Spring Kafka
앞서 작성한 글에서 Apache Kafka의 기본 구조와 분산 스트리밍 플랫폼으로서 Kafka가 제공하는 핵심 개념들을 살펴보았으니, 이번 글에서는 Spring Kafka에 대해서 자세히 살펴보겠습니다.
Spring Kafka는 Kafka 클라이언트를 직접 다루는 복잡성을 줄이고, Spring의 프로그래밍 모델과 일관된 방식으로 메시지 프로듀서와 컨슈머를 구성할 수 있도록 지원합니다. 특히 템플릿 기반의 프로듀서 API, 애너테이션 중심의 리스너 모델, 트랜잭션과 오류 처리에 대한 통합 지원을 통해, Kafka를 보다 안정적이고 선언적으로 사용할 수 있게 해줍니다.
Connecting to Kafka

Spring Kafka에서 KafkaAdmin, ProducerFactory, ConsumerFactory는 모두 KafkaResourceFactory를 상속합니다. 각 컴포넌트는 다음과 같은 역할을 담당합니다.
- KafkaAdmin
토픽 생성, 수정과 같은 관리 작업을 담당 - ProducerFactory
메시지를 전송하는 Kafka Producer를 생성 - ConsumerFactory
메시지를 소비하는 Kafka Consumer를 생성
이들 구성 요소는 모두 Kafka 클라이언트를 직접 생성하지 않고, Factory 패턴을 통해 클라이언트의 생명주기를 관리합니다.
Kafka 동적 연결
kafkaResourceFactory의 setBootstrapServersSupplier() 메서드를 사용하면 동적으로 Kafka 연결 대상을 교체할 수 있습니다. 이를 사용하여 A/B 클러스터를 구성하거나 Kafka 클러스터를 스위칭할 수 있습니다.
public abstract class KafkaResourceFactory {
private @Nullable Supplier<String> bootstrapServersSupplier;
public void setBootstrapServersSupplier(Supplier<String> bootstrapServersSupplier) {
this.bootstrapServersSupplier = bootstrapServersSupplier;
}
...
}
위와 같이 bootstrap server 설정을 변경하더라도, Kafka Producer와 Consumer는 일반적으로 장시간 유지되는 객체이기 때문에 이미 생성된 클라이언트에는 즉시 반영되지 않습니다.
이를 위해 Spring Kafka는 다음과 같은 제어 방식을 제공합니다.
- Producer
- DefaultKafkaProducerFactory.reset()
- 기존 Producer를 종료하고 새 연결을 생성
- Consumer
- Listener Container에 대해 stop() → start()
- 또는 KafkaListenerEndpointRegistry를 통해 일괄 제어
이 과정을 통해 새로운 bootstrap server 설정이 실제 연결에 반영됩니다.
또한 ProducerFactory와 ConsumerFactory에서 제공하는 Listener를 사용하여 Producer와 Consumer가 생성되거나 종료될 때 호출되도록 할 수도 있습니다.
KafkaAdmin
Spring Kafka는 Kafka 클라이언트를 사용하는 것뿐만 아니라, 토픽 관리 영역까지 애플리케이션 구성의 일부로 통합할 수 있도록 지원합니다. 이를 통해 토픽 생성을 수동 운영 작업이 아닌, 애플리케이션 설정의 일부로 다룰 수 있습니다.
애플리케이션 컨텍스트에 KafkaAdmin 빈을 정의하면, Spring Kafka는 애플리케이션 시작 시 Kafka 브로커와 통신하여
필요한 토픽을 자동으로 생성하거나 수정할 수 있습니다. 이때 각 토픽은 NewTopic 타입의 빈으로 정의됩니다.
Spring Boot를 사용하는 경우, KafkaAdmin 빈은 자동으로 등록되기 때문에 Topic만 정의하면 됩니다.
TopicBuilder
Spring Kafka는 TopicBuilder가 도입되어 NewTopic 빈을 보다 선언적으로 정의할 수 있으며,
Spring Kafka 2.6 버전부터는 partitions() 또는 replicas() 설정을 생략할 수 있습니다.
이 경우 파티션 수와 레플리카 수는 브로커의 기본값을 따릅니다.
@Bean
public NewTopic topic1() {
return TopicBuilder.name("thing1")
.partitions(10)
.replicas(3)
.compact()
.build();
}
@Bean
public NewTopic topic2() {
return TopicBuilder.name("defaultBoth")
.build();
}NewTopics
Spring Kafka 2.7 버전부터는 여러 개의 NewTopic을 하나의 KafkaAdmin.NewTopics 빈으로 묶을 수 있습니다.
@Bean
public KafkaAdmin.NewTopics topics() {
return new KafkaAdmin.NewTopics(
TopicBuilder.name("topicA").build(),
TopicBuilder.name("topicB").replicas(1).build(),
TopicBuilder.name("topicC").partitions(3).build()
);
}
또한 Spring Kafka 2.7 버전부터 KafkaAdmin은 런타임에 토픽을 관리할 수 있는 API를 제공합니다.
- createOrModifyTopics
- describeTopics
- deleteTopics (Spring Kafka 4.0+)
이를 통해 애플리케이션 코드에서 토픽 상태를 조회하거나 관리 작업을 수행할 수 있습니다.
Sending Messages
KafkaTemplate은 Kafka Producer를 감싸는 고수준 추상화로,Kafka로 메시지를 전송하기 위한 편의 API를 제공합니다. 애플리케이션 코드에서 Kafka Producer를 직접 다루지 않고도, 일관된 방식으로 메시지를 전송할 수 있도록 설계되어 있습니다.
다음은 KafkaTemplate이 구현하고 있는 KafkaOperations의 소스코드 일부입니다.
public interface KafkaOperations<K, V> {
Duration DEFAULT_POLL_TIMEOUT = Duration.ofSeconds(5L);
CompletableFuture<SendResult<K, V>> sendDefault(@Nullable V data);
CompletableFuture<SendResult<K, V>> sendDefault(K key, @Nullable V data);
CompletableFuture<SendResult<K, V>> sendDefault(Integer partition, K key, @Nullable V data);
CompletableFuture<SendResult<K, V>> sendDefault(Integer partition, Long timestamp, K key, @Nullable V data);
CompletableFuture<SendResult<K, V>> send(String topic, @Nullable V data);
CompletableFuture<SendResult<K, V>> send(String topic, K key, @Nullable V data);
CompletableFuture<SendResult<K, V>> send(String topic, Integer partition, K key, @Nullable V data);
CompletableFuture<SendResult<K, V>> send(String topic, Integer partition, Long timestamp, K key, @Nullable V data);
CompletableFuture<SendResult<K, V>> send(ProducerRecord<K, V> record);
CompletableFuture<SendResult<K, V>> send(Message<?> message);
List<PartitionInfo> partitionsFor(String topic);
Map<MetricName, ? extends Metric> metrics();
<T> @Nullable T execute(ProducerCallback<K, V, T> callback);
<T> @Nullable T executeInTransaction(OperationsCallback<K, V, T> callback);
void flush();
...
}
kafkaTemplate의 모든 send() 메서드는 payload를 내부적으로 ProduceRecord로 래핑해서 전송하며, sendDefault()는 KafkaTemplate에 기본 토픽(default topic)이 설정되어 있을 때만 사용할 수 있습니다.
또한 모든 send() 메서드는 CompletableFuture<SendResult<>>를 반환합니다.
public class SendResult<K, V> {
private final ProducerRecord<K, V> producerRecord;
private final RecordMetadata recordMetadata;
...
}
public class ProducerRecord<K, V> {
private final String topic;
private final Integer partition;
private final Headers headers;
private final K key;
private final V value;
private final Long timestamp;
...
}
또한 스프링에서 제공하는 Message<T> 를 사용하여 메세지를 전송할 수도 있으며, 이 경우 전송에 필요한 메타데이터는 메세지 헤더로 전달됩니다. 이때 사용되는 헤더는 다음과 같습니다.
- KafkaHeaders.TOPIC = "kafka_topic"
- KafkaHeaders.PARTITION = "kafka_partitionId"
- KafkaHeaders.KEY = "kafka_messageKey"
- KafkaHeaders.TIMESTAMP = "kafka_timestamp"
public interface Message<T> {
T getPayload();
MessageHeaders getHeaders();
}
KafkaTemplate은 ProducerFactory를 통해 생성되며,

public class DefaultKafkaProducerFactory<K, V> extends KafkaResourceFactory
implements ProducerFactory<K, V>, ApplicationContextAware,
BeanNameAware, ApplicationListener<ContextStoppedEvent>, DisposableBean, SmartLifecycle {
public DefaultKafkaProducerFactory(Map<String, Object> configs) {}
public DefaultKafkaProducerFactory(Map<String, Object> configs,
@Nullable Serializer<K> keySerializer,
@Nullable Serializer<V> valueSerializer) {}
...
}@Bean
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
Spring Kafka 2.5 부터는 하나의 ProducerFactory를 기반으로 서로 다른 Producer 설정을 가진 KafkaTemplate을 생성할 수 있습니다.
@Bean
public KafkaTemplate<String, String> stringTemplate(
ProducerFactory<String, String> pf) {
return new KafkaTemplate<>(pf);
}
@Bean
public KafkaTemplate<String, byte[]> bytesTemplate(
ProducerFactory<String, byte[]> pf) {
return new KafkaTemplate<>(
pf,
Collections.singletonMap(
ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
ByteArraySerializer.class
)
);
}ProducerFactory<?, ?> 타입의 빈은 제네릭 타입을 더 좁혀서(ProducerFactory<String, String> 등) 참조될 수 있습니다.
ProducerListener
KafkaTemplate은 전송 결과를 비동기적으로 수신하기 위한 ProducerListener를 지원하며, 기본적으로는 LoggingProducerListener가 등록됩니다.
public interface ProducerListener<K, V> {
default void onSuccess(ProducerRecord<K, V> producerRecord, RecordMetadata recordMetadata) {
}
default void onError(ProducerRecord<K, V> producerRecord, @Nullable RecordMetadata recordMetadata, Exception exception) {
}
}
LoggingProducerListener 는 성공 시에는 아무 작업도 하지 않고, 실패 시에는 로그를 출력합니다.
producerPerThread
앞에서 설명했듯이 KafkaTemplate은 ProducerFactory를 통해 생성되는데, 트랜잭션을 사용하지 않는 경우 기본적으로 DefaultKafkaProducerFactory는 모든 클라이언트가 공유하는 싱글톤 Producer를 생성합니다.
그러나 템플릿에서 flush()를 호출하면 같은 Producer를 사용하는 다른 스레드들이 지연을 겪을 수 있습니다.
이를 해결하기 위해 Spring Kafka는 producerPerThread라는 속성이 추가되어, 이 속성을 true로 설정하면 팩토리는 쓰레드마다 별도의 Producer를 생성하고 캐싱하여 이러한 문제를 방지합니다.
주의할 점은 이렇게 쓰레드마다 별도의 Producer를 생성하여 사용하는 경우 reset() 이나 destroy()를 호출해도 이 Producer들은 정리되지 않습니다. 이 경우에는 반드시 closeThreadBoundProducer()를 호출해서 정리해야 합니다.
RoutingKafkaTemplate, ReplyingKafkaTemplate
RoutingKafkaTemplate
RoutingKafkaTemplate은 토픽에 따라 서로 다른 Producer 설정을 사용하고 싶을 때 사용할 수 있습니다. 물론 기존에도 서로 다른 Producer 설정을 가진 KafkaTemplate을 생성할 수 있었지만, RoutingKafkaTemplate을 사용하면 하나의 템플릿으로 관리할 수 있습니다.
@Bean
public RoutingKafkaTemplate routingTemplate(GenericApplicationContext context,
ProducerFactory<Object, Object> pf) {
// Clone the PF with a different Serializer, register with Spring for shutdown
Map<String, Object> configs = new HashMap<>(pf.getConfigurationProperties());
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class);
DefaultKafkaProducerFactory<Object, Object> bytesPF = new DefaultKafkaProducerFactory<>(configs);
context.registerBean("bytesPF", DefaultKafkaProducerFactory.class, () -> bytesPF);
Map<Pattern, ProducerFactory<Object, Object>> map = new LinkedHashMap<>();
map.put(Pattern.compile("two"), bytesPF);
map.put(Pattern.compile(".+"), pf); // Default PF with StringSerializer
return new RoutingKafkaTemplate(map);
}routingTemplate.send("one", "thing1");
routingTemplate.send("two", "thing2".getBytes());
주의할 점은 RoutingKafkaTemplate은 어떤 Producer를 사용할지 정해져 있어야 사용할 수 있는 기능들을 지원하지 않습니다.
- 트랜잭션
- execute / flush / metrics
ReplyingKafkaTemplate
KafkaTemplate의 자손클래스인 ReplyingKafkaTemplate은 Request/Reply 구조를 지원합니다. 이 클래스는 다음과 같은 두 개의 메서드를 추가적으로 지원합니다.
RequestReplyFuture<K, V, R> sendAndReceive(ProducerRecord<K, V> record);
RequestReplyFuture<K, V, R> sendAndReceive(ProducerRecord<K, V> record, Duration replyTimeout);
ReplyingKafkaTemplate은 내부적으로 reply를 컨슈밍하는 MessageListenerContainer를 갖고 있어서, futures Map에 RequestReplyFuture를 넣고 reply 응답을 수신해야 성공으로 처리합니다.
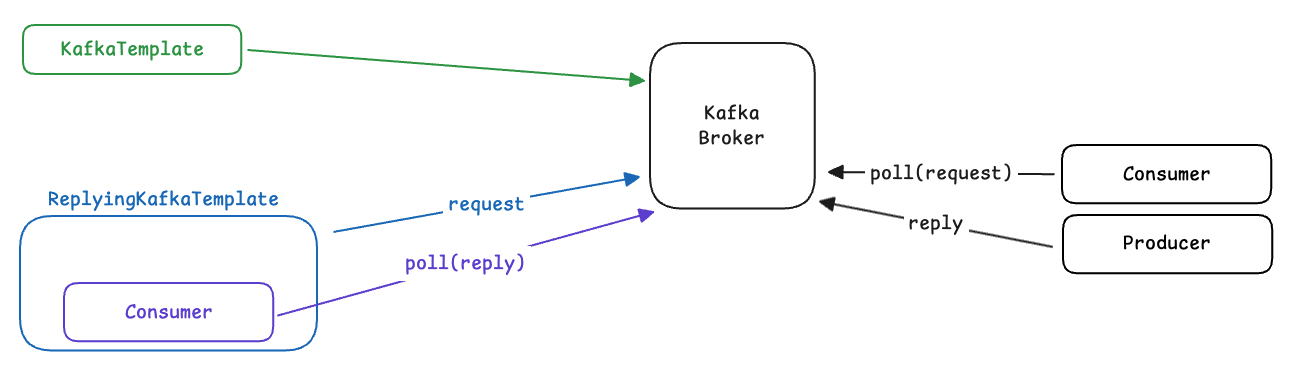
Kafka는 pull 모델을 사용하며, 그 pulling 동작을 수행하는 API가 poll() 입니다.
public class ReplyingKafkaTemplate<K, V, R> extends KafkaTemplate<K, V> implements BatchMessageListener<K, R>,
InitializingBean, SmartLifecycle, DisposableBean, ReplyingKafkaOperations<K, V, R>, ConsumerSeekAware {
private static final String WITH_CORRELATION_ID = " with correlationId: ";
private static final int FIVE = 5;
private static final Duration DEFAULT_REPLY_TIMEOUT = Duration.ofSeconds(FIVE);
private final GenericMessageListenerContainer<K, R> replyContainer;
private final ConcurrentMap<Object, RequestReplyFuture<K, V, R>> futures = new ConcurrentHashMap<>();
...
}
request를 컨슈밍하는 쪽에서는 @KafkaListener와 @SendTo 어노테이션을 사용하면 간편하게 request/reply를 할 수 있습니다.
Receiving Messages
MessageListener는 “무엇을 처리할 것인가”에 대한 인터페이스라면,
MessageListenerContainer는 “어떻게, 언제, 어떤 스레드에서 처리할 것인가”를 책임지는 실행 환경입니다.
MessageListener
Message Listener는 Kafka Consumer가 poll()을 통해 가져온 데이터를 애플리케이션 코드로 전달하기 위한 콜백 인터페이스입니다.
Spring Kafka는 다양한 처리 방식과 커밋 전략을 지원하기 위해 총 8가지 Message Listener 인터페이스를 제공합니다.
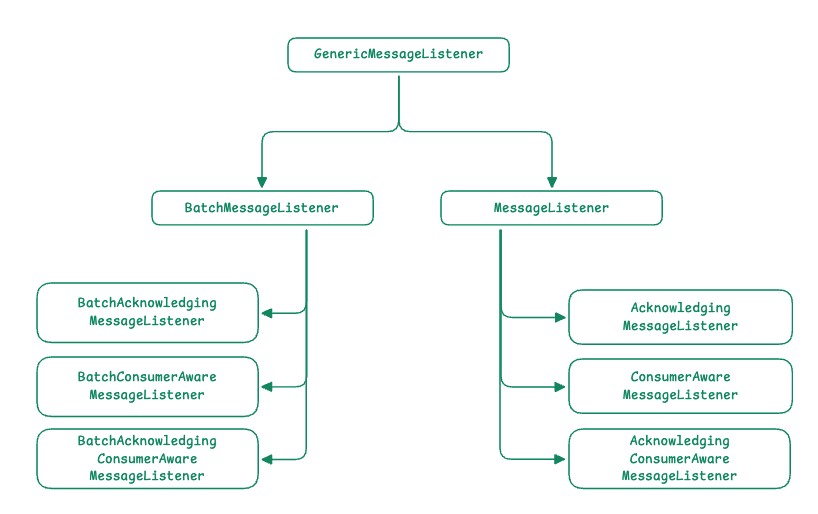
public interface MessageListener<K, V> extends GenericMessageListener<ConsumerRecord<K, V>> {
void onMessage(ConsumerRecord<K, V> data);
}
public interface AcknowledgingMessageListener<K, V> extends MessageListener<K, V> {
void onMessage(ConsumerRecord<K, V> data, Acknowledgment acknowledgment);
}
public interface ConsumerAwareMessageListener<K, V> extends MessageListener<K, V> {
void onMessage(ConsumerRecord<K, V> data, Consumer<?, ?> consumer);
}
public interface AcknowledgingConsumerAwareMessageListener<K, V> extends MessageListener<K, V> {
void onMessage(ConsumerRecord<K, V> data, Acknowledgment acknowledgment, Consumer<?, ?> consumer);
}
public interface BatchMessageListener<K, V> extends GenericMessageListener<List<ConsumerRecord<K, V>>> {
void onMessage(List<ConsumerRecord<K, V>> data);
}
public interface BatchAcknowledgingMessageListener<K, V> extends BatchMessageListener<K, V> {
void onMessage(List<ConsumerRecord<K, V>> data, Acknowledgment acknowledgment);
}
public interface BatchConsumerAwareMessageListener<K, V> extends BatchMessageListener<K, V> {
void onMessage(List<ConsumerRecord<K, V>> data, Consumer<?, ?> consumer);
}
public interface BatchAcknowledgingConsumerAwareMessageListener<K, V> extends BatchMessageListener<K, V> {
void onMessage(List<ConsumerRecord<K, V>> data, Acknowledgment acknowledgment, Consumer<?, ?> consumer);
}
MessageListener는 가장 기본적인 형태의 인터페이스로 poll()로 수신된 개별 레코드(ConsumerRecord)를 하나씩 처리합니다. 이 인터페이스는 auto-commit 또는 컨테이너 관리 커밋 방식을 사용합니다.
BatchMessageListener 인터페이스를 사용하면 배치 단위 처리를 할 수 있으며, poll() 호출로 수신된 모든 레코드(List<ConsumerRecord>)를 한 번에 전달받습니다. 이 인터페이스 또한 auto-commit 또는 컨테이너 관리 커밋 방식을 사용합니다.
만약 manual-commit을 하고 싶다면, Acknowledgement 계열 인터페이스를 사용합니다.
MessageListenerContainer
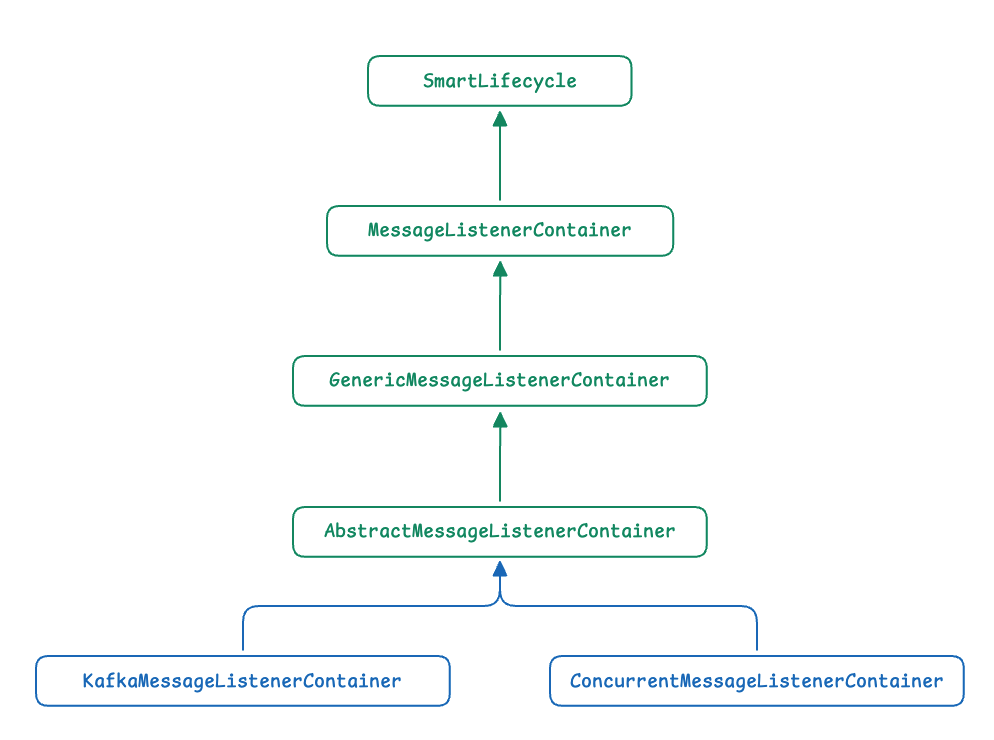
MessageListenerContainer는 Kafka Consumer의 라이프사이클과 실행 환경 전체를 관리합니다.
Spring Kafka는 두 가지 MessageListenerContainer 구현체를 제공합니다.
- KafkaMessageListenerContainer
- ConcurrentMessageListenerContainer
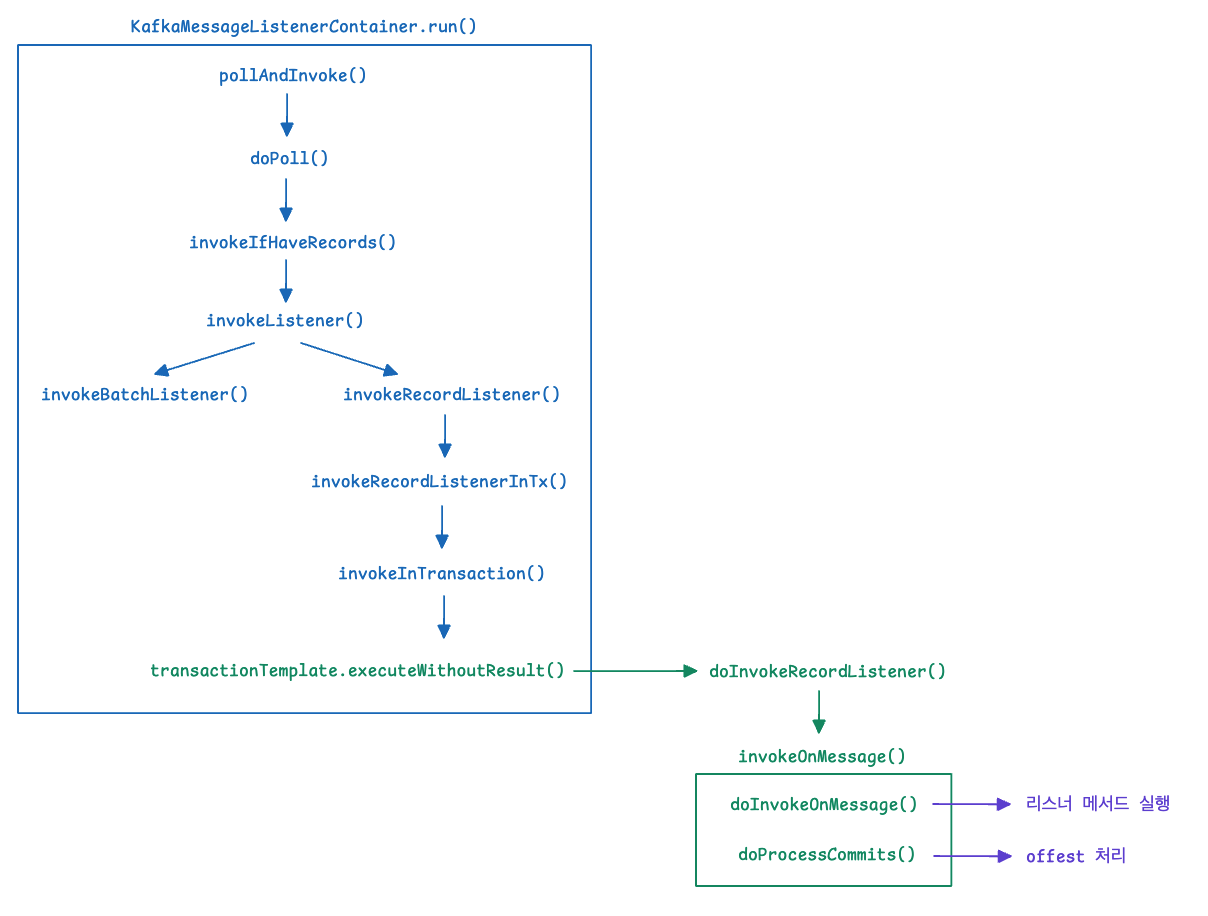
KafkaMessageListenerContainer
KafkaMessageListenerContainer는 단일 스레드 기반 컨테이너입니다.
- 하나의 Kafka Consumer
- 하나의 스레드
- 할당된 모든 토픽/파티션을 순차적으로 처리
다음은 KafkaMessageListenerContainer의 생성자로
ConsumerFactory와 토픽과 파티션에 대한 정보가 담긴 ContainerProperties 객체를 인자로 받습니다.
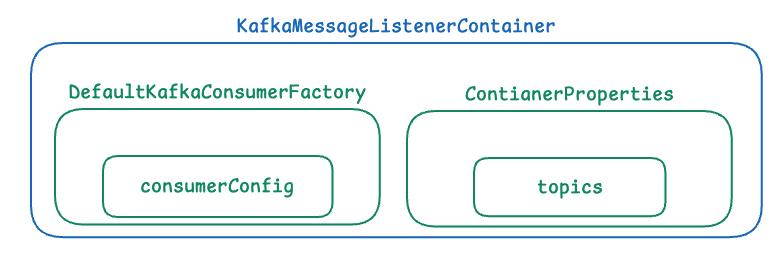
public KafkaMessageListenerContainer(ConsumerFactory<K, V> consumerFactory,
ContainerProperties containerProperties)public class DefaultKafkaConsumerFactory<K, V> extends KafkaResourceFactory
implements ConsumerFactory<K, V>, BeanNameAware, ApplicationContextAware {
public DefaultKafkaConsumerFactory(Map<String, Object> configs) {}
public DefaultKafkaConsumerFactory(Map<String, Object> configs,
@Nullable Deserializer<K> keyDeserializer,
@Nullable Deserializer<V> valueDeserializer) {}
...
}public class ContainerProperties extends ConsumerProperties {
public ContainerProperties(String... topics) {}
public ContainerProperties(TopicPartitionOffset... topicPartitions) {}
public ContainerProperties(Pattern topicPattern) {}
...
}ContainerProperties 는 다음과 같은 기능을 담당합니다.
- 로깅 설정
- 컨테이너 시작 시 설정 요약 로그 출력 (logContainerConfig)
- offset 커밋 로그 레벨 제어 (commitLogLevel)
- 토픽 존재 여부 검증
- 설정된 토픽이 broker에 없을 경우 컨테이너 시작 실패 처리 (missingTopicsFatal)
- 토픽 누락 상태를 조기에 감지 가능
- 인증 / 인가 예외 복구
- AuthenticationException, AuthorizationException 발생 시 재시도 간격 설정 (authExceptionRetryInterval)
- 권한 변경 후 컨테이너 자동 복구 지원
또한 기본적으로는 sync commit을 하며, setSyncCommits(false)로 설정하면 비동기로 커밋합니다.
public void setSyncCommits(boolean syncCommits) {
this.syncCommits = syncCommits;
}
ConcurrentMessageListenerContainer
ConcurrentMessageListenerContainer는 내부적으로 concurrency 필드값을 기준으로 여러 개의 KafkaMessageListenerContainer를 생성하여 병렬 소비를 가능하게 합니다.
public class ConcurrentMessageListenerContainer<K, V> extends AbstractMessageListenerContainer<K, V> {
private final List<KafkaMessageListenerContainer<K, V>> containers = new ArrayList<>();
private final List<AsyncTaskExecutor> executors = new ArrayList<>();
private int concurrency = 1;
/*
* Under lifecycle lock.
*/
@Override
protected void doStart() {
if (!isRunning()) {
...
for (int i = 0; i < this.concurrency; i++) {
KafkaMessageListenerContainer<K, V> container =
constructContainer(containerProperties, topicPartitions, i);
configureChildContainer(i, container);
if (isPauseRequested()) {
container.pause();
}
container.start();
this.containers.add(container);
}
}
}
...
}단, 여러 토픽과 높은 concurrency를 함께 사용할 경우 기본 파티션 할당 전략(RangeAssignor) 때문에 일부 Consumer가 idle 상태가 될 수 있습니다.
이 경우 RoundRobinAssignor 사용을 고려할 수 있습니다.
RecordInterceptor / BatchInterceptor
Spring Kafka는 메시지 처리 전후에 개입할 수 있는 Interceptor 확장 포인트를 제공합니다.
Interceptor는 리스너 호출 직전에 실행되며, record를 검사하거나 수정할 수 있습니다. 만약 interceptor가 null을 반환하면 리스너는 호출되지 않습니다.
또한 interceptor는 기본적으로 트랜잭션 시작 이전에 호출되지만, interceptBeforeTx를 false로 설정하면 트랜잭션 시작 이후에 interceptor가 실행됩니다. 이는 Kafka 전용 트랜잭션뿐 아니라, JDBC 트랜잭션 등 모든 TransactionManager에 적용됩니다.
Offsets Commit
Spring Kafka는 offset을 커밋하기 위한 여러 가지 옵션을 제공합니다.
Kafka consumer 설정에서 enable.auto.commit이 true인 경우, Kafka는 자체 설정에 따라 offset을 자동으로 커밋합니다.
반대로 enable.auto.commit이 false인 경우, Listener Container는 아래에서 설명하는 AckMode 설정을 통해 offset 커밋을 제어합니다.
- 기본 AckMode는 BATCH 입니다.
- enable.auto.commit의 기본값은 false 입니다.
다음은 AckMode별로 컨테이너가 수행하는 동작입니다.
- RECORD
각 레코드가 처리되고 리스너가 반환될 때마다 offset을 커밋합니다. - BATCH
poll()로 반환된 모든 레코드가 처리된 후 offset을 커밋합니다. - TIME
poll()로 반환된 모든 레코드가 처리된 후,
마지막 커밋 이후 경과 시간이 ackTime을 초과한 경우 커밋합니다. - COUNT
poll()로 반환된 모든 레코드가 처리된 후,
마지막 커밋 이후 ackCount만큼의 레코드가 처리된 경우 커밋합니다. - COUNT_TIME
TIME과 COUNT 조건 중 하나라도 만족하면 커밋합니다. - MANUAL
메시지 리스너가 Acknowledgment.acknowledge()를 직접 호출해야 합니다.
이후 커밋 동작은 BATCH와 동일한 방식으로 처리됩니다. - MANUAL_IMMEDIATE
리스너가 acknowledge()를 호출하는 즉시 offset을 커밋합니다.
트랜잭션을 사용하는 경우, offset은 트랜잭션에 함께 전송되며 리스너 타입(record / batch)에 따라 RECORD 또는 BATCH와 동일한 의미를 가집니다.
Acknowledgment
Acknowledgment는 Spring Kafka에서 Listener가 offset 커밋 시점을 직접 제어할 수 있도록 제공되는 인터페이스입니다.
Listener 메서드에 Acknowledgment를 인자로 받으면, acknowledge() 호출 시점에 해당 레코드(또는 배치)의 offset이 커밋됩니다.
이 방식은 AckMode.MANUAL 또는 AckMode.MANUAL_IMMEDIATE에서 사용되며, 메시지 처리 성공 이후에만 offset을 커밋함으로써 보다 안전한 메시지 처리 흐름을 구성할 수 있습니다.
public interface Acknowledgment {
void acknowledge();
default void nack(Duration sleep) {
throw new UnsupportedOperationException("nack(sleep) is not supported by this Acknowledgment");
}
default void acknowledge(int index) {
throw new UnsupportedOperationException("ack(index) is not supported by this Acknowledgment");
}
default void nack(int index, Duration sleep) {
throw new UnsupportedOperationException("nack(index, sleep) is not supported by this Acknowledgment");
}
default boolean isOutOfOrderCommit() {
return false;
}
}
리스너에서 nack()를 호출하면, 이미 성공적으로 처리된 레코드의 offset은 커밋되고, 실패한 레코드와 그 이후 레코드는 다음 poll()에서 다시 전달됩니다.
- nack(long sleep) → record 리스너용
- nack(int index, long sleep) → batch 리스너용
@KafkaListener
@KafkaListener는 지정된 토픽의 Kafka 메시지를 수신하는 메서드를 리스너 대상으로 표시하는 애노테이션입니다.
containerFactory() 속성은 Kafka 리스너 컨테이너를 생성하는 데 사용할 KafkaListenerContainerFactory를 지정합니다.
이를 설정하지 않으면, 기본적으로 빈 이름이 kafkaListenerContainerFactory인 컨테이너 팩토리가 존재한다고 가정합니다.
단, 설정을 통해 명시적인 기본값이 제공된 경우에는 그 설정이 사용됩니다.
@KafkaListener 애노테이션의 처리는 KafkaListenerAnnotationBeanPostProcessor를 등록함으로써 수행됩니다.
이 등록은 다음 두 가지 방식으로 할 수 있습니다.
- 수동으로 직접 등록
- @EnableKafka 애노테이션을 사용
@KafkaListener가 적용된 메서드는 MessageMapping과 유사한 유연한 메서드 시그니처를 가질 수 있으며,
다음과 같은 인자 타입들이 지원됩니다.
- ConsumerRecord
→ 원본 Kafka 메시지에 직접 접근 - Acknowledgment
→ 수동 offset 커밋을 위한 acknowledgment 제어 - @Payload
→ 메시지 payload 바인딩 (유효성 검사 지원) - @Header
→ KafkaHeaders에 정의된 특정 헤더 값 추출 - @Headers
→ 반드시 java.util.Map 타입이어야 하며, 모든 헤더에 접근 가능 - MessageHeaders
→ 전체 메시지 헤더 접근 - MessageHeaderAccessor
→ 메서드 인자 전반에 대한 편리한 접근 제공
메서드 레벨에 선언
@KafkaListener가 메서드 레벨에 선언되면, 각 메서드마다 개별 리스너 컨테이너가 생성됩니다.
이때 사용되는 리스너는 MessageListener 타입이며, 내부적으로는 MessagingMessageListenerAdapter가 사용됩니다.
이 어댑터는 KafkaListenerAnnotationBeanPostProcessor에서 생성한 MethodKafkaListenerEndpoint로부터 구성됩니다.
클래스 레벨에 선언
@KafkaListener가 클래스 레벨에 선언된 경우, 해당 클래스 전체에 대해 하나의 메시지 리스너 컨테이너만 생성되고 클래스 내에서 @KafkaHandler가 붙은 모든 메서드는 이 단일 컨테이너를 통해 서비스됩니다. 이 경우 사용되는 리스너 어댑터는
MessagingMessageListenerAdapter이며, MultiMethodKafkaListenerEndpoint로부터 구성됩니다.
다음은 @KafkaListener에 의해서 리스너 컨테이너가 생성되는 과정을 그린 것입니다.
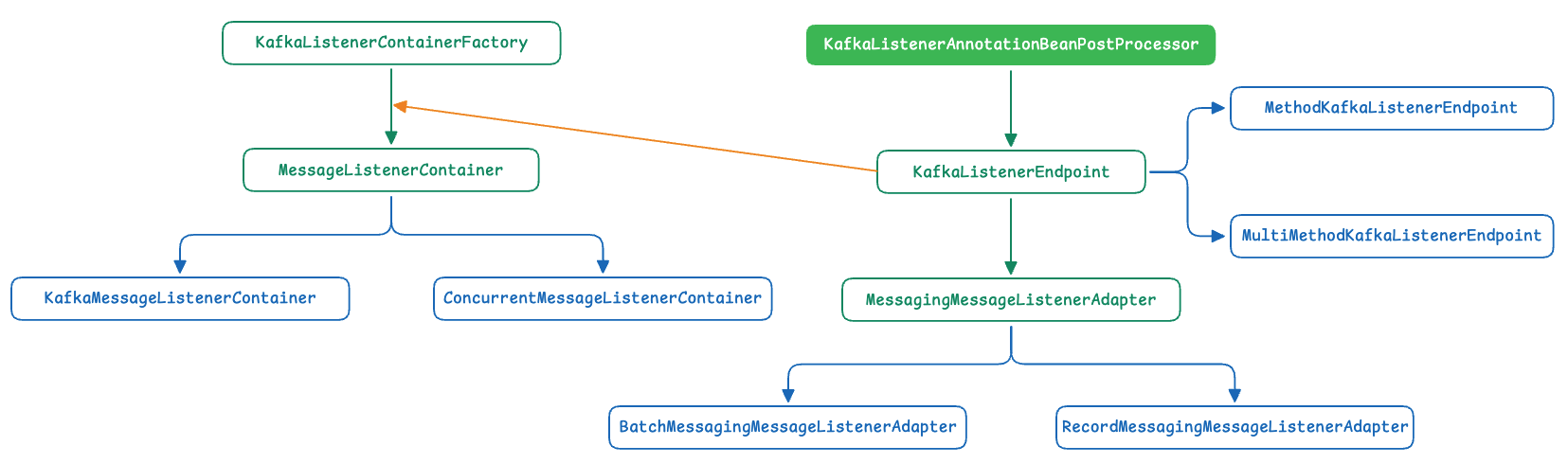
- @KafkaListener가 선언된 메서드는 KafkaListenerAnnotationBeanPostProcessor에 의해 분석되어 KafkaListenerEndpoint로 추상화됩니다.
- 이 Endpoint는 메시지를 실제 메서드 호출로 연결하기 위해 MessagingMessageListenerAdapter로 구성되며,
레코드 단위 또는 배치 단위 처리 여부에 따라 Record 또는 Batch 어댑터로 분기됩니다. - 이후 KafkaListenerContainerFactory는 해당 Endpoint를 기반으로 MessageListenerContainer를 생성하며,
생성된 컨테이너는 KafkaListenerEndpointRegistry에 등록되어 애플리케이션 전반의 라이프사이클 관리를 받습니다.
@KafkaListener 라이프사이클
@KafkaListener 애노테이션으로 생성되는 리스너 컨테이너는 스프링 애플리케이션 컨텍스트의 일반적인 Bean으로 등록되지 않습니다.
대신, 이 컨테이너들은 프레임워크가 자동으로 등록하는 KafkaListenerEndpointRegistry라는 인프라스트럭처 Bean에 의해 관리됩니다.
public class KafkaListenerEndpointRegistry implements ListenerContainerRegistry, DisposableBean, SmartLifecycle,
ApplicationContextAware, ApplicationListener<ContextRefreshedEvent> {
private final Map<String, MessageListenerContainer> listenerContainers = new ConcurrentHashMap<>();
@Override
public void start() {
for (MessageListenerContainer listenerContainer : getListenerContainers()) {
startIfNecessary(listenerContainer);
}
this.running = true;
}
private void startIfNecessary(MessageListenerContainer listenerContainer) {
if ((this.contextRefreshed && this.alwaysStartAfterRefresh) || listenerContainer.isAutoStartup()) {
listenerContainer.start();
}
}
@Override
public void stop() {
this.running = false;
for (MessageListenerContainer listenerContainer : getListenerContainers()) {
listenerContainer.stop();
}
}
...
}
레지스트리는 등록된 컨테이너들을 일괄적으로 시작하거나 중지할 수 있습니다.
시작할 때는 컨테이너 중 autoStartup = true 인 것들을 자동 시작하는데, 리스너 컨테이너는 SmartLifecycle을 구현하며 autoStartup의 기본값은 true 입니다.
public interface SmartLifecycle extends Lifecycle, Phased {
int DEFAULT_PHASE = Integer.MAX_VALUE;
default boolean isAutoStartup() {
return true;
}
default boolean isPauseable() {
return true;
}
default void stop(Runnable callback) {
this.stop();
callback.run();
}
default int getPhase() {
return Integer.MAX_VALUE;
}
}
Transactions
Spring for Apache Kafka는 다음과 같은 방식으로 Kafka 트랜잭션을 지원합니다.
- KafkaTransactionManager
- Spring의 PlatformTransactionManager 구현체
- @Transactional, TransactionTemplate과 함께 사용 가능
- 트랜잭션을 지원하는 MessageListenerContainer
- KafkaTemplate 기반 로컬 트랜잭션
- DB 트랜잭션과 Kafka 트랜잭션 간 동기화
이를 통해 Producer 중심 트랜잭션뿐 아니라, Consumer가 시작점이 되는 트랜잭션 흐름도 구성할 수 있습니다.
트랜잭션 활성화
Kafka 트랜잭션은 DefaultKafkaProducerFactory에 transactionIdPrefix를 설정함으로써 활성화됩니다.
이 설정이 적용되면 ProducerFactory는 단일 Producer를 공유하지 않고, 트랜잭션 전용 Producer들을 캐시 형태로 관리합니다.
그래서 Producer를 close() 하더라도 실제로 종료되지 않고, 다시 사용할 수 있도록 캐시에 반환됩니다.
스프링부트를 사용한다면 다음과 같이 properties 설정을 해줌으로써 간단하게 transactionIdPrefix를 설정할 수 있습니다.
spring:
kafka:
producer:
transaction-id-prefix: tx-
KafkaTransactionManager
KafkaTransactionManager는 Spring의 PlatformTransactionManager 구현체로, 일반적인 Spring 트랜잭션(@Transactional, TransactionTemplate 등)과 동일한 방식으로 사용할 수 있습니다.

KafkaAutoConfiguration을 확인해보면 앞서 살펴보았듯이 Property 설정이 있을 때만 빈이 등록되며, 생성자로 ProducerFactory를 받는 것을 알 수 있습니다.
@AutoConfiguration
@ConditionalOnClass(KafkaTemplate.class)
@EnableConfigurationProperties(KafkaProperties.class)
@Import({ KafkaAnnotationDrivenConfiguration.class, KafkaStreamsAnnotationDrivenConfiguration.class })
@ImportRuntimeHints(KafkaAutoConfiguration.KafkaRuntimeHints.class)
public final class KafkaAutoConfiguration {
@Bean
@ConditionalOnProperty(name = "spring.kafka.producer.transaction-id-prefix")
@ConditionalOnMissingBean
KafkaTransactionManager<?, ?> kafkaTransactionManager(ProducerFactory<?, ?> producerFactory) {
return new KafkaTransactionManager<>(producerFactory);
}
...
}
Producer-Only Transactions
Producer-Only Transactions는 메시지 소비(Consumer)는 트랜잭션과 직접적인 관련이 없으며, Producer 관점에서만 Kafka 트랜잭션이 사용됩니다.
1. @Transactional + KafkaTemplate
- Transaction Synchronization
- DB 트랜잭션 하나만 존재하며, Kafka 트랜잭션은 별도로 시작되지 않습니다.
- KafkaTemplate은 현재 활성화된 트랜잭션의 커밋/롤백 시점에 동기화되어 메시지를 전송합니다.
// DB Commit -> Kafka Commit
@Transactional("dstm")
public void process(List<Thing> things) {
things.forEach(thing ->
kafkaTemplate.send("topic", thing)
);
updateDb(things);
}
2. Outer @Transactional + Inner @Transactional
- DB 트랜잭션과 Kafka 트랜잭션이 각각 독립적으로 생성됩니다.
- Spring이 두 트랜잭션의 시작·커밋 순서만 관리하며, 실제 트랜잭션은 분리되어 있습니다.
// Kafka Commit -> DB Commit
@Transactional("dstm")
public void process(List<Thing> things) {
things.forEach(thing ->
this.sendToKafka(thing);
);
updateDb(things);
}
@Transactional("kafkatm")
public void sendToKafka(Thing thing) {
kafkaTemplate.send("topic", thing);
}
Consumer-Initiated Transactions
Consumer-Initiated Transactions는 Kafka Consumer가 트랜잭션의 시작점이 되어,
consume → process → produce → offset commit을 원자적으로 처리하는 방식입니다.
이는 Kafka의 Exactly-Once Semantics(EOS)를 구성하는 핵심 요소로, Kafka는 다음 두 가지를 결합합니다.
| 요소 | 역할 |
| Transactional Producer | 결과 메시지의 원자성 보장 |
| Transactional Offset Commit | “처리 완료된 메시지만 커밋” 보장 |
- 트랜잭션이 커밋되면
→ 메시지 발행 + offset 커밋이 모두 반영 - 트랜잭션이 롤백되면
→ 메시지도 없고, offset도 커밋되지 않음
즉, 동일 메시지가 다시 소비될 수는 있어도, 처리 결과(write + offset-commit)는 한 번만 반영됩니다.
다음은 KafkaAnnotationDrivenConfiguration 의 소스 코드 일부로,
ListenerContainerFactoryConfigurer에서 TransactionManager를 설정하고 ListenerContainerFactory 빈을 만드는 것을 확인할 수 있습니다.
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(EnableKafka.class)
class KafkaAnnotationDrivenConfiguration {
...
@Bean
@ConditionalOnMissingBean
@ConditionalOnThreading(Threading.PLATFORM)
ConcurrentKafkaListenerContainerFactoryConfigurer kafkaListenerContainerFactoryConfigurer() {
return configurer();
}
private ConcurrentKafkaListenerContainerFactoryConfigurer configurer() {
ConcurrentKafkaListenerContainerFactoryConfigurer configurer = new ConcurrentKafkaListenerContainerFactoryConfigurer();
configurer.setKafkaProperties(this.properties);
configurer.setBatchMessageConverter(this.batchMessageConverter);
configurer.setRecordMessageConverter(this.recordMessageConverter);
configurer.setRecordFilterStrategy(this.recordFilterStrategy);
configurer.setReplyTemplate(this.kafkaTemplate);
configurer.setTransactionManager(this.transactionManager); // TransactionManager
configurer.setRebalanceListener(this.rebalanceListener);
configurer.setCommonErrorHandler(this.commonErrorHandler);
configurer.setAfterRollbackProcessor(this.afterRollbackProcessor);
configurer.setRecordInterceptor(this.recordInterceptor);
configurer.setBatchInterceptor(this.batchInterceptor);
configurer.setThreadNameSupplier(this.threadNameSupplier);
return configurer;
}
@Bean
@ConditionalOnMissingBean(name = "kafkaListenerContainerFactory")
ConcurrentKafkaListenerContainerFactory<?, ?> kafkaListenerContainerFactory(
ConcurrentKafkaListenerContainerFactoryConfigurer configurer,
ObjectProvider<ConsumerFactory<Object, Object>> kafkaConsumerFactory,
ObjectProvider<ContainerCustomizer<Object, Object, ConcurrentMessageListenerContainer<Object, Object>>> kafkaContainerCustomizer) {
ConcurrentKafkaListenerContainerFactory<Object, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();
configurer.configure(factory, kafkaConsumerFactory
.getIfAvailable(() -> new DefaultKafkaConsumerFactory<>(this.properties.buildConsumerProperties())));
kafkaContainerCustomizer.ifAvailable(factory::setContainerCustomizer);
return factory;
}
@Configuration(proxyBeanMethods = false)
@EnableKafka
@ConditionalOnMissingBean(name = KafkaListenerConfigUtils.KAFKA_LISTENER_ANNOTATION_PROCESSOR_BEAN_NAME)
static class EnableKafkaConfiguration {
}
}
이제 전체적인 흐름을 정리해보면,
앞서 살펴본 것처럼 @KafkaListener가 등록되면서 이에 대응하는 MessageListenerContainer가 생성됩니다.
이후 컨테이너는 autoStartup 설정에 따라 자동으로 시작되며, 내부적으로 listenerContainer.run()이 실행되면서 Kafka 메시지 소비 루프가 본격적으로 동작하게 됩니다.