

Go 는 객체지향 언어인가?
어떤 사람은 Go 언어는 객체지향 언어가 아니라고 말합니다. 그 이유는 객체지향 언어들의 특징인 상속을 지원하지 않기 때문입니다. 결론부터 말씀드리자면 Go 언어는 객체지향 언어입니다. 객체지향 언어는 상속 지원 여부보다, 말 그대로 객체 간의 상호작용을 중심으로 한 프로그래밍에 있습니다. Go 언어는 상속을 지원하는 다른 언어보다 발전한 형태의 객체지향 언어입니다. 그 이유는 상속이 객체지향 설계를 깰 수 있는 많은 문제점을 갖고 있는데, 이를 지원하지 않아 문제를 미연에 방지했기 때문입니다.
상속
상속(inheritance)이란 기존 객체를 확장하여 새로운 객체를 정의하는 기능을 말합니다. 프로그래밍을 할 때 공통으로 포함되는 기능을 여러 객체가 공유해야 하는 경우가 발생합니다. 이러한 공통 기능을 하나의 부모 객체로 묶고 나머지는 이 객체를 확장하는 방식으로 사용하는 게 상속입니다.
메서드 오버라이딩
메서드 오버라이딩(method overriding)이란 자식 객체에서 부모 객체의 메서드 기능을 변경하여 다시 정의하는 행위를 말합니다. 위 상속에서 말한 공통 기능을 부모 객체에 정의했는데, 이것을 그대로 사용하는 것이 아닌 덮어써서 새로운 기능으로 정의할 수 있도록 한 것이 메서드 오버라이딩입니다.
상속의 문제점
위에서 상속에 대해 간단히 살펴보았습니다. 얼핏 봐서는 굉장히 좋은 기능처럼 보이지만, 어떠한 문제점들이 있는지 알아보겠습니다.
다이아몬드 상속 문제

다중 상속을 통한 다이아몬드 상속은 상속의 고질적인 문제로써 이 문제를 없애고자 많은 언어가 다중 상속 자체를 금지합니다.
A를 B, C가 상속하고, D가 B, C를 다중 상속합니다. 만약 A의 메서드를 B, C에서 각각 오버라이딩을 했다면 D는 어떤 메서드를 실행해야 할까요?
또 일부 언어에서는 다중 상속 시 내부 메모리 블록이 이중으로 포함되는 문제가 발생합니다. 이런 이유로 많은 언어에서 다중 상속을 금지합니다.
리스코프 치환(LSP) 원칙 위배
상속은 리스코프 치환 원칙을 위배하기 쉽습니다. 오버라이딩으로 부모 클래스의 메서드와 자식 클래스의 오버라이딩한 메서드가 서로 다른 동작을 하게 만들 수 있습니다. 이 경우 함수 동작이 예기치 않게 변화되어 버그가 발생할 수 있습니다. 더 큰 문제는 실무 코드는 상속 관계가 복잡하게 얽혀 있어 코드만 봐서는 어디서 문제가 발생한 것인지 찾기 어렵다는 데 있습니다.
강력한 의존 관계
상속을 하게 되면 부모 타입과 자식 타입 간 의존 관계가 형성됩니다. 객체 간 관계는 Is-a 관계와 Has-a 관계로 나타낼 수 있습니다. Is-a 관계는 두 객체가 상속 관계를 맺고 있을 때이고, Has-a 관계는 두 객체가 포함 관계를 맺고 있을 때입니다. 상속 관계를 Is-a 라고 부르는 이유는 자식 객체가 부모 타입 인스턴스로 사용될 수 있기 때문입니다. 그리고 포함 관계는 말 그대로 내부 필드로 인스턴스를 갖고 있기 때문에 Has-a 라고 부릅니다.
일반적으로 상속 관계를 지양하고 포함 관계를 지향해야 한다고 말합니다. 그 이유는 상속 관계가 의존성 문제를 더 많이 일으키기 때문입니다. 예를 들어서 확인해보겠습니다.
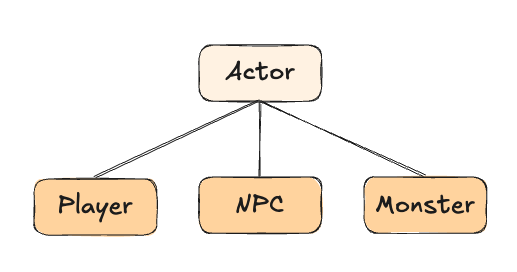
부모 객체인 Actor를 상속하는 Player, NPC, Monster 가 있습니다. 이 중에서 Player, NPC는 대화가 가능하기 때문에 대화 기능을 추가하려고 합니다.
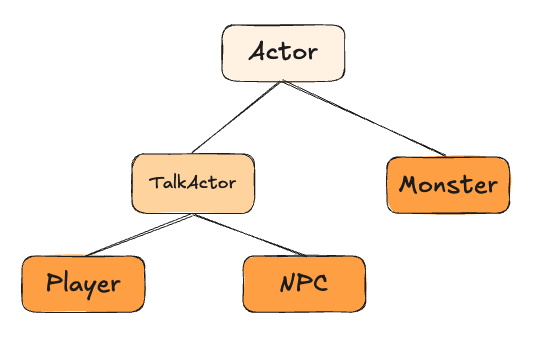
중복 코드를 없애기 위해 상속을 사용하면 왼쪽과 같이 상속 관계가 변경됩니다. 그런데 Monster와 Player는 전투가 가능하기 때문에 전투 기능을 추가하려고 합니다.
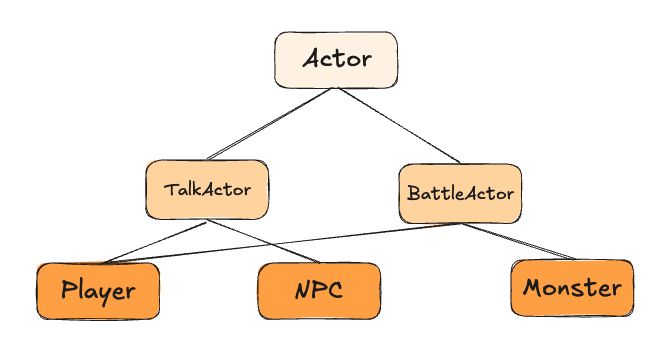
마지막으로 전투 기능까지 추가하여 상속 관계를 구현하면 위와 같이 다중 상속을 하게 됩니다. 이것은 앞에서 알아보았던 다이아몬드 상속 문제를 일으킵니다. 상속이 의존 관계를 만들기 때문에 서로 묶이게 되어 분리하기가 힘들어집니다.
이 문제를 포함 관계로 했을 때는 어떻게 되는지 확인해보겠습니다.

그저 해당 기능을 담당하는 객체를 포함하기만 하면 되기 때문에 매우 간단하게 표현이 가능합니다. 각 기능이 달라지더라도 서로 포함된 객체만 바꿔주면 되기 때문에 전혀 문제 없습니다. 이러한 포함 관계의 더 큰 장점은 추상 객체로 의존성 역전을 하기 편하다는 점입니다.
다음과 같이 Actor, Talk, Battle을 구체화된 객체가 아닌 인터페이스로 구현하면 서로의 의존성을 더 끊어낼 수 있습니다.

위 그림처럼 추상 계층으로 의존성 역전을 하면 각각에 맞는 구현체를 사용하도록 할 수 있습니다.
구조체에 생성자를 둘 수 있나?
Go 언어에서는 구조체의 생성자 메서드를 지원하지 않습니다. 그래서 구조체 생성 시 초기화 로직을 명시할 수 없습니다. 일반적으로 패키지를 만들 때 외부에 공개되는 구조체 인스턴스를 생성하는 생성 함수를 만들기도 하지만 꼭 그 생성 함수를 이용해야지만 구조체를 만들 수 있는 건 아닙니다. 예를 들어 bufio 패키지의 Scanner는 Scanner 객체를 생성하는 NewScanner() 라는 생성 함수를 제공하지만 그냥 Scanner{}를 해도 객체를 만들 수 있습니다.
scanner1 := bufio.NewScanner(os.Stdin)
scanner2 := bufio.Scanner{}
다만 이렇게 Scanner{}를 통해 생성한 객체는 제대로 동작하지 않는 객체입니다.
이렇게 패키지 외부로 공개되는 구조체의 경우 별도의 생성 함수를 제공하더라도 패키지 이용자에게 꼭 생성 함수를 이용하도록 문법적으로 강제할 방법은 없습니다. 그게 해당 객체를 올바르게 생성하는 방법이 아닐지라도 말입니다.
해결책으로 구조체를 외부로 공개하지 않고 인터페이스만 공개하는 방법이 있습니다. 그러면 생성 함수를 이용하지 않고는 객체 인스턴스를 생성하지 못하도록 강제할 수 있습니다.
예시를 만들어 확인해 보겠습니다.
package backaccount
type Accout interface {
Balance() int
}
func NewAccount() Account {
return &innerAccount{ balance: 1000 }
}
type innerAccount struct {
balance int
}
func (a *innerAccount) Balance() int {
return a.balance
}
이렇게 외부로 공개하는 Account는 인터페이스로 제공하고, 내부의 구조체는 innerAccount를 정의했습니다.
다음은 위 패키지를 사용하는 코드를 만들어 보겠습니다.
package main
import "bankaccount"
func main() {
account := bankaccount.NewAccount()
account.Balance()
}
이렇게 패키지 외부에서 특정 함수를 사용해서 구조체를 생성하도록 강제할 수는 있지만, 일반적으로 많이 사용되는 방법은 아닙니다.
값 타입과 포인터
Go 언어에서 변수 간 값의 전달은 타입에 상관없이 항상 복사로 일어납니다. 대입 연산자(=)는 우변의 값을 좌변 변수(메모리 공간)에 복사합니다.
아래 코드에서 Student 객체 s의 주소를 Student 포인터 p에 대입합니다. 이때 값은 &s 즉 s의 메모리주소이고 이것 또한 숫자로 표현됩니다. 그래서 s의 메모리 주소를 나타내는 숫자값을 p의 메모리 공간에 복사하게 됩니다. 복사할 때는 타입의 크기만큼 복사하게 되는데 메모리 주소의 크기는 64비트 컴퓨터에서는 64비트(8바이트)가 됩니다.
type Student struct {
name string
age int
}
func main() {
var s Student
var p *Student
p = &s
}
다음은 배열과 슬라이스의 복사입니다. 배열을 복사한 b의 경우 int 타입 5개 만큼 즉 64비트 컴퓨터 기준으로 8바이트 * 5 인 40바이트가 복사됩니다. 반면에 슬라이스는 가리키는 배열의 크기가 얼마던지 상관없이 3개의 필드를 갖는 구조체를 복사하게 됩니다. 실제 배열을 가리키는 포인터(메모리 주소: 8바이트)와 int 타입 필드 2개를 합쳐서 총 24바이트가 일정하게 복사됩니다.
func main() {
var array [5]int = [5]int{1, 2, 3, 4, 5}
var b [5]int
b = array // 배열
var c []int
c = array[:] // 슬라이스
}type SliceHeader struct {
Data uintptr
Len int
Cap int
}Go언어는 함수 호출 시에 인수값도 항상 복사로 전달됩니다.
값 타입을 쓸 것인가? 포인터를 쓸 것인가?
구조체 객체 인스턴스를 값 타입으로 사용해야 할까요? 아니면 포인터로 사용해야 할까요?
type Temperature struct {
Value int
Type string
}
func NewTemperature(v int, t string) Temperature { // 값 타입
return Temperature( Value: v, Type: t }
}
type Student struct {
Age int
Name string
}
func NewStudent(age int, name string) *Student { // 포인터
return &Student{ Age: age, Name: name }
}
위 코드는 Temperature과 Student 각각 값 타입과 포인터로 사용된 예제입니다. 타입 선언만 보면 별반 차이가 없지만 메서드를 확인해보면 값 타입과 포인터로 사용되는 것을 구분할 수 있습니다.
성능 차이
우선 두 구조체는 복사되는 크기가 다르기는 합니다. 앞서 살펴보았듯이 모든 대입은 복사로 일어나고 복사되는 크기는 타입 크기와 같습니다. 모든 포인터의 크기는 메모리 주소 크기인 8바이트로 고정되지만, 값 타입은 모든 필드 크기를 합친 크기가 됩니다. 그래서 *Student는 복사할 때마다 항상 8바이트씩 복사되지만, 값 타입으로 사용되는 Temperature는 모든 필드 크기의 합인 24바이트가 복사됩니다. 사실 8바이트와 24바이트면 3배나 차이나서 커보이지만 전체 메모리 공간에 비하면 작고 성능에 미치는 영향도 거의 없습니다.
Go 언어에서는 메모리를 많이 차지하는 슬라이스, 문자열, 맵 등이 모두 내부 포인터를 가지는 형태로 제작되어 있어 값 복사에 따른 메모리 낭비를 걱정하지 않으셔도 됩니다.
그래서 값 타입으로 사용될 때보다 포인터로 사용될 때 복사되는 크기 면에서 포인터가 더 효율적이지만 실제로는 거의 차이가 없다라고 볼 수 있습니다.
하지만 포인터로 사용되는게 더 효율적이다 라고 말할 수는 없습니다. 단지 메모리가 복사되는 크기 면에서 효율적이라는 것이고, 오히려 메모리의 간접 주소 지정으로 인한 CPU의 추가적인 메모리 접근을 유도하여 메모리 접근 비용을 증가시킬 수도 있습니다. 또한 값 타입은 대부분 스택(stack)에 할당되어 GC의 관리 대상이 아니지만, 포인터를 사용하는 객체들은 힙(heap)에 할당되는 경우가 많은데 이는 그만큼 GC에게 부담을 줄 수 있다는 의미입니다.
선택 기준
값 타입과 포인터의 선택 기준은 객체 성격에 따라 결정하는 것이 좋습니다. 위 예시에서 Temperature은 10도의 Temperature과 여기에 5도를 더한 15도의 temperature은 엄연히 다른 온도이기 때문에 서로 다른 객체가 되는 것이 맞을 겁니다. 반면 Student는 10살인 학생이 5살을 더 먹어서 15살이 되었다고 다른 학생으로 변하지는 않습니다. 즉 내부 상태가 바뀌어도 여전히 객체가 유지되기 때문에 Student는 포인터가 더 어울린다고 볼 수 있습니다.
사실 Go 언어세서는 어떤 타입이 값 타입인지 포인터인지 강제하고 있지 않습니다. 심지어 그 둘을 섞어서 사용해도 문접적으로 아무 문제가 없습니다. 다만 개발자가 타입을 만들고 메서드를 정의할 때 이 타입을 값 타입으로 사용할지 포인터로 사용할지 정할 뿐입니다. 하지만 값 타입과 포인터는 엄연히 성격이 다르기 때문에 객체를 정의할 때 둘을 섞어 쓰기보다는 값 타입이나 포인터 중 하나만 사용하는 것이 좋습니다.
구체화된 객체와 관계해라
5가지 객체지향 원칙 중 의존 관계 역전 원칙(dependency inversion principle: DIP)에 의하면 구체화된 객체와 관계를 맺지 말고 추상화된 객체와 관계를 맺으라고 설명합니다. 이번에는 그 반대로 구체화된 객체와 관계하라는 얘기를 해보겠습니다.
오늘날에는 객체지향 설계가 보편화되고 좋은 디자인 패턴들도 사용됩니다. 그런데 오히려 모든 관계를 추상화하다 보니 객체 간 관계가 감춰져서 코드 동작 구조를 파악하기 어려워지는 문제가 생겨났습니다. 또 추상화된 설계를 강조하다 보니 설계에 너무 많은 정성을 쏟게 되어 프로젝트 일정과 비용이 늘어나는 결과를 만들었습니다. 이렇게 필요없는 오버스펙으로 프로젝트 시간과 비용을 증가시키는 것을 벽에 금 페인트를 칠한 것과 같다고 해서 gold painting이라고 말합니다.
스타트업 프로젝트가 늘어나면서 이제는 프로그래밍 품질도 중요하지만 생성성이 더 중요해졌습니다. 빠르게 만들고 빠르게 시장의 검증을 받는 것이 중요해졌습니다. 그래서 "망할거면 빨리 망하자" 라는 신조가 생겨날만큼, 빠르게 제작하고 시장에서 어느 정도 성공을 거두면 그때부터 계속 유지보수하면서 지속적으로 개선되는 프로그래밍이 중요한 시대가 됐습니다.
Go 언어는 덕 타이핑을 지원하기 때문에 구체화된 객체로 빠르게 제작하고 유지보수가 필요할 때마다 기존 객체를 수정하지 않고 인터페이스만 추가해서 의존 관계를 역전시킬 수 있습니다. 즉 높은 생산성과 지속적 개선에 너무 잘 맞는 프로그래밍 언어입니다. 적어도 Go 프로그래밍에서는 구체화된 객체와 관계 맺기를 걱정하지 말라고 말할 수 있습니다.
아래와 같이 아이템 구매 기능을 담당하는 모듈이 있다고 가정해보겠습니다. 미 모듈을 사용할 때 굳이 인터페이스를 만들지 않고 구체화된 객체를 바로 사용해서 빠르게 제작했습니다.
type Marketplace struct {
}
func NewMarketplace() *Marketplace {
}
func (m *Marketplace) PurchaseItem() *tem.Item {
}
func main() {
ma := marketplace.NewMarketplace()
mp.PurchaseItem()
}
추후에 Marketplace 기능이 확장되거나 다른 업체 서비스로 변경되어야 한다면 이제 인터페이스를 만들어서 의존 관계를 역전시키면 됩니다. Go 언어는 덕 타이핑을 지원하기 때문에 기존의 구체화된 객체를 수정할 필요없이 이용자 쪽에서 인터페이스를 정의해서 사용할 수 있습니다.
type ItemPurchaser interface {
PurchaseItem() *item.Item
}
func main() {
var purchaser ItemPurchaser
purchaser = marketplace2.NewMarketplace()
purchaser.PurchaseItem()
}
가비지 컬렉터
가비지 컬렉터는 불필요한 메모리를 청소해서 재사용할 수 있게 해줍니다. Go 언어는 가비지 컬렉터를 지원합니다. C/C++ 언어는 가비지 컬렉터를 지원하지 않기 때문에 메모리를 개발자가 직접 관리해야 합니다. 이로 인해 메모리를 할당하고 지우지 않아서 메모리가 부족해지는 문제, 이미 지운 메모리를 다시 지우는 문제, 이미 지운 메모리를 다른 객체가 가리키고 있어서 엉뚱한 데이터를 가져오는 문제 등이 발생합니다.
C/C++ 이후에 가비지 컬렉터를 지원하는 많은 언어가 등장해서 개발자를 메모리 관리로부터 해방시켜주었습니다 .하지만 가비지 컬렉터에 장점만 있는 것은 아닙니다. 가장 큰 문제는 필요없어진 인스턴스를 찾고 메모리를 정리하는 데 CPU를 사용해 선응 저하, 프로그램 멈춤, 사용 메모리 상승 등의 문제가 발생한다는 겁니다.
가비지 컬렉터 알고리즘을 간단히 살펴보고 Go 언어에서 제공하는 가비지 컬렉터에 대해서 알아보겠습니다.
알고리즘
표시하고 지우기
표시하고 지우기(mark and sweep)은 단순한 알고리즘입니다. 모든 메모리 블록을 검사해서 사용하고 있으면 1, 아니면 0으로 표시한 뒤, 0으로 표시된 모든 메모리 블록을 삭제하는 방식입니다. 구현이 편하다는 장점이 있지만, 모든 메모리 블록을 전수 검사해야 하기 때문에 CPU 성능이 많이 필요하고, 검사하는 도중 메모리 상태가 변하면 안 되기 때문에 프로그램을 멈추고 검사해야 한다는 단점이 있습니다.
삼색 표시
삼색 표시(tri-color mark and sweep)는 메모리 블록에 색깔을 칠하는 방식입니다. (실제로 색을 칠하는 것은 아니고 0, 1, 2로 표시합니다.) 표시하고 지우기 방식에서 조금 더 발전한 방식으로, 회색은 아직 검사하지 않은 메모리, 흰색은 아무도 사용하지 않는 블록, 검은색은 이미 검사가 끝낸 블록을 나태냅니다.
방법은 단순합니다. 아무거나 회색 블록을 찾아서 검은색으로 바꾸고, 그 메모리 블록에서 참조중인 다른 모든 블록을 회색으로 바꿉니다. 이것을 모든 회색 블록이 없어질 때까지 반복합니다. 이 방식은 프로그램 실행 중에도 검사할 수 있어서 프로그램 멈춤 현상을 줄일 수 있습니다. 단점으로는 모든 메모리 블록을 검사하기 때문에 속도가 느리다는 점과 메모리 상태가 계속 변화하기 때문에 언제 메모리를 삭제할지 정하기 힘들다는 점입니다. 또, 속도가 느리기 때문에 만약 메모리를 삭제하는 속도보다 할당되는 속다가 더 빠르면 메모리가 지속적으로 증가되어서 프로그램을 완전히 멈추고 전체 검사를 해야하는 경우가 생기기도 합니다.
객체 위치 이동
객체 위치 이동(moving object)은 삭제할 메모리를 표시한 뒤 한쪽으로 몰아서 한꺼번에 삭제하는 방식입니다.

위와 같이 삭제할 메모리를 흰색으로 표시한 뒤 한쪽으로 메모리 블록을 이동한 뒤에 한꺼번에 삭제합니다. 메모리를 몰아서 지우기 때문에 메모리 단편화가 생기지 않는 장점이 있습니다.
반면 메모리 위치 이동이 쉽지 않다는 단점이 있습니다. 객체들은 서로 연관 관계를 가지고 있기 때문에 메모리 블록을 이동시키려면 모든 연관된 블록에 대한 조작을 멈춘 다음에 해야 합니다. 즉 여러 객체에 읽기/쓰기를 제한하고 난 다음에 옮겨야 하기 때문에 CPU 성능이 많이 필요하고 또 프로그래밍 언어 레벨에서 메모리 이동이 쉬운 구조를 가지고 있어야 합니다. Go 언어는 포인터를 직접 사용하는 방식의 언어이기 때문에 위치 이동이 어렵습니다.
세대 단위 수집
컴퓨터 공학자들은 다년간의 경험을 통해서 '대부분 객체는 할당된 뒤 얼마되지 않아서 삭제된다' 라는 점을 발견했습니다. 즉 대부분 객체의 수명이 짧다는 겁니다. 그래서 전체 메모리를 검사하는 게 아니라 할당된 지 얼마 안 된 메모리 블록을 먼저 검사하는 방식이 세대 단위 수집(generational garbage collection) 방식입니다.
방금 할당된 메모리를 1세대 목록에 집어넣습니다. 1세대 가비지 컬렉터가 돌면 1세대 목록을 검사해서 불필요한 메모리를 삭제합니다. 그리고 살아남은 블록은 2세대 목록으로 옮깁니다. 이런식으로 3세대, 4세대까지 늘어날 수 있습니다.
1세대 가비지 컬렉터를 자주 돌리고, 세대가 깊어질수록 가비지 컬렉터를 돌리는 간격을 늘립니다. 이렇게 하면 세대를 분리했기 때문에 각 가비지 컬렉터 수행 시간이 짧아져서 더 효율적으로 가비지 컬렉팅을 할 수 있습니다.
단점은 구현이 복잡해지는 점과 역시 메모리 블록을 세대별로 이동해야 하는 문제가 발생합니다.
각 알고리즘은 성격이 달라서 얻는 것이 있으면 잃는 것이 있습니다. 그래서 어떤 방식만 좋고 나머지는 나쁘다라고 할 수 없습니다.
아재 Go 언어에서 사용되는 가비지 컬렉팅 방식에 대해서 알아보겠습니다.
Go 언어 가비지 컬렉터
Go 언어 가비지 컬렉터는 계속 발전되고 있고 매우 빠른 성능을 자랑하고 있습니다. Go 언어 1.24 버전은 동시성 삼색 표시 수집(concurrent tri-color mark and sweep garbage collection) 방식을 사용합니다. 여러 고루틴에서 병렬로 삼색 검사를 한다는 뜻입니다. 즉 멈춤 시간을 매우 짧게 유지하면서 가비지 컬렉팅을 할 수 있습니다. Go 언어 가비지 컬렉팅은 세대 단위 수집 방식을 사용하지 않습니다. 그래서 메모리 이동에 따른 비용이 발생하지 않습니다. 이 결과 Go 언어 가비지 컬렉터는 한 번 돌때 1ms 미만의 프로그램 멈춤만으로 가비지 컬렉팅을 할 수 있습니다.
단점으로는 추가 힙 메모리가 필요하며 메모리 할당 속도가 빠르면 프로그램을 멈추고 전체 검사를 해야 할 수도 있기 때문에 메모리 할당을 빈번하게 하는 것은 좋지 않습니다.
쓰레기 줄이기
쓰레기 분리수거보다 중요한 건 쓰레기 자체를 줄이는 겁니다. 마찬가지로 가비지 컬렉터가 아무리 빨라도 가비지 자체를 줄이는 게 더 효율적입니다. 메모리 쓰레기를 줄이는 방법을 살펴보겠습니다.
1. 불필요한 메모리 할당을 없앤다
슬라이스가 append()에 의해서 크기가 증가될 때 2배 크기에 해당하는 배열을 할당해서 사용합니다. 이때 불필요한 메모리 할당을 발생할 수 있습니다. capacity 0인 슬라이스에 1000개의 요소를 추가하면 대략 11번의 메모리 할당이 일어나는 반면 capacity 1000인 슬라이스에 1000개의 요소를 추가하면 처음 1번만 메모리 할당을 하면 됩니다. 이렇게 추가적으로 발생한 10번의 메모리 할당은 모두 바로 버려지는 메모리 쓰레기 입니다. 그래서 요소 개수가 예상되는 슬라이스를 만들 때는 예상 개수만큼 초기에 할당해 불필요한 메모리 할당을 줄일 수 있습니다.
또한 문자열 연산은 프로그래밍에서 빈번하게 발생하는데, 문자열은 불변이기 때문에 문자열 조작은 항상 새로운 메모리 할당을 유발합니다. 문자열을 추가할 때 string 합연산보다는 strings.Builder를 이용하는 게 좋습니다.
2. 재활용
메모리 쓰레기 역시 재활용할 수 있습니다. 자주 할당되는 객체를 객체 풀에 넣었다가 다시 꺼내 쓰면 됩니다. 이것을 flyweight 패턴 방식이라고 합니다. 객체를 사용 후 삭제하는 것이 아닌 반납을 하는 방식으로 객체가 추가로 생성되지 않습니다. 그러나 객체가 삭제되는 것이 아니라 풀에 반환되기 때문에 한 번 생성된 객체는 사라지지 않으며, 이 말은 프로그램 전체에서 동시에 사용되는 최대 개수만큼 메모리가 유지되는 문제가 있습니다. 그리고 이미 반환된 객체를 참조하지 않도록 사용하기 전에 반환된 객체인지 꼭 확인을 해야 합니다.
3. 프로파일링
go test -cpuprofile cpu.prof -memprofile mem.prof -bench .
이 명령으로 벤치마크를 수행해서 사용되는 cpu 사용량 데이터와 메모리 사용량 데이터를 얻어서 분석할 수 있습니다. 또 datadog나 goole cloud profiler 등을 통해서 실제 서비스되는 클라우드 머신의 성능을 분석할 수 있습니다.
Sort 동작 원리
sort.Sort() 함수의 정의는 다음과 같습니다.
func Sort(data sort.Interface)
sort.Interface 인터페이스를 인수로 받습니다. sort 패키지의 Interface 인터페이스 정의는 다음과 같습니다.
type Interface interface {
Len() int
Less(i, j int) bool
Swap(i, j int)
}
sort.Sort() 함수가 이 인터페이스를 인수로 받기 때문에 어떤 타입이든지 위 세 메서드만 포함하고 있으면 모두 sort.Sort() 함수 인수로 사용할 수 있습니다. 즉 개발자가 정의한 구조체도 위 세 메서드만 포함하고 있다면 Sort 인수로 사용될 수 있습니다.
하지만 []int 슬라이스는 위 세 메서드를 포함하고 있지않은데 어떻게 정렬을 해야할까요? sort.IntSlice(s) 메서드를 사용해서 []int 타입 변수를 sort.Interface를 포함한 타입으로 변환할 수 있습니다.
여기서 IntSlice()는 함수 같지만 사실은 별칭 타입입니다. 그래서 IntSlice(s)는 함수 호출이 아니라 s를 IntSlice 타입으로 타입 변환한 것입니다. IntSlice는 다음과 같은 메서드를 갖습니다.
type IntSlice []int
func (p IntSlice) Len() int { return len(p) }
func (p IntSlice) Less(i, j int) bool { return p[i] < p[j] }
func (p IntSlice) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
이런식으로 단순한 세 메서드만 만들어주면 모두 sort.Sort() 함수를 사용할 수 있습니다.
'Lang > Go' 카테고리의 다른 글
| Go (8) - Go 문법 추가 내용 (0) | 2025.04.25 |
|---|---|
| Go (7) - 테스트와 벤치마크, 웹 서버 (1) | 2025.04.17 |
| Go (6) - 고루틴과 동시성 프로그래밍, 채널과 컨텍스트, Generic (0) | 2025.04.17 |
| Go (5) - 함수 고급, 자료구조, 에러 핸들링 (0) | 2025.04.13 |
| Go (4) - 슬라이스, 메서드, 인터페이스 (0) | 2025.04.13 |