로킹, 락의 획득, Thread.sleep() 호출
Continuation의 yield()가 호출되면, 진행중이던 작업이 중단되고 호출스택의 내용은 스택청크에 저장됩니다. 그리고 중단된 Continuation을 포함한 가상 쓰레드는 캐리어 쓰레드(플랫폼 쓰레드)로부터 언마운트됩니다.
중단된 Continuation은 작업을 재개할 수 있는 상황이되면 Continuation의 run()이 직간접적으로 호출되어 실행가능한 상태(RUNNABLE)가 됩니다. 이 상태의 가상 쓰레드는 스케줄러가 정한 스케줄에 의해 적절한 시점에 다시 비어있는 캐리어 쓰레드에 마운트되고, 중단했을 때 저장해두었던 스택청크의 내용을 이 캐리어 쓰레드의 호출스택에 다시 복사해서 중단되었던 지점부터 실행이 재개됩니다.
Executor와 ExecutorService
Executor인터페이스는 쓰레드가 수행할 작업의 처리를 추상화한 것입니다. 그리고 이를 보다 발전시킨 것이 ExecutorService인터페이스입니다. Executor클래스를 통해 자주 사용되는 여러 종류의 ExecutorService의 구현체가 제공되므로 직접 구현할 일은 거의 없습니다.
Executor는 JDK 5부터, ExecutorService는 JDK 8부터 java.util.concurrent패키지에 포함되었습니다.
Executor
쓰레드로 작업을 처리할 때, 먼저 쓰레드로 수행할 작업을 적고 그 다음에 어떻게 쓰레드를 생성하고 실행할 것인지 두 단계로 코드를 작성하는 것이 보통입니다.
// 1. 쓰레드가 수행할 작업을 작성
Runnable r = new Runnable() {};
// 2. 쓰레드의 생성과 실행
Thread t = new Thread(r);
t.start();
쓰레드로 수행할 작업을 작성하는 코드는 매번 달라지겠지만, 쓰레드를 생성하고 실행하는 코드는 거의 달라지지 않습니다. 달라진다 해도 그저 몇가지 패턴이 반복될 뿐입니다. 이러한 패턴을 미리 작성해 놓고, 재사용하기 위한 것이 바로 Executor입니다.
public interface Executor {
void execute(Runnable task);
}
Executor로 데몬 쓰레드를 생성하는 DaemonExecutor를 정의하고 실행하는 예제입니다.
class EaemonExcutor implements Executor {
public void execute(Runnable r) {
Thread th = new Thread(r);
th.setDaemon(true);
th.start();
}
}
public static void main(String[] args) {
Runnable r = new Runnable() { };
DaemonExecutor executor = new DaemonExecutor();
executor.execute(r);
}코드가 워낙 간단해서 별차이가 없지만, 생성할 쓰레드의 개수가 많거나 좀더 복잡한 상황에서는 분명한 차이가 있습니다. 그리고 자주 사용될만한 Executor를 종류별로 만들어 놓으면, 상황에 따라 필요한 것을 선택만 하면되니까 코드가 간단해지고 재사용성이 높아집니다.
ThreadFactory
Executor가 쓰레드의 생성과 실행을 같이 처리하기도 하지만, 생성과 실행은 별도의 작업이므로 분리하는 것이 코드의 재사용이나 유지보수에 더 유리합니다. 이럴 때 사용하는 것이 '쓰레드 팩토리' 입니다. 쓰레드의 생성은 쓰레드 팩토리에게 맡기고, Executor는 쓰레드를 어떻게 실행할 것인가에만 전념하면 됩니다.
쓰레드 팩토리는 ThreadFactory인터페이스로 정의되어 있으며, 쓰레드를 생성해서 반환하는 팩토리 메서드 하나만 갖고 있습니다.
public interface ThreadFactory {
Thread newThread(Runnable r);
}
쓰레드를 생성할 때 생성자 대신 팩토리 메서드를 사용하면, 변경에 유리할 뿐만아니라 객체를 재사용할 수 있는 등 여러가지 이점을 얻게 됩니다. 예를 들어 플랫폼 쓰레드를 생성해서 반환하는 ThreadFactory는 다음과 같이 작성할 수 있습니다.
class PlatformThreadFactory implements ThreadFactory {
public Thread newThread(Runnable r) {
Thread th = new Thread(r);
th.setName("platform-" + th.threadId());
return th;
}
}
class EaemonExcutor implements Executor {
private ThreadFactory factory;
DaemonExecutor(ThreadFactory factory) {
this.factory = factory;
}
public void execute(Runnable r) {
Thread th = factory.newThread(r);
th.setDaemon(true);
th.start();
}
}
public static void main(String[] args) {
Runnable r = new Runnable() {};
ThreadFacotry factory = new PlatformThreadFactory();
Executor executor = new DaemonExecutor(factory);
executor.execute(r);
}
ExecutorService
Executor로 코드를 간단히 하고 재사용하는 것은 좋은데, 기능적으로 좀 아쉬움이 있습니다. 그래서 나온 것이 ExecutorService입니다. ExecutorService는 Executor를 확장한 것으로 더 많은 기능이 추가되었습니다.
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
execute()는 Runnable만 실행할 수 있지만, submit()은 Callable도 가능하므로 반환값이 있는 작업을 실행할 수 있습니다. 그리고 Runnable의 run()은 예외가 선언되어 있지 않아서 RuntimeException의 자손 예외만 던질 수 있는데 Callable의 call()은 Exception이 선언되어 있어서 모든 종류의 예외를 던질 수 있습니다.
@FunctionalInterface
public interface Runnable {
void run();
}
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}
ExecutorService는 submit()외에도 invokeAny()와 invokeAll()이 있는데, 이들은 여러 작업이 담긴 컬렉션을 받아서 한 번에 처리할 수 있으며, 큰 작업을 작게 나눠서 여러 쓰레드가 병렬로 처리하게 할 때 사용합니다.
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
invokeAny()는 여러 작업 중에 예외 발생없이 가장 먼저 완료된 작업의 결과를 반환하고, 완료되지 않은 나머지 작업은 취소합니다. 다만 곧바로 취소되지 않고 시간이 걸릴 수 있습니다.
반면에 invokeAll()은 모든 작업이 완료되었을 때, 각 작업에 대한 결과가 담긴 List<Future>를 반환합니다. 작업의 수행 중에 예외가 발생해도 작업이 끝난 것으로 간주됩니다.
예를 들어 invokeAny()는 많은 데이터에서 원하는 데이터 하나만을 찾을 때, invokeAll()은 큰 이미지 파일을 여러개로 나눠서 여러 쓰레드가 동시에 빠르게 처리할 때 유용합니다.
ExecutorService 종료
다음은 ExecutorService의 종료와 관련된 메서드들입니다.
boolean isTerminated() // 모든 작업이 종료되었으면 true
boolean isShutdown() // ExecutorService가 종료되었으면 true
void shutdown() // 모든 작업이 완료될때까지 기다렸다가 종료
List<Runnable> shutdownNow() // 모든 작업을 중단하고 종료, 미완료 작업 반환
boolean awaitTermination(long timeout, TineUnit unit) // 지정된 시간동안 대기 후 작업 종료여부 반환
shutdown()은 제출된 모든 작업이 끝날때까지 기다렸다가 ExecutorService를 종료합니다. 지정된 시간동안만 기다리다가 강제종료를 하려면 awaitTermination()과 shutdownNow()를 호출하면 됩니다.
// 종료
executorService.shutdown();
// 강제 종료
if (!executorService.awaitTermination(5, TimeUnit.SECONDS)) {
executorService.showdownNow();
}shutdownNow()는 작업 중인 쓰레드에 대해 interrupt()를 호출하는 것뿐이기 때문에 쓰레드의 작업이 interrupt가 발생했을 때 중단될 수 있게 작성되어 있어야 합니다.
ExecutorService 생성
자주 사용될만한 Executor는 이미 만들어져, Executors클래스로 제공됩니다.
// 하나의 쓰레드만 생성하여 모든 작업을 처리
public static ExecutorService newSingleThreadExecutor()
// 작업의 수만큼 플랫폼 쓰레드를 생성 (쓰레드 재사용 X)
public static ExecutorService newThreadPerTaskExecutor(ThreadFactory threadFactory)
// 작업의 수만큼 가상 쓰레드를 생성 (쓰레드 재사용 X)
public static ExecutorService newVirtualThreadPerTaskExecutor()한 가지 주의할 점은 작업을 모두 제출한 후에 반드시 shutdown()을 호출해야 한다는 것입니다. 그렇지 않으면 Executor는 다음 작업의 제출(submit)을 계속 기다리므로 프로그램은 종료되지 않습니다.
public static void main(String[] args) {
ExecutorService executor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 5; i++) {
final int no = i;
executor.submit(() -> System.out.println("No." + i));
}
executor.shutdown(); // 종료
}shutdown()을 호출해도 바로 Executor가 종료되는 것이 아니고, 이미 제출된 작업이 모두 완료될 때까지 기다린 후에 종료됩니다.
try (ExecutorService executor = Executors.newSingleThreadExecutor()) {
for (int i = 0; i < 5; i++) {
final int no = i;
executor.submit(() -> System.out.println("No." + i));
}
}또는 ExecutorService가 AutoCloseable을 상속받으며, close()에서 shutdown()을 호출하도록 구현했기 때문에, try-with-resources구문을 사용해서 처리해도 됩니다.
쓰레드 풀(thread pool)
쓰레드 풀(thread pool)은 미리 여러 개의 쓰레드를 만들어놨다가 작업(task)이 들어오면 순서대로 작업큐에 저장되고 대기중이던 쓰레드가 작업 큐에서 작업을 하나씩 꺼내서 처리하는 방식입니다.

쓰레드 풀의 장점은 미리 쓰레드를 생성해 놓고 재사용하기 때문에 쓰레드가 생성되고 시작하는 시간을 줄일 수 있습니다. 작업의 크기가 작고 요청의 수가 많은 경우 쓰레드 풀이 적합합니다. 일반적인 쓰레드 풀의 동작방식은 위 그림과 같지만, 쓰레드풀의 종류에 따라 내부적으로 다르게 처리할 수 있습니다.
Executors는 다음과 같이 팩토리 메서드로 사양한 종류의 쓰레드 풀을 사용할 수 있는 ExecutorService를 제공합니다.
// 지정한 개수의 쓰레드만 생성해서 재사용
public static ExecutorService newFixedThreadPool(int nThreads)
// 필요할 때마다 새로운 쓰레드를 생성(60초 동안 작업이 없으면 제거)
public static ExecutorService newCachedThreadPool()
// 쓰레드의 수가 동적으로 변하며 쓰레드마다 작업큐를 가지고 작업의 처리순서 보장 없음
public static ExecutorService newWorkStealingPool(int parallelism)
// 지연된 실행이나 주기적 실행이 가능한 쓰레드 풀
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)어떤 쓰레드 풀을 사용할 것인지는 처리하는 작업의 종류에 알맞은 것을 선택하면 됩니다.
예를 들어 작업의 종류가 CPU를 이용한 계산에 집중되어 있다면, 프로세서의 개수만큼의 고정된 수의 쓰레드를 생성해서 처리하는 것이 좋습니다. 반면 I/O를 많이 하는 작업은 요청마다 새로운 가상 쓰레드를 생성해서 처리하면 됩니다.
// CPU intensive
int coreNum = Runtime.getRuntime().availableProcessors();
ExecutorService thPool = Executors.newFixedThreadPool(coreNum);
// I/O intensive
ExecutorService thPool = Executors.newVirtualThreadPerTaskExecutors();
Future
문장을 작성된 순서대로 처리하는 것을 동기적(synchronous)이라하고, 순서대로 처리하지 않는 것을 비동기적(asynchronous)라고 합니다. 기본적으로는 동기적으로 수행되고, 멀티 쓰레드로 작성하면 비동기적으로 수행되게 할 수 있습니다. 작업을 비동기로 처리하는 이유는 보다 효율적으로 작업을 처리하기 위해서입니다.
예를 들어 사용자 입력을 받는 동안 동기적으로 수행하면 사용자가 입력을 마칠때까지 다른 일은 하지 못하고 가만히 기다려야 합니다. 이럴 때 사용자의 입력을 비동기적으로 처리한다면, 사용자의 입력을 기다리는 동안 그 다음 작업을 진행할 수 있어서 더 효율적입니다.
Future<Integer> input = getInputAsync(); // 비동기 메서드
countDown();
System.out.println("input = " + input.get()); // 동기 메서드다만 위의 마지막 줄의 input.get()은 입력 결과, 즉 getInputAsync()의 결과를 필요로 하기 때문에 비동기 메서드로 작성할 수 없고 반드시 동기 메서드로 작성되어야 합니다.
Future는 인터페이스로 비동기 작업의 결과를 담을 객체의 기능을 정의한 것입니다. 비동기 메서드를 호출하면, 아직 작업이 끝나지 않았는데도 무조건 결과가 담겨질 Future객체를 반환합니다. 그래서 비동기 메서드를 호출한 쪽에서는 작업이 끝날때까지 기다리지 않고 다른 작업을 할 수 있는 것입니다. 하지만 작업의 결과가 필요할 때, get()을 호출하면 작업이 끝날 때 까지 기다려야 합니다.
간단한 예제를 통해 사용법을 알아보겠습니다.
public static void main(String[] args) {
ExecutorService executor = Executors.newSingleThreadExecutor();
Callable<Integer> task = () -> { return getInput(); };
Future<Integer> future = executor.submit(task);
Integer result = future.get();
}
Future 메서드
다음은 Future인터페이스에 있는 메서드들입니다. 마지막 3개의 디폴트 메서드는 JDK 19부터 추가되었습니다.
| 메서드 | 설 명 |
| boolean cancel(boolean mayInterruptIfRunning) | 작업을 취소합니다. 취소에 성공하면 true를 반환하고, 이미 완료되었으면 false를 반환합니다. (mayInterruptIfRunning이 true이면 작업중인 쓰레드에 interrupt()를 호출) |
| boolean isCancelled() | 작업의 정상적 완료 전에 취소되면 true를 반환합니다. |
| boolean isDone() | 작업이 완료(성공, 실패, 취소)되면 true를 반환합니다. |
| V get() | 작업의 결과를 반환합니다. (작업 중에 interrupt()되면 InterruptedException이 발생하고, cancel()되면 CancellationException이 발생하고, 그 외의 예외가 발생하면 ExecutionException이 발생합니다.) |
| V get(long timeout, TimeUnit unit) | get()과 동일하나 지정된 시간동안 작업이 끝나지 않으면 TimeoutException이 발생합니다. |
| default V resultNow() | get()과 달리 기다리지 않고 즉시 작업 결과를 반환합니다. 작업이 성공하지 않으면 IllegalStateException이 발생합니다. |
| default Throwable exceptionNow() | 작업중 예외 발생으로 실패한 경우 발생한 예외를 반환합니다. |
| default Future.State state() | 작업의 상태를 반환합니다. RUNNING, CANCELLED, SUCCESS, FAILED |
Future의 한계
Future에는 다음과 같은 세 가지 한계가 있었습니다.
- cancel()을 제외하고 외부에서 future를 제어할 수 없습니다.
- get()통해 반환된 결과에 접근하기 때문에 비동기 처리가 어렵습니다.
- 완료 시 성공과 실패(예외)를 구분하기 어렵습니다.
그러나 JDK 19에서 default 메서드가 추가되면서 일부 한계점이 해소되었습니다.
2. get() 이외에도 resultNow()와 exceptionNow()를 통해 결과에 접근할 수 있습니다. (비동기 처리의 어려움 해소 X)
3. state()를 통해서 성공(SUCCESS), 실패(FAILED), 취소(CANCELLED)를 구분할 수 있습니다.
CompletableFuture
앞에서 Future에 대해서 살펴보았는데, Future는 독립적인 비동기 작업에 적절하지만, 서로 연관된 여러 비동기 작업을 처리하기에는 기능이 부족합니다. 그래서 추가된 것이 CompletableFuture클래스입니다.
public class CompletableFuture<T> implements Future<T>, CompletionStage<T> {
...
}위 코드에서 알 수 있듯이 CompletableFuture는 Future에 CompletionStage를 추가로 구현하여 기능을 확장한 것입니다.
CompletionStage는 아래와 같은 메서드를 갖고 있습니다.

위 목록에서 디폴트 메서드와 일부 메서드는 제외되었으며, 자세한 내용은 Java API를 참고하면 됩니다.
이전에 Future를 사용할 때는 ExecutorService를 생성하고 submit()으로 작업을 제출하는데, CompletableFuture는 바로 작업을 제출합니다.
// 반환값이 있는 경우
CompletableFuture<Integer> cFuture1 = CompletableFuture.sypplyAsync(() -> getInput());
// 반환값이 없는 경우
CompletableFuture<Void> cFuture2 = CompletableFuture.runAsync(() -> print());supplyAsync()는 반환값이 있는 작업을, runAsync()는 반환값이 없는 작업을 비동기로 처리할 때 사용합니다. 이 메서드들이 반환하는 것은 비동기 작업의 결과를 저장할 CompletableFuture이며, 작업 결과의 타입을 지네릭 타입으로 적어줘야 합니다.
runAsync()는 작업의 결과가 없으므로 'Void'를 지네릭 타입으로 지정하였는데, Void는 java.lang패키지에 속한 클래스로 반환값이 없음을 나타내는 void를 객체로 표현할 때 사용합니다. Void는 생성자가 private으로 직접 객체를 생성할 수 없습니다.
runAsync()와 supplyAsync()는 아래와 같이 매개변수로 Executor를 지정할 수 있는 오버로딩 메서드도 있는데, Executor를 지정하지 않으면 ForkJoinPool이 기본값으로 사용됩니다.
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor)
public static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor)
추가로 delayedExecutor()를 사용하면 비동기 작업의 시작을 늦출 수도 있습니다.
CompletableFuture<Void> cFuture =
CompletableFuture.runAsync(
() -> countDown(),
CompletableFuture.delayedExecutor(1, TimeUnit.SECONDS)
);
작업 결과 조회 및 완료
CompletableFuture로부터 결과를 얻기 위한 메서드는 여러가지가 있는데, get()은 필수로 예외처리를 해야하고, join()과 getNow()는 예외처리가 선택적입니다.
// 예외 처리 필수
public T get() throws InterruptedException, ExecutionException
// 예외 처리 선택
public T join()
public T getNow(T valueIfAbsent)join()은 비동기 작업이 완료될 때까지 기다렸다가 결과를 반환하고, getNow()는 호출 당시 작업이 완료되었으면 작업 결과를 반환하고, 아직 완료되지 않았으면 기다리지 않고 지정된 값을 결과로 즉시 반환합니다.
그리고 isDone(), isCancelled()만 있던 Future와 달리 isCompletedExceptionally()도 추가되었습니다.
public boolean isCompletedExceptionally()
CompletableFuture는 complete()와 completeExceptionally()로 진행 중인 작업을 강제로 완료시킬수 있습니다.
public boolean complete(T value)
public boolean completeExceptionally(Throwable ex)complete()는 지정된 값을 작업 결과로하는 성공적으로 완료된 작업으로 만들고, completeExceptionally()는 지정된 예외를 발생시켜서 실패로 완료된 작업으로 만듭니다.
if(timer == 0) {
cFuture.completeExceptionally(new TimeoutException("시간 초과"));
} else {
cFuture.complete(0);
}
Future와 달리 CompletableFuture는 이처럼 메서드를 통해서 작업을 강제로 완료시킬수 있어서, "Completable"Future로 이름 지어졌습니다.
예외 처리
orTimeout()은 지정된 시간동안 작업이 완료되지 않으면 TimeoutException을 발생시킵니다.
그리고 exceptionally()는 작업 중에 발생한 예외를 처리하고 작업의 결과를 반환합니다.
completeOnTimeout()은 지정된 시간동안 작업이 완료되지 않으면, 사용하면 TimeoutException을 발생시키지 않고 작업을 강제로 완료시킵니다.
public CompletableFuture<T> orTimeout(long timeout, TimeUnit unit)
public CompletableFuture<T> exceptionally(Function<Throwable, ? extends T> fn)
public CompletableFuture<T> completeOnTimeout(T value, long timeout, TimeUnit unit)CompletableFuture<Integer> cFuture =
CompletableFuture.supplyAsync(() -> getInput())
.orTimeout(11, TimeUnit.SECONDS)
.exceptionally(e -> {
if (e instanceof TimeoutException)
System.out.println("시간 초과");
else if(e instanceof CompletionException)
System.out.println("입력 에러");
return 0; // 기본값
});만약 getInput()에서 비동기 작업 수행 중에 예외가 발생한다면 CompletionException 예외로 래핑되어 exceptionally()로 전달됩니다.
예외 처리는 exceptionally() 외에도 handle()로도 처리할 수 있는데, 예외가 발생할 때만 작업을 처리하는 exceptionally()와 달리 handle()은 예외가 발생하던, 발생하지 않던 상관없이 무조건 실행됩니다.
public <U> CompletableFuture<U> handle(BiFunction<? super T, Throwable, ? extends U> fn)CompletableFuture<Integer> cFuture =
CompletableFuture.supplyAsync(() -> getInput())
.orTimeout(11, TimeUnit.SECONDS)
.handle((value, e) -> {
if(e != null) { // 예외가 발생하면
if (e instanceof TimeoutException)
System.out.println("시간 초과");
else if(e instanceof CompletionException)
System.out.println("입력 에러");
}
return 0; // 기본값
});
'Lang > Java' 카테고리의 다른 글
| [Java 21] (16) - I/O 1 (0) | 2025.11.19 |
|---|---|
| [Java 21] (15) - Lambda & stream (0) | 2025.11.17 |
| [Java 21] (13) - thread 1 (0) | 2025.11.11 |
| [Java 21] (12) - modern Java features (0) | 2025.11.05 |
| [Java 21] (11) - collections framework (0) | 2025.11.03 |