

구조체
앞서 배운 자료형 중 배열은 같은 형태의 데이터를 묶어 반복문으로 처리할 수 있는 훌륭한 자료형입니다. 그러나 배열을 사용하려면 모든 데이터의 형태가 같아야 합니다. 만약 다른 형태의 데이터를 하나로 묶어 단일 자료형으로 다룰 수 있다면 학생별로 데이터를 처리할 수 있고 반복문을 이용해 많은 학생의 데이터를 훨씬 효율적으로 처리할 수 있습니다. 이때 유용한 것이 바로 구조체입니다. 구조체는 다양한 자료형을 하나로 묶을 수 있는 복합 자료형으로 다양한 형태의 데이터를 처리할 때 기본으로 사용됩니다.
구조체 선언과 사용
구조체는 하나의 자료형으로 변수 선언이 가능하지만, 변수 선언 전에 꼭 필요한 절차가 있습니다. 구조체의 형태를 컴파일러에 미리 알려 주는 구조체 선언을 수행해야 합니다. 구조체 선언이 끝나면 새로운 자료형이 만들어지며 그 이후부터는 구조체의 변수를 사용할 수 있습니다.
#include <stdio.h>
struct student
{
int num;
double grade;
};
int main(void)
{
struct student s1;
s1.num = 2.;
s1.grade = 2.7;
printf("num, grade: %d, %.1lf\n", s1.num, s1.grade);
return 0;
}struct 예약어를 사용해 구조체를 선언하고, 구조체의 성격에 맞는 적절한 이름을 붙이고 블록 안에 멤버를 나열합니다. 멤버 선언은 구조체를 구성하는 자료형 종류와 이름을 컴파일러에 알리는 것이며 실제 저장 공간이 할당되는 변수 선언과는 다릅니다. 그리고 마지막에 블록을 닫은 후에는 반드시 세미콜론을 붙여야 합니다.
구조체 선언이 main 함수 앞에 있으면 프로그램 전체에서 사용할 수 있고, 함수 안에 선언하면 그 함수 안에서만 쓸 수 있습니다. 구조체 선언이 끝나면 그 이후부터 사용자가 정의한 새로운 자료형을 컴파일러가 인식할 수 있습니다.
구조체 선언 후 11행과 같이 구조체 변수를 선언하면 비로소 저장 공간이 할당됩니다. 각 멤버의 공간이 메모리에 연속으로 할당되며 모든 멤버를 더한 전체 저장 공간이 하나의 구조체 변수가 되므로 변수의 크기는 각 멤버의 크기를 더한 값이 됩니다.
선언된 구조체 변수는 그 안에 여러 개의 멤버를 가지므로 특정 멤버를 골라서 사용해야 하는데 이때 멤버 접근 연산자(.)가 필요합니다.
구조체 변수의 크기
모든 시스템은 데이터를 빠르게 읽고 쓰기 위해 일정한 크기 단위로 메모리에 접근합니다. 따라서 컴파일러는 구조체 멤버의 크기가 들쑥날쑥한 경우 멤버 사이에 패딩 바이트(padding byte)를 넣어 멤버를 가지런하게 정렬합니다. 이를 바이트 얼라인먼트(byte alignment)라고 합니다. 위 예시의 struct student 구조체는 grade 멤버의 크기가 가장 크므로 8바이트가 기준 단위가 됩니다. 따라서 num 멤버는 첫 번째 8바이트 블록의 처음 4바이트에 할당되고, grade 멤버는 남은 4바이트에 할당될 수 없으므로 다음 8바이트 블록에 할당됩니다. 결국 4바이트의 패딩 바이트가 포함되므로 전체 구조체의 크기는 16바이트가 됩니다.
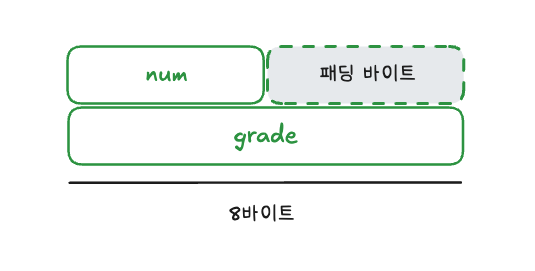
패딩 바이트는 이해를 돕기 위해 블록 형태로 표현하지만, 실제 메모리는 블록처럼 나뉘어 있는 것이 아니라 연속된 바이트 단위 주소 공간입니다. 바이트 얼라인먼트는 데이터 타입이 메모리에서 효율적으로 접근되도록 시작 주소를 맞추는 규칙을 말합니다.
- char형: 모든 주소에서 시작 가능
- short형: 주소가 2의 배수인 위치에서 시작
- int형: 주소가 4의 배수인 위치에서 시작
- double형: 주소가 8의 배수인 위치에서 시작
예를 들어 다음과 같이 구조체를 선언하면 크기는 32바이트가 됩니다.
struct stduent
{
char ch1;
short num;
char ch2;
int score;
double grade;
char ch3;
};
그런데 결국 멤버의 순서에 따라 구조체의 크기가 달라질 수 있으므로 패딩 바이트가 가장 작도록 구조체를 선언하면 메모리를 아낄 수 있습니다. 만약 임베디드 소프트웨어처럼 메모리 크기가 중요한 프로그램을 작성할 때는 꼭 메모리를 최소화할 방법을 고민해봐야 합니다.
struct student
{
char ch1;
char ch2;
short num;
int score;
double grade;
char ch3;
};
구조체 멤버의 순서를 바꿨을 뿐인데 8바이트가 줄어든 것을 확인할 수 있습니다.
다양한 구조체 멤버
배열과 포인터
구조체 멤버로 앞서 예를 든 int, double 외에도 다양한 자료형을 사용할 수 있습니다. 배열, 포인터는 물론이고 이미 선언된 다른 구조체도 멤버로 쓸 수 있습니다.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct profile
{
char name[20];
int age;
double height;
char *intro;
};
int main(void)
{
struct profile hong;
strcpy(hong.name, "홍길동");
hong.age = 20;
hong.height = 180;
hong.intro = (char *)malloc(80);
printf("자기소개: ");
gets(hong.intro);
free(hong.intro);
return 0;
}
profile 구조체의 경우 위와 같이 메모리가 할당됩니다. name은 배열 요소는 char형으로 1바이트이고 double과 포인터는 8바이트로 기준 단위는 8바이트가 됩니다.
hong.intro = "안녕하세요";그리고 구조체의 멤버로 포인터를 쓰면 포인터 멤버에 대입 연산으로 간단히 문자열을 연결할 수 있습니다.
gets(hong.intro); // (x)
hong.intro = (char *)malloc(80);
gets(hong.intro); // (o)그러나 이 경우 문자열 상수 대신 키보드로 문자열을 바로 입력해서는 안됩니다. intro 멤버 포인터는 문자열 자체를 저장할 공간은 없기 때문에 사용자 입력을 받고 싶다면 동적 할당을 통해 적당한 크기를 할당 받아 저장 공간을 먼저 확보해야 합니다.
다른 구조체
만약 student 구조체에 신상명세에 관한 부분이 추가된다면 profile 구조체를 활용할 수 있습니다. 물론 student 구조체보다 profile 구조체가 먼저 선언되어 있어야 합니다.
#include <stdio.h>
struct profile
{
int age;
double height;
};
struct student
{
struct profile pf;
int id;
double grade;
}
int main(void)
{
struct student hong;
hong.pf.age = 17;
hong.grage;
return 0;
}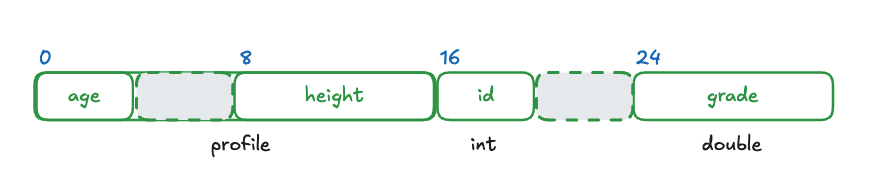
student 구조체는 profile 구조체를 멤버의 자료형으로 사용합니다. 이 경우 나이와 키를 저장할 멤버를 일일이 선언하지 않아도 student 구조체는 profile 구조체의 멤버를 모두 자신의 데이터로 가질 수 있습니다.
구조체 변수의 초기화
구조체 변수도 일반 변수와 같이 선언과 동시에 초기화할 수 있습니다. 단, 여러 개의 멤버를 초기화하므로 배열 초기화와 비슷한 방법을 사용합니다.
#include <stdio.h>
struct student
{
int id;
char name[20];
double grade;
};
int main(void)
{
struct student s1 = { 315, "홍길동", 2.4 },
s2 = { 316, "이순신", 3.7 },
s3 = { 317, "세종대왕", 4.4 };
struct student best;
best = s1;
if (s2.grade > best.grade) best = s2;
if (s3.grade > best.grade) best = s3;
return 0;
}구조체 변수 선언과 함께 중괄호를 사용해 각 멤버의 형태에 맞는 값으로 초기화했습니다. 그리고 구조체 변수끼리 값을 복사하는 과정에 대입 연산을 사용합니다. 구조체 변수의 대입은 각 멤버들을 자동으로 다른 구조체 변수에 복사합니다.
struct student
{
int id;
char name[20];
double grade;
} s1 = { 315, "홍길동", 2.4 };구조체의 경우 보통 형 선언을 먼저 한 후에 구조체 변수 선언과 초기화를 하지만 위와 같이 3가지를 동시에 하는 것도 가능합니다.
이때, 구조체 선언을 함수 밖에서 하면 함께 선언되는 변수가 전역 변수가 되므로 별도로 초기화하지 않을 경우 모든 멤버가 0으로 자동 초기화됩니다.
구조체 변수와 매개변수
구조체 변수는 대입 연산이 가능하므로 함수의 인수로 주거나 함수에서 여러 개의 값을 구조체로 묶어 동시에 반환하는 것이 가능합니다.
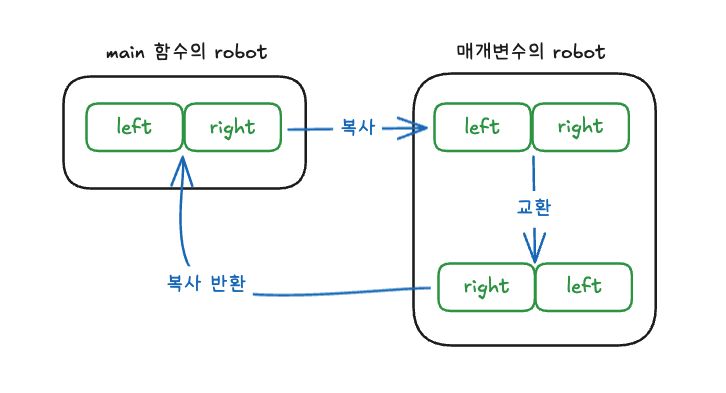
예를 들어 두 변수의 값을 바꾸는 함수에는 포인터가 필요했지만 구조체 변수를 사용해 값을 주고받으면 포인터 없이도 두 변수의 값을 바꾸는 함수를 만들 수 있습니다.
#include <stdio.h>
struct vision
{
double left;
double right;
};
struct vision exchange(struct vision robot);
int main(void)
{
struct vision robot;
printf("시력 입력: ");
scanf("%lf%lf", &(robot.left), &(robot.right));
robot = exchange(robot);
printf("시력 : %.1lf %1.lf", robot.left, robot.right);
return 0;
}
struct vision exchange(struct vision robot)
{
double temp;
temp = robot.left;
robot.left = robot.right;
robot.right = temp;
return robot;
}함수를 호출할 때 인수로 구조체 변수를 사용하면 멤버들의 값을 한꺼번에 함수에 줄 수 있습니다. 심지어 멤버가 배열이라도 모든 배열 요소의 값이 함수에 복사됩니다. 이런 전달 방식은 구조체 변수를 반환할 때도 똑같이 적용되므로 함수가 여러 개의 값을 한 번에 반환할 수 있습니다.
구조체 활용, 공용체, 열거형
구조체는 어떤 대상과 관련된 데이터를 형태가 달라도 하나로 묶어 처리할 수 있다는 장점이 있습니다. 그러나 데이터의 종류가 많을 때는 구조체 변수의 크기가 커지는 아쉬움이 있습니다. 이럴 때 공용체를 쓰면 하나의 공간을 여러 멤버가 공유하므로 최소한의 메모리만 사용할 수 있습니다.
구조체 포인터와 간접 멤버 접근 연산자(->)
구조체 변수는 그 안에 여러 개의 변수를 멤버로 가질 수 있으나, 그 자신은 단지 하나의 변수일 뿐입니다. 따라서 구조체 변수에 주소 연산자를 사용하면 특정 멤버의 주소가 아니라 구조체 변수 전체의 주소가 구해집니다. 또한 그 값을 저장할 때는 구조체 포인터를 사용합니다.
#include <stdio.h>
struct score
{
int kor;
int eng;
int math;
}
int main(void)
{
struct score hong = { 90, 80, 70 };
struct score *ps = &hong;
printf("국어 : %d\n", (*ps).kor);
printf("영어 : %d\n", ps->eng);
printf("수학 : %d\n", ps->math);
return 0;
}hong은 하나의 변수이므로 주소 연산을 수행하면 구조체 변수 전체의 주소가 구해집니다. 이 값을 구조체 포인터 ps에 저장하면 ps가 구조체 변수 hong을 가리키게 됩니다. 포인터에 간접 참조 연산자(*)와 멤버 접근 연산자(.)를 사용하여 멤버에 접근할 수 있습니다.
이때 16, 17행과 같이 구조체 포인터에 간접 멤버 접근 연산자(->)를 사용하여 간단하게 구조체의 멤버에 접근할 수 있습니다.
구조체 배열
구조체 변수는 멤버가 여러 개지만, 구조체 변수 자체는 하나의 변수로 취급됩니다. 따라서 같은 형태의 구조체 변수가 많이 필요하다면 배열을 선언할 수 도 있습니다.
#include <stdio.h>
struct address
{
char name[20];
int age;
char tel[20];
char addr[80];
};
int main(void)
{
struct address list[5] = {
{"홍길동", 23, "111-1111", "울릉도 독도"),
{"이순신", 35, "222-1111", "서울 건천동"),
{"장보고", 19, "333-1111", "완도 청해진"),
};
int i;
for (i = 0; i < 5; i++){
printf("%s %s", list[i].name, list[i].age);
}
return 0;
}구조체 배열의 초기화는 배열의 초기화와 같습니다. 단, 배열의 요소가 구조체이므로 각각의 초깃값은 구조체를 초기화하는 형식을 사용합니다. 따라서 중괄호 쌍을 2개 사용합니다.
구조체 배열을 처리하는 함수
구조체 배열은 배열 요소가 구조체 변수일 뿐 지금까지 살펴본 배열과 다르지 않습니다. 구조체 배열의 이름은 첫 번째 요소의 주소이므로 구조체 변수를 가리킵니다. 따라서 구조체 배열의 이름을 인수로 답는 함수는 구조체 포인터를 매개변수로 선언합니다.
#include <stdio.h>
struct address
{
char name[20];
int age;
char tel[20];
char addr[80];
};
void print_list(struct address *lp);
int main(void)
{
struct address list[5] = {
{"홍길동", 23, "111-1111", "울릉도 독도"),
{"이순신", 35, "222-1111", "서울 건천동"),
{"장보고", 19, "333-1111", "완도 청해진"),
};
print_list(list);
return 0;
}
void print_list(struct address *lp)
{
int i;
for (i = 0; i < 5; i++){
printf("%s %s", (lp+i)->name, (lp+i)->age);
}
}print_list 함수를 호출할 때 배열명 list를 인수로 줍니다. 배열명 list는 첫 번째 요소의 주소로 struct address 구조체 변수를 가리킵니다. 따라서 print_list 함수의 매개변수로 struct address 구조체를 가리키는 포인터를 선언합니다. 포인터가 배열명을 저장하면 배열명처럼 사용할 수 있으므로 이제 매개변수 lp로 각 배열 요소를 참조하고 멤버들을 출력할 수 있습니다.
또한 다음 3가지 표현은 모두 같은 결과값을 갖습니다.
- lp[i].name
- (*(pl+i)).name
- (lp+i)->name
자기 참조 구조체
개별적으로 할당된 구조체 변수를 포인터로 연결하면 관련된 데이터를 하나로 묶어 관리할 수 있습니다. 이때 자기 참조 구조체를 사용합니다. 자기 참조 구조체는 자신의 구조체를 가리키는 포인터를 멤버로 가집니다.
#include <stdio.h>
struct list
{
int num;
struct list *next;
};
int main(void)
{
struct list a = {10, 0}, b = {20, 0}, c = {30, 0};
struct list *head = &a, *current;
a.next = &b;
b.next = &c;
printf("head->num : %d\n", head->num);
printf("head->next->num : %d\n", head->next->num);
printf("list all : ");
current = head;
while (current != NULL)
{
printf("%d ", current->num);
current = current->next;
}
printf("\n");
return 0;
}
구조체 변수를 포인터로 연결한 것을 연결 리스트(linked list)라고 합니다. 연결 리스트는 첫 번째 변수의 위치만 알면 나머지 변수는 포인터를 따라가 모두 사용할 수 있으므로 대부분 12행처럼 첫 번째 변수의 위치를 head 포인터에 저장해 연결 리스트를 사용합니다.
struct list *head = &a;
struct list *current;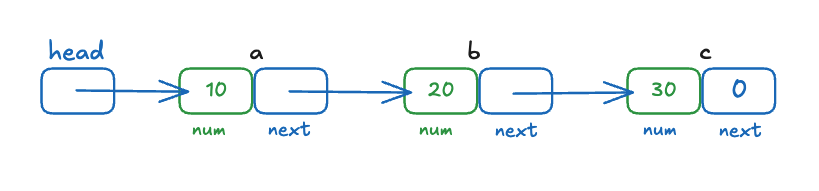
21행에서 current는 최초 a를 가리키다 반복문 안에서 25행이 수행될 때마다 다음 변수를 가리키며 모든 num 값을 출력합니다. 마지막으로 current가 c를 가리킬 때 current->next는 0이므로 그 값을 current에 저장하면 current는 널 포인터가 되어 반복을 종료합니다.
물론 이 과정은 head 포인터로도 수행할 수 있지만, head 포인터의 값을 바꾸면 다시 처음 위치를 찾아갈 수 없으므로 항상 연결 리스트의 시작 위치를 기억하도록 그 값을 바꾸지 않는 것이 좋습니다.
공용체
공용체의 선언 방식은 구조체와 비슷합니다. 하지만 공용체의 경우 모든 멤버가 하나의 저장 공간을 같이 사용합니다. 공용체가 저장 공간을 공유하므로 생기는 장단점을 예제를 통해 살펴보겠습니다.
#include <stdio.h>
union student
{
int num;
double grade;
};
int main(void)
{
union student s1 = { 315 };
printf("학번 : %d\n", s1.num);
s1.grade = 4.4;
printf("학점 : %1.lf\n", s1.grade);
printf("학번 : %d\n", s1.num);
return 0;
}공용체는 예약어 union을 사용하며 그 외의 다른 부분들은 구조체를 선언하는 형식과 같습니다.
공용체 선언이 끝나면 공용체형으로 변수를 선언할 수 있습니다. 이때 저장 공간이 할당되는 방식과 초기화는 다음 규칙을 따릅니다.
규칙 1. 공용체 변수의 크기는 멤버 중에서 크기가 가장 큰 멤버로 결정됩니다.
따라서 11행에서 union student의 변수를 선언하면 double형 멤버의 크기인 8바이트의 저장 공간이 할당되고 num과 grade 멤버가 하나의 공간을 공유합니다.

공용체는 저장 공간을 공유하는 점 외에 구조체와 특별히 다르지 않습니다. 멤버를 참조하거나 배열, 포인터를 사용하는 것은 구조체와 같습니다. 다만, 저장 공간이 하나이므로 초기화하는 방법이 구조체와 다릅니다.
규칙 2. 공용체 변수의 초기화는 중괄호를 사용해 첫 번째 멤버만 초기화합니다.
만약 첫 번째 멤버가 아닌 멤버를 초기화할 때는 멤버 접근 연산자로 멤버를 직접 지정해야 합니다.
union student s1 = { 315 }; // num = 315
union student s1 = { .grade = 4.4 }; // grade = 4.4
공용체 멤버는 언제든지 다른 멤버에 의해 값이 변할 수 있으므로 항상 각 멤버의 값을 확인해야 하는 단점이 있지만, 여러 멤버가 하나의 저장 공간을 공유하므로 메모리를 절약할 수 있고, 특히 같은 공간에 저장된 값을 여러 가지 형태로 사용할 수 있다는 장점이 있습니다.
열거형
열거형의 선언 방식도 구조체와 비슷합니다. 그러나 구조체 멤버와 열거형 멤버 간 차이가 있습니다. 열거형은 변수에 저장할 수 있는 정수 값을 기호로 정의해서 나열합니다. 구체적인 내용은 예제를 통해 살펴보겠습니다.
#include <stdio.h>
enum season {SPRING, SUMMER, FALL, WINTER};
int main(void)
{
enum season ss;
char *pc = NULL;
ss = SPRING;
switch (ss)
{
case SPRING:
pc = "inline"; break;
case SUMMER:
pc = "swimming"; break;
case FALL:
pc = "trip"; break;
case WINTER:
pc = "skiing"; break;
}
printf("레저 활동: %s\n", pc);
return 0;
}예약어 enum과 열거형 이름을 짓고 괄호 안에 멤버를 콤마로 나열합니다.
컴파일러는 멤버를 0부터 차례로 하나씩 큰 정수로 바꿉니다. 즉, SPRING은 0, SUMMER는 1, FALL은 2, WINTER는 3이 됩니다.
물론 초깃값을 원하는 값으로 설정할 수도 있지만, 열거형의 멤버는 상수(constant)이기 때문에 대입을 통한 변경은 불가능합니다.
이때 값이 새로 설정된 멤버 이후의 멤버는 설정된 멤버보다 하나씩 큰 정수로 바뀝니다.
enum season { SPRING = 5, SUMMER, FALL = 10, WINTER };예를 들어 위와 같이 초깃값을 설정한다면 SUMMER는 6, WINTER는 11이 됩니다. 결국 열거형 멤버는 정수로 바뀌므로 사실상 정수 상수를 사용해 작성할 수도 있습니다. 그러나 열거형을 정의하면 이름을 직접 사용할 수 있으므로 훨씬 읽기 쉬운 코드를 만들 수 있습니다.
typedef
구조체, 공용체, 열거형의 이름은 항상 struct 등 예약어와 함께 써야 하므로 불편합니다. 특히 함수의 매개변수나 반환값의 형태에 쓰면 함수 원형이 복잡해집니다. 이때 typedef를 사용하면 자료형 이름에서 struct와 같은 예약어를 생략할 수 있습니다. 이처럼 형 재정의를 통해 짧고 쉬운 이름으로 사용하는 방법을 살펴보겠습니다.
#include <stdio.h>
struct student
{
int num;
double grade;
}
typedef struct student Student;
void print_data(Student *ps);
int main(void)
{
Student s1 = { 315, 4.2 };
print_data(&s1);
return 0;
}
void print_data(Student *ps)
{
printf("학번 : %d\n", ps->num);
printf("학점 : %.1lf\n", ps->grade);
}재정의 방법은 typedef 뒤에 재정의할 자료형의 이름을 적고 뒤이어서 새로운 이름을 적습니다. 그리고 맨 뒤에 세미콜론(;)을 붙이면 됩니다.
물론 재정의하기 전의 이름도 함께 사용할 수 있으며, 일반적으로는 일반 변수명과 구분하기 위해 재정의된 자료형의 이름을 대문자로 쓰기도 합니다. 재정의하기 전의 자료형을 굳이 사용할 필요가 없다면 다음과 같이 형 선언과 동시에 재정의하는 방법도 있습니다.
typedef struct
{
int num;
double grade;
} Student;
또한 typedef문을 사용해 복잡한 응용 자료형뿐 아니라 필요에 따라 기본 자료형도 재정의할 수 있습니다.
typedef unsigned int nbyte;'Lang > C' 카테고리의 다른 글
| C (12) - 전처리와 분할 컴파일 (0) | 2025.09.08 |
|---|---|
| C (11) - 파일 입출력 (0) | 2025.09.04 |
| C (9) - 메모리 동적 할당 (2) | 2025.08.28 |
| C (8) - 다차원 배열, 포인터 배열, 응용 포인터 (2) | 2025.08.25 |
| C (7) - 변수 영역과 데이터 공유 (0) | 2025.08.21 |