

Kafka Overview
Event Streaming
이벤트 스트리밍(Event Streaming)은 오늘날의 디지털 시스템에서 핵심적인 역할을 수행하는 데이터 처리 방식입니다.
공식 문서에서는 이를 인간의 신경계에 비유합니다. 신경계가 신체 곳곳에서 발생하는 신호를 실시간으로 전달하고 반응을 이끌어내듯, 이벤트 스트리밍은 시스템 전반에서 발생하는 사건을 지속적으로 전달하고 해석할 수 있도록 합니다.
기술적으로 이벤트 스트리밍이란, 데이터베이스, 센서, 모바일 기기, 클라우드 서비스, 소프트웨어 애플리케이션과 같은 다양한 이벤트 소스로부터 실시간으로 발생하는 데이터를 이벤트의 흐름(stream) 형태로 수집하고, 이를 내구성 있게 저장하며, 실시간 또는 사후적으로 처리하고, 필요한 대상에게 적절히 전달하는 것을 의미합니다.
이러한 방식은 데이터가 단발성으로 소비되는 것이 아니라, 시간의 흐름에 따라 지속적으로 해석되고 재활용될 수 있도록 합니다. 그 결과, 시스템은 항상 최신의 정보를 기반으로 동작할 수 있으며, 동시에 과거의 이벤트를 다시 분석하는 것도 가능해집니다.
Apache Kafka
Apache Kafka는 이러한 이벤트 스트리밍을 구현하기 위한 이벤트 스트리밍 플랫폼(Event Streaming Platform)입니다.
Kafka는 단일 기능에 국한된 시스템이 아니라, 이벤트 스트리밍을 처음부터 끝까지 구현할 수 있도록 다음과 같은 세 가지 핵심 기능을 제공합니다.
첫째, 이벤트 스트림을 게시(publish)하고 구독(subscribe)할 수 있습니다.
이를 통해 애플리케이션은 이벤트를 지속적으로 기록하고, 다른 애플리케이션은 해당 이벤트를 실시간으로 읽을 수 있습니다.
둘째, 이벤트 스트림을 원하는 기간 동안 내구성 있게 저장할 수 있습니다.
Kafka는 이벤트를 단순히 전달하는 데서 그치지 않고, 디스크에 안정적으로 저장하여 이후에도 다시 읽을 수 있도록 합니다.
셋째, 이벤트 스트림을 실시간 또는 사후적으로 처리할 수 있습니다.
이벤트는 발생 즉시 처리될 수도 있고, 과거에 저장된 이벤트를 다시 읽어 재처리하는 것도 가능합니다.
이 모든 기능은 분산 환경에서 높은 확장성, 내결함성, 가용성을 고려하여 설계되었습니다. Kafka는 온프레미스 환경뿐만 아니라 가상 머신, 컨테이너, 클라우드 환경 등 다양한 인프라에서 실행될 수 있으며, 직접 운영하거나 관리형 서비스 형태로도 사용할 수 있습니다.
Kafka의 구성 및 핵심 개념
Kafka는 서버(Server)와 클라이언트(Client)로 구성된 분산 시스템입니다.
이들은 고성능 TCP 네트워크 프로토콜을 통해 서로 통신합니다.
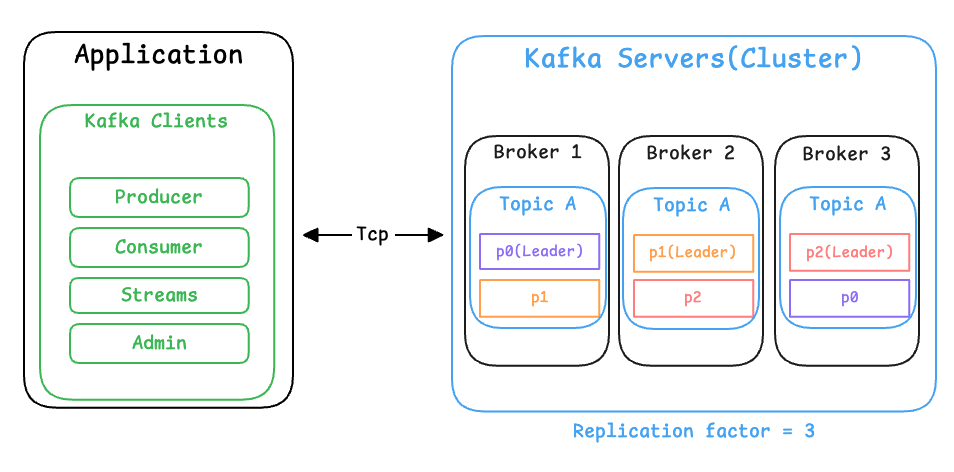
서버(Server)
Kafka 서버는 하나 이상의 노드로 구성된 클러스터 형태로 운영됩니다.
이 중 일부 서버는 이벤트를 저장하는 브로커(Broker) 역할을 수행하며, 다른 서버는 Kafka Connect를 실행하여 외부 시스템과 Kafka를 연동합니다.
Kafka 클러스터는 장애 상황을 전제로 설계되어 있기 때문에, 일부 서버에 장애가 발생하더라도 다른 서버가 해당 역할을 이어받아 데이터 손실 없이 서비스를 지속할 수 있도록 구성됩니다.
클라이언트(Client)
Kafka 클라이언트는 이벤트를 생성하거나 읽고 처리하는 애플리케이션입니다.
Kafka는 Java와 Scala용 공식 클라이언트를 포함하여, Go, Python, C/C++ 등 다양한 언어용 클라이언트를 제공하며, REST API 기반의 접근 방식도 지원합니다.
이러한 클라이언트를 통해 애플리케이션은 대규모 분산 환경에서도 병렬로 이벤트를 처리할 수 있으며, 네트워크 장애나 일부 노드의 실패 상황에서도 안정적으로 동작할 수 있습니다.
Kafka에서 다루는 기본 단위는 이벤트(Event)입니다.
이벤트는 “어떤 일이 발생했다”는 사실을 기록한 데이터이며, 문서에서는 레코드(record) 또는 메시지(message)라고도 불립니다.
하나의 이벤트는 일반적으로 다음과 같은 요소로 구성됩니다.
- 이벤트 키(Key)
- 이벤트 값(Value)
- 타임스탬프(Timestamp)
- 선택적인 메타데이터 헤더(Header)
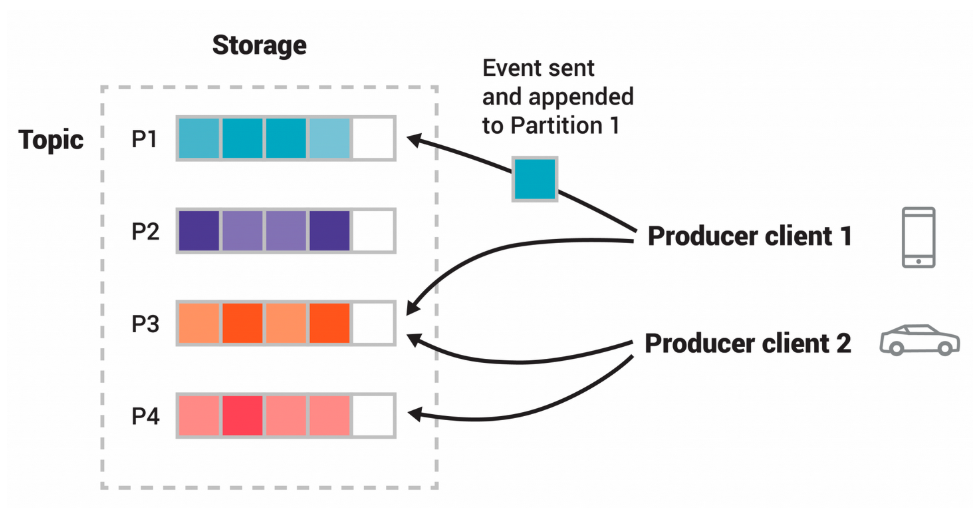
이벤트는 토픽(Topic) 단위로 구성되어 저장됩니다.
토픽은 파일 시스템의 폴더에 비유할 수 있으며, 이벤트는 그 안에 순차적으로 추가되는 데이터입니다. 하나의 토픽은 다수의 프로듀서와 다수의 컨슈머를 가질 수 있으며, 이벤트는 소비 여부와 관계없이 설정된 보존 기간 동안 유지됩니다.
토픽은 다시 여러 개의 파티션(Partition)으로 나뉩니다.
파티션은 Kafka의 확장성과 성능을 책임지는 핵심 단위로, 서로 다른 브로커에 분산되어 저장됩니다. 동일한 키를 가진 이벤트는 항상 동일한 파티션에 기록되며, Kafka는 파티션 단위로 이벤트의 순서를 보장합니다.
또한 Kafka는 복제(Replication)를 통해 데이터의 내구성과 가용성을 보장합니다.
일반적으로 하나의 파티션은 여러 브로커에 복제되며, 이를 통해 일부 브로커에 장애가 발생하더라도 데이터는 안전하게 유지됩니다.
Kafka Operations
Zookeeper
초기 Kafka는 분산 시스템의 상태를 관리하기 위한 외부 메타데이터 저장소로 ZooKeeper에 의존했습니다.
ZooKeeper는 원래 Kafka 전용 도구가 아니라, 분산 환경에서 코디네이션(coordination) 문제를 해결하기 위해 만들어진 시스템입니다.
Kafka는 이 ZooKeeper를 통해 다음과 같은 역할을 맡겼습니다.
- 브로커들의 클러스터 멤버십 관리
- 컨트롤러 선출 (브로커 중 1대를 컨트롤러로 선택)
- 토픽, 파티션, ISR(In-Sync Replica) 등의 메타데이터 저장
- 브로커 장애 발생 시 리더 재선출 트리거
- 일부 버전에서는 컨슈머 그룹 오프셋 관리
Zookeeper 모드의 구조를 보면 다음과 같습니다.

Zookeeper 앙상블은 컨트롤러를 선출해주는 역할만 수행합니다.
실제 컨트롤러는 Kafka 브로커 프로세스이며, 컨트롤러의 선출과 상태 변경 감지만 Zookeeper를 통해 수행합니다. 컨트롤러는 항상 1개이며, 장애가 발생하면 다른 브로커가 새 컨트롤러로 선출됩니다.
이 구조는 Kafka 자체에 메타데이터 관리 매거니즘이 없던 초창기에는 합리적인 선택이었습니다.
그러나 ZooKeeper 기반 구조에는 분명한 한계도 존재했습니다.
Kafka와 ZooKeeper를 함께 운영해야 하는 구조로 인해 운영 복잡도가 증가했고, 파티션 수와 브로커 수가 늘어날수록 메타데이터를 담당하는 컨트롤 플레인에서 병목이 발생하기 쉬운 구조였습니다. 또한 장애 상황에서는 Kafka와 ZooKeeper 중 어느 쪽에서 문제가 발생했는지 상태를 추적하고 원인을 분석하는 데에도 어려움이 있었습니다.
Apache Kafka 3.5 릴리스부터 ZooKeeper는 deprecated 상태로 지정되었고,
ZooKeeper의 완전 제거는 Apache Kafka 4.0에서 이루어졌습니다.
KRaft
Zookeeper의 문제가 누적되자, "Kafka의 메타데이터를 Kafka 스스로 관리할 수는 없을까?" 라는 질문들이 나오기 시작했습니다.
이 질문에 대한 답이 바로 KRaft(Kafka Raft) 입니다.

위 그림에서도 알 수 있듯이,
KRaft에서는 ZooKeeper가 완전히 제거되었고, Kafka 내부에 Controller Quorum이 도입되었습니다.
클러스터 메타데이터는 이제 외부 시스템이 아닌 Kafka 내부 로그로 관리되며, Raft 기반 합의 알고리즘을 통해 메타데이터의 일관성과 안정성이 보장됩니다.
이러한 변화로 인해 KRaft 모드에서는 컨트롤러의 개념도 달라졌습니다.
ZooKeeper 모드와 달리, KRaft에서는 컨트롤러가 하나가 아니라 여러 개 존재합니다.
여러 컨트롤러 노드가 Raft Quorum을 구성하고, 그중 단 하나의 노드만이 리더 역할을 수행합니다. 나머지 컨트롤러들은 Follower(Hot Standby) 상태로 대기하며, 리더에 장애가 발생하면 Raft 합의를 통해 자동으로 새로운 리더가 선출됩니다.
Kafka Design
Motivation
Kafka는 단일 목적의 메시징 도구가 아니라, 기업이 보유한 다양한 실시간 데이터 흐름을 한 플랫폼 위에서 처리할 수 있도록 설계되었습니다. 이를 위해 Kafka는 고처리량(대규모 로그 집계), 대규모 백로그 처리(오프라인 데이터 적재), 저지연 전달(전통 메시징 유스케이스), 분산·파티션 기반 실시간 처리(derived feed 생성), 장애 상황에서도의 내결함성을 동시에 만족해야 했습니다. 이러한 요구는 Kafka를 전통 메시징 시스템보다는 데이터베이스 로그에 가까운 구조로 설계하도록 만들었습니다.
Persistence
Kafka는 메시지를 저장할 때 “디스크는 느리다”는 통념을 전제로 하지 않습니다. 오히려 Kafka는 파일시스템과 OS 페이지 캐시(page cache)를 적극 활용하여, 디스크에 선형(sequential)으로 기록되는 워크로드가 매우 높은 처리량을 낼 수 있다는 점을 설계의 기반으로 삼습니다. 이 접근은 JVM 힙 기반 캐시가 가지는 객체 오버헤드와 GC 부담을 피하면서, OS 캐시를 통해 큰 데이터를 효율적으로 다룰 수 있게 합니다. 결과적으로 Kafka는 메시지를 “메모리에 오래 들고 있다가 플러시하는 구조”가 아니라, 즉시 파일에 append하고 OS가 캐싱하도록 설계합니다.

Constant Time Suffices
Kafka는 메시지 저장과 조회를 위해 복잡한 랜덤 액세스 구조(B-Tree 등)를 기반으로 하지 않습니다. 디스크 환경에서 O(log N) 구조는 seek 비용 때문에 급격히 비싸질 수 있기 때문입니다. 대신 Kafka는 append-only와 큰 단위의 선형 읽기/쓰기를 기반으로, 주요 연산을 O(1)에 가깝게 유지하는 방향을 선택합니다. 이 설계 덕분에 데이터 크기가 커져도 성능이 상대적으로 안정적이며, 오래 보관(retention)하는 모델 자체가 가능해집니다.
Efficiency
Kafka는 처리량을 끌어올리기 위해 두 가지 병목을 줄이는 데 집중합니다. 첫째는 “너무 작은 I/O”를 피하는 것이고, 둘째는 “과도한 바이트 복사”를 줄이는 것입니다. 이를 위해 Kafka는 메시지를 개별 단위로 전송하기보다는, message set(배치) 단위로 네트워크 요청과 디스크 append를 수행합니다. 또한 프로듀서–브로커–컨슈머 사이에서 동일한 바이너리 포맷을 공유함으로써, 불필요한 변환과 복사를 줄이는 방향을 택합니다.
Zero-Copy
Kafka는 파일 → 소켓 전송 경로에서 발생하는 복사 비용을 줄이기 위해, OS가 제공하는 zero-copy 최적화를 활용할 수 있도록 설계되었습니다. 일반적인 경로에서는 파일 데이터를 유저 공간으로 복사했다가 다시 커널로 복사하는 과정이 반복되지만, sendfile system call을 사용하면 페이지 캐시에서 네트워크로 직접 전송할 수 있어 복사 횟수와 시스템 콜 부담을 줄일 수 있습니다. 이 설계 덕분에 컨슈머가 대부분 “캐시된 데이터”를 읽는 상황에서는 디스크 read가 거의 발생하지 않는 구조를 기대할 수 있습니다. 다만 SSL/TLS는 유저 공간 암복호화가 필요하므로 이 최적화가 제한될 수 있습니다.
End-to-end Batch Compression
네트워크 대역폭이 병목이 되는 환경에서는 압축이 효과적이지만, 메시지를 개별로 압축하면 압축률이 낮아질 수 있습니다. Kafka는 이를 해결하기 위해 메시지를 배치로 묶어 압축하고, 해당 배치를 로그에 압축된 상태로 저장하며, 컨슈머에게도 압축된 상태로 전달하는 방식을 지원합니다. 즉, 압축을 “전송에서만” 쓰는 것이 아니라, 저장과 전달까지 end-to-end로 확장해 효율을 끌어올립니다.
The Producer
Kafka 프로듀서는 리더 파티션을 직접 찾아가 데이터를 전송합니다. 별도의 라우팅 계층 없이, 클러스터 메타데이터를 조회하여 “현재 어느 브로커가 어떤 파티션의 리더인지”를 파악하고 그곳으로 보냅니다. 또한 프로듀서는 어떤 파티션으로 보낼지를 직접 결정할 수 있으며, 키 기반 해시를 통해 동일 키가 동일 파티션으로 들어가도록 하여 소비 측에서 로컬리티와 순서 보장을 활용할 수 있게 합니다. 성능 측면에서는 내부적으로 데이터를 메모리에 모아 배치 단위로 비동기 전송하여 처리량을 끌어올리는 전략을 사용합니다.
The Consumer
Kafka 컨슈머는 브로커가 데이터를 “푸시”하는 방식이 아니라, 컨슈머가 브로커에 fetch 요청으로 데이터를 pull하는 모델을 택합니다. 컨슈머는 오프셋을 통해 자신의 읽기 위치를 제어하며, 필요하면 과거 위치로 되감아 재처리할 수도 있습니다. 또한 Kafka는 “데이터가 없을 때 바쁘게 폴링하는 문제”를 피하기 위해, fetch 요청을 일정 시간 블로킹하는 long poll 형태를 지원합니다. 이 구조는 컨슈머가 처리 속도에 따라 자연스럽게 뒤처졌다가 따라잡는 모델을 가능하게 하며, 다양한 소비자 성능을 가진 환경에서 안정적으로 동작하도록 돕습니다.
Consumer Position
Kafka는 “무엇을 어디까지 읽었는가”를 파티션별 단일 정수 값인 오프셋(offset) 으로 표현합니다. 이 단순함은 메시징 시스템에서 흔히 발생하는 복잡한 ack 상태 관리 문제를 줄이고, 소비 상태를 작은 메타데이터로 관리할 수 있게 합니다. 또한 컨슈머는 오프셋을 의도적으로 되감아 재처리할 수 있어, 버그 수정 후 재처리 같은 운영 시나리오에서도 유연하게 대응할 수 있습니다.
Offline Data Load
Kafka는 데이터가 디스크에 안정적으로 남아 있고 성능이 데이터 크기에 크게 흔들리지 않는다는 전제를 갖기 때문에, 실시간 소비뿐 아니라 주기적 배치 적재(offline load)에도 적합합니다. 예를 들어, 특정 시점에 Hadoop/데이터웨어하우스로 대량 적재를 하더라도, 파티션 단위로 병렬 로드를 구성하고 실패 시 재시도하는 형태로 운영할 수 있습니다.
Static Membership
Kafka는 컨슈머 그룹에서 리밸런스가 잦아지면 대규모 상태를 가진 애플리케이션의 가용성이 크게 흔들릴 수 있다는 점을 문제로 봅니다. 이를 완화하기 위해 정적 멤버십(static membership) 개념을 도입하여, 컨슈머 인스턴스가 고정된 식별자(group.instance.id)를 사용하면 재시작/배포 같은 상황에서도 불필요한 리밸런스를 줄일 수 있도록 합니다. 이는 스트림 애플리케이션의 안정성과 복구 시간을 개선하는 방향의 설계입니다.
Message Delivery Semantics
Kafka를 이해하는 데 있어 가장 중요한 질문 중 하나는 “메시지가 정확히 얼마나 안전하게 전달되는가”입니다.
일반적으로 메시징 시스템이 제공할 수 있는 전달 보장은 다음 세 가지로 나뉩니다.
- At most once
메시지가 유실될 수 있지만, 중복 전달되지는 않습니다. - At least once
메시지는 유실되지 않지만, 중복 전달될 수 있습니다. - Exactly once
메시지는 한 번만, 그리고 정확히 한 번 처리됩니다.
Kafka는 이 세 가지 전달 보장을 모두 선택 가능하게 설계되어 있으며, 기본값은 at-least-once입니다.
Producer 측의 보장
Kafka에서 메시지는 브로커의 로그에 commit되었을 때 안전하다고 간주됩니다.
여기서 commit이란, 해당 파티션의 ISR(In-Sync Replicas)에 속한 모든 브로커가 메시지를 자신의 로그에 기록했음을 의미합니다.
Producer는 acks 설정을 통해 어디까지 보장할지를 직접 선택할 수 있습니다.
- acks=0
브로커의 응답을 기다리지 않습니다.
가장 빠르지만 메시지 유실 가능성이 있습니다. - acks=1
리더 브로커까지만 기록되면 성공으로 간주합니다. - acks=all
ISR에 포함된 모든 복제본에 기록되어야 성공으로 간주합니다.
Kafka는 기본적으로 내구성과 성능 사이의 선택권을 Producer에게 위임합니다.
Idempotent Producer와 Transactions
Kafka 0.11 이후부터 Producer는 멱등성(idempotence)을 지원합니다.
네트워크 오류로 인해 Producer가 메시지를 재전송하더라도, 브로커는 Producer ID와 sequence number를 기준으로
중복 메시지를 제거할 수 있습니다.
또한 Kafka는 트랜잭션 기반 Producer를 통해 여러 파티션에 대한 메시지 전송과 Consumer offset 커밋을 원자적으로 처리할 수 있습니다. 이를 통해 Kafka Streams를 포함한 스트림 처리에서는 Exactly-once 처리가 가능합니다.
Consumer 측의 보장과 Offset 관리
Kafka에서 Consumer는 자신이 어디까지 읽었는지(offset) 를 직접 관리합니다.
이 설계는 다음과 같은 중요한 특징을 가집니다.
- 브로커는 “어디까지 소비되었는지”를 추적하지 않습니다.
- Consumer는 언제든 offset을 되돌려 재처리할 수 있습니다.
- 상태 정보는 파티션당 하나의 숫자(offset) 로 매우 단순합니다.
Consumer가 offset을 언제 커밋하느냐에 따라 전달 보장이 달라집니다.
- 처리 전에 offset을 커밋하면 → at-most-once
- 처리 후에 offset을 커밋하면 → at-least-once
Exactly-once 처리는 Producer 트랜잭션과 offset 커밋을 함께 묶는 방식으로 구현됩니다.
Pull 기반 소비 모델
Kafka는 Producer → Broker → Consumer 구조에서 Consumer가 데이터를 직접 가져오는 pull 방식을 사용합니다.
이 설계의 장점은 다음과 같습니다.
- Consumer가 처리 가능한 속도로만 데이터를 가져올 수 있습니다.
- 자연스러운 backpressure가 가능합니다.
- 대량의 메시지를 한 번에 가져와 배치 처리가 가능합니다.
Broker가 데이터를 밀어주는(push) 구조와 달리, Consumer가 느리면 그냥 뒤처질 뿐이며 시스템 전체에 영향을 주지 않습니다.
Replication과 Fault Tolerance
Kafka는 각 토픽의 파티션을 여러 브로커에 복제(replication) 하여 저장합니다.
각 파티션은 다음과 같은 구조를 가집니다.
- Leader: 모든 쓰기를 담당
- Follower: Leader의 로그를 복제
Kafka는 ISR(In-Sync Replicas) 라는 개념을 통해 현재 정상적으로 동기화된 복제본 집합을 관리합니다.
메시지는 ISR에 속한 모든 복제본에 기록되어야만 commit됩니다.
이 설계의 핵심 보장은 ISR 중 최소 하나의 브로커만 살아 있다면, commit된 메시지는 절대 유실되지 않는다는 것입니다.
Unclean Leader Election
모든 복제본이 동시에 장애를 겪는 상황에서는 Kafka는 기본적으로 데이터 일관성을 우선합니다.
즉, ISR에 포함된 복제본이 복구될 때까지 해당 파티션은 사용 불가 상태로 남습니다.
다만 설정을 통해 가용성을 우선하고 싶다면 unclean leader election을 허용할 수도 있습니다.
이는 Kafka가 CAP 트레이드오프를 명시적으로 노출하는 설계 선택입니다.
Log Compaction
Kafka는 단순한 시간 기반 로그 보존 외에도 Log Compaction이라는 특별한 보존 전략을 제공합니다.
Log Compaction은 각 key에 대해 최신 값 하나만 남기는 방식입니다.
이를 통해 Kafka는 다음과 같은 용도로 활용될 수 있습니다.
- 데이터베이스 변경 로그
- 상태 저장용 로그
- 장애 복구 및 상태 재구성
Compaction은 백그라운드에서 동작하며, 읽기/쓰기 성능에 영향을 주지 않도록 설계되어 있습니다.
Quotas
Kafka는 멀티 테넌트 환경을 고려하여 클라이언트별 자원 사용 제한(Quota) 을 제공합니다.
제한할 수 있는 자원은 다음과 같습니다.
- 네트워크 대역폭
- 요청 처리 비율(CPU 사용량 기준)
Quota는 (user, client-id) 조합을 기준으로 적용되며, 브로커는 초과 사용 시 지연 응답(throttling) 을 통해 제어합니다.
이를 통해 Kafka는 일부 비정상적인 클라이언트가 전체 클러스터에 영향을 주는 상황을 방지합니다.
Kafka Protocol
Premise
Kafka는 TCP 위에서 동작하는 바이너리(binary) 프로토콜을 사용합니다.
모든 API는 “요청(Request)–응답(Response)” 쌍으로 정의되며, 메시지는 크기 기반 프레이밍(size-delimited framing) 방식으로 전송됩니다. 즉, 클라이언트는 먼저 요청의 int32(4byte) 크기의 데이터를 Integer로 읽고, 그 읽은 Integer의 크기만큼의 바이트를 추가로 읽어 메시지를 파싱합니다.
또한 Kafka의 통신은 다음과 같은 성격을 갖습니다.
- 클라이언트가 브로커에 소켓 연결을 먼저 생성하고, 요청을 연속적으로 전송합니다.
- 연결/해제 시점에 별도의 핸드셰이크를 필요로 하지 않습니다.
- TCP는 연결 비용이 존재하므로, Kafka는 여러 요청을 하나의 연결에서 지속적으로 처리하는 방식을 권장합니다.
- 토픽이 파티션으로 분산되어 있기 때문에, 클라이언트는 보통 여러 브로커와 동시에 연결하게 됩니다.
(단, 동일 브로커에 대해 과도한 커넥션 풀링은 일반적으로 필요하지 않습니다).
정리하면 Kafka는 “가볍게 연결했다가 요청 하나 보내고 끊는 방식”이 아니라, 연결을 유지하면서 고빈도 요청을 효율적으로 주고받는 방식을 전제로 합니다.
Pipelining
Kafka 브로커는 하나의 TCP 연결에서 요청 순서를 보장합니다.
- 요청은 전송된 순서대로 처리됩니다.
- 응답 또한 동일한 순서대로 반환됩니다.
- 이를 위해 브로커는 연결당 단일 in-flight 요청을 보장하는 모델을 사용합니다.
다만 이는 “항상 동기적으로 한 번에 하나씩만 보낼 수 있다”는 의미와는 다릅니다.
클라이언트는 non-blocking I/O를 활용하여 이전 요청의 응답을 기다리는 동안에도 다음 요청을 소켓 버퍼에 미리 적재할 수 있으며, 이는 실질적으로 요청 파이프라이닝(pipelining)을 가능하게 합니다.
Partitioning
Kafka는 파티션 기반 시스템이므로, 모든 브로커가 동일한 데이터(토픽 전체)를 갖지 않습니다.
따라서 프로듀서/컨슈머는 반드시 해당 파티션의 리더 브로커와 통신해야 합니다.
문제는 “처음 클라이언트가 어떤 브로커가 리더인지 어떻게 아는가”입니다. 이를 위해 Kafka는 Metadata API를 제공합니다.
일반적인 흐름은 다음과 같습니다.
- 클라이언트는 2~3개의 “bootstrap broker 주소 목록”을 가진 상태로 시작합니다.
- 연결 가능한 브로커 하나를 찾습니다.
- MetadataRequest를 통해 클러스터 상태(토픽/파티션/리더/브로커 호스트 정보)를 획득합니다.
- 이후 Produce/Fetch 요청을 파티션 리더 브로커로 라우팅합니다.
- NotLeaderForPartition, 네트워크 오류 등으로 메타데이터가 오래되었음을 감지하면 다시 갱신합니다.
이 방식은 “정적 매핑 파일” 같은 외부 설정에 의존하지 않고도, 동적으로 변하는 클러스터 상태를 안전하게 추적할 수 있게 합니다.
Compatibility
Kafka는 양방향 호환성(bidirectional compatibility)을 목표로 합니다.
- 새로운 클라이언트가 오래된 브로커와 통신할 수 있어야 하고,
- 오래된 클라이언트가 새로운 브로커와도 통신할 수 있어야 합니다.
이를 위해 모든 요청에는 다음이 포함됩니다.
- API Key: 어떤 API인지
- API Version: 해당 API의 어떤 스키마 버전인지
브로커는 요청이 명시한 버전에 맞춰 응답 포맷을 결정합니다. 또한 클라이언트는 ApiVersionsRequest를 통해 브로커가 지원하는 버전 범위를 확인하고, 서로 겹치는 가장 높은 버전을 선택하는 방식으로 기능을 점진적으로 활용할 수 있습니다.
'Spring > Kafka' 카테고리의 다른 글
| Spring Kafka (0) | 2026.01.02 |
|---|