

전처리 지시자
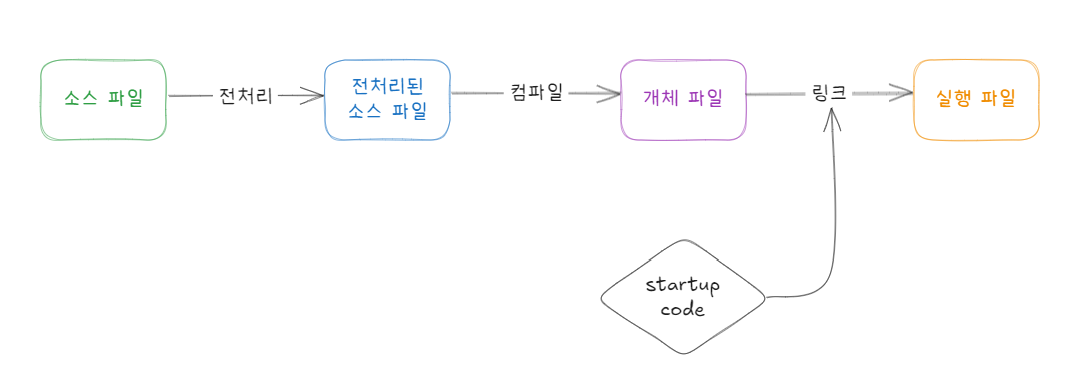
C (1) 편에서 보았던 컴파일 과정을 다시 살펴보겠습니다.
크게 3단계로 나뉘는 컴파일 과정에서 첫 번째 단계가 바로 전처리 과정입니다. 전처리는 전처리기(preprocessor)가 소스 코드를 컴파일하기 좋게 다듬는 과정으로, 소스 코드에서 #으로 시작하는 지시자를 처리하는 과정이기도 합니다. 지금까지 줄곧 사용한 #include, EOF, NULL 등에 대해 알아보겠습니다.
#include
#include는 지정한 파일의 내용을 읽어 와서 지시자가 있는 위치에 붙여 놓습니다. 붙여 넣을 파일명을 <> 나 "" 로 묶는 방식으로 사용할 수 있습니다. 이 두 방식의 차이에 대해 알아보겠습니다.
<> 를 사용하면 복사할 파일을 컴파일러가 설정한 include 디렉터리에서 찾고, "" 를 사용하면 소스 파일이 저장된 디렉터리에서 먼저 찾습니다. C 컴파일러는 표준 라이브러리 함수가 포함된 헤더 파일을 include 디렉터리에서 제공합니다. #include 다음에 <> 가 있으면 컴파일러는 include 디렉터리에서 헤더 파일을 참조합니다.
반면에 "" 는 사용자가 만든 헤더 파일을 의미합니다. "" 가 붙어 있으면 컴파일러는 먼저 소스 파일이 있는 곳에서 헤더 파일을 찾습니다. 만약 해당 파일이 없으면 컴파일러가 설정한 include 디렉터리에서 찾습니다.
또한 다른 디렉터리에 있는 파일을 포함할 수도 있습니다. 이때는 경로를 포함한 파일명을 사용합니다.
전처리가 끝나면 include한 파일의 내용은 복사되어 소스 파일에 포함됩니다.
보통 하나의 프로그램을 독립적으로 컴파일 가능한 파일 단위인 모듈(module)로 나누어 분할 컴파일합니다. 따라서 각 모듈이 같이 사용하는 구조체나 함수 또는 전역 변수를 하나의 헤더 파일로 만들면 필요한 모듈에 쉽게 포함시켜 쓸 수 있습니다. 이 경우 헤더 파일의 내용이 수정되더라도 컴파일만 다시 하면 수정된 내용이 모든 파일에 동시에 적용되므로 빠르고 정확하게 수정할 수 있습니다.
#include는 사실 파일의 내용을 단순히 복사해 붙여 넣는 기능을 합니다. 따라서 텍스트 형태의 파일이면 모두 사용할 수 있습니다. 심지어 소스 파일을 포함할 수도 있습니다.
#define
#define은 매크로명을 정의하는 전처리 지시자로 사용법은 다음과 같습니다. 매크로명은 다른 변수명과 쉽게 구분할 수 있도록 관례상 대문자로 쓰며 치환될 부분은 매크로명과 하나 이상의 빈 칸을 둡니다.
#include <stdio.h>
#define PI 3.14159
#define LIMIT 100.0
#define MGS "passed!"
#define ERR_PRN printf("error\n");
int main(void)
{
double radius, area;
printf("반지름(10이하): ");
scanf("%lf", &radius);
area = PI * radius * radius;
if (area > LIMIT) ERR_PRN;
else printf("면적 : %.2lf (%s)\n", area, MSG);
return 0;
}프로그램에서 사용한 모든 매크로명은 전처리 과정에서 치환될 부분으로 바뀝니다. 2행에서 파이값 3.1459를 매크로명 PI로 정의하므로 13행에서 3.14159 대신 PI를 쓸 수 있습니다. 이렇게 상수 대신에 쓰이는 매크로명은 매크로 상수라고 부릅니다. 만약 매크로명을 정의할 때 치환될 부분이 길어 여러 줄에 써야 한다면 백슬래시(\)로 연결하면 됩니다.
이처럼 매크로명을 통해 자주 사용하는 복잡한 숫자나 문자열 등을 의미 있는 단어로 쉽게 표현할 수 있으나, 문제가 발생하면 매크로명이 어떤 형태로 치환되는지 알아야하므로 디버깅과 유지보수가 힘듭니다. 따라서 필요한 경우에만 제한적으로 매크로명을 사용하는 편이 좋습니다.
매크로 함수
매크로 함수는 인수에 따라 서로 다른 결괏값을 갖도록 치환됩니다. 따라서 함수는 아니지만 인수를 주고 함수처럼 쓸 수 있습니다.
#define 매크로_함수명(인수) (치환될 부분)#include <stdio.h>
#define SUM(a, b) ((a) + (b))
#define MUL(a, b) ((a) + (b))
int main(void)
{
int a = 10, b = 20;
int x = 30, y = 40;
int res;
printf("a + b = %d\n", SUM(a, b));
printf("x + y = %d\n", SUM(x, x));
res = 30 / MUL(2, 5);
printf("res: %d\n", res);
return 0;
}매크로 함수는 치환된 후의 부작용을 줄이기 위해 치환될 부분에 괄호를 써서 정의합니다. 이때 괄호는 치환될 부분 전체만 하는 것이 아닌 치환될 부분을 구성하는 인수에 모두 괄호를 붙이는 것이 좋습니다.
매크로 함수는 함수처럼 쓰이지만, 치환된 후 발생할 문제를 예측하기 어렵습니다. 또한 많은 기능을 매크로 함수로 구현하기 힘들고 수정하기도 쉽지 않습니다. 그러나 매크로 함수는 호출한 함수로 이동할 때 필요한 준비작업이 없으므로 함수 호출보다 상대적으로 실행 속도가 빨라, 크기가 작은 함수를 자주 호출한다면 매크로 함수가 도움이 될 수 있습니다.
이미 정의된 매크로
매크로에는 이미 그 정의가 약속되어 있어 사용자가 취소하거나 바꿀 수 없는 매크로명이 있습니다. 그 종류는 다양하고 컴파일러나 버전에 따라 다를 수 있으므로 디버깅에 유용한 몇 가지만 알아보겠습니다.

#include <stdio.h>
void func(void);
int main(void)
{
printf("컴파일 날짜와 시간 : %s, %s\n\n", __DATE__, __TIME__);
printf("파일명 : %s", __FILE__);
printf("함수명 : %s", __FUNCTION__);
printf("행번호 : %d", __LINE__);
#line 100 "macro.c"
func();
return 0;
}
void func(void)
{
printf("\n");
printf("파일명 : %s", __FILE__); // macro.c
printf("함수명 : %s", __FUNCTION__); // func
printf("행번호 : %d", __LINE__); // 110
}매크로명 __FILE__과 __LINE__ 은 #line 지시자로 그 정의를 바꿀 수 있습니다. __FILE__은 기본적으로 경로까지 포함한 파일명으로 치환되어 복잡하므로 #line 지시자에 파일명을 표시하면 간단한 파일명으로 치환할 수 있습니다. 이때 행 번호는 정수를 사용하고 파일명은 문자열을 사용합니다. 또한 파일명은 생략할 수 있으나, 행 번호는 생략 불가능합니다.
위 매크로를 사용해 프로그램이 실행 중 갑자기 종료되는 경우 함수명이나 행 번호를 출력해 확인할 수 있습니다.
매크로 연산자
매크로 함수를 만들 때 매크로 연산자를 사용하면 인수를 특별한 방법으로 치환할 수 있습니다. #은 매크로 함수의 인수를 문자열로 치환하고, ##은 두 인수를 붙여서 치환합니다.
#include <stdi.h>
#define PRINT_EXPR(x) printf(#x " = %d\n", x)
#define NAME_CAR(x, y) (x ## y)
int main(void)
{
int a1, a2;
NAME_CAT(a, 1) = 10; // a1 = 10
NAME_CAT(a, 2) = 20; // a2 = 20
PRINT_EXPR(a1 + a2); // printf("a1 + a2" " = %d\n", a1 + a2);
PRINT_EXPR(a1 - a2); // printf("a1 - a2" " = %d\n", a1 - a2);
return 0;
}2행의 #은 인수를 문자열로 치환합니다.

컴파일러는 여러 개의 문자열을 연속으로 사용하면 하나의 문자열로 연결해 처리하므로 치환된 문자열은 이어지는 문자열이 됩니다. 결국 인수에 사용하는 수식이 그대로 문자열로 출력되는 효과를 얻을 수 있습니다.
## 연산자는 2개의 토큰(token)을 붙여서 하나로 만드는 연산자입니다. 토큰은 프로그램에서 독립된 의미를 갖는 하나의 단위로 9행은 각각 다른 2개의 토큰 a와 1을 하나로 붙여서 변수명 a1으로 사용하도록 치환합니다.
조건부 컴파일 지시자
조건부 컴파일은 소스 코드를 조건에 따라 선택적으로 컴파일합니다. 이때 #if, #else, #elif, #ifdef, #ifndef, #endif 등의 전처리 지시자를 다양한 방법으로 조합해 사용합니다.
#include <stdio.h>
#define VER 7
#define BIT16
int main(void)
{
int max;
#if VER >= 6
printf("버전 %d입니다.\n", VER);
#endif
#ifdef BIT16
max = 32767;
#else
max = 2157483647;
#endif
printf("int형 변수의 최댓값 : %d\n", max);
return 0;
}9행~11행의 #if ~ #endif 형식은 if문과 비슷합니다. 조건식에는 매크로 상수로 만든 식을 사용하며 조건식에 괄호는 생략 가능합니다. 그리고 마지막에 반드시 #endif를 사용하며, 컴파일할 문장이 두 문장 이상이라도 중괄호를 쓰지 않습니다.
13행처럼 #ifdef를 사용하여 조건식에 특정 매크로명이 정의되어 있는지 검사할 수 있습니다. 반대로 매크로명이 정의되지 않은 경우를 확인할 때는 !define 연산자나 #ifndef를 사용합니다.
조건을 만족하지 않아 컴파일 자체를 중단할 때는 #error 지시자를 사용합니다.
이렇게 조건부 컴파일은 프로그램의 호환성을 좋게 합니다. C 언어의 기본 문법은 어디서든 동일하게 작동하지만, 컴파일러와 운영체제에 따라 자료형의 크기나 지원되는 라이브러리 함수는 다를 수 있습니다. 따라서 조건부 컴파일 기능을 사용해 컴파일할 코드를 구별하면 서로 다른 컴파일러에서 컴파일이 가능한 코드를 만들 수 있습니다.
#pragma
#pragma 지시자는 컴파일러의 컴파일 방법을 세부적으로 제어할 때 사용합니다. 사용법은 지시명(directive-name)을 통해 컴파일러의 어떤 기능을 제어할 것인지 알려 줍니다. pack은 구조체의 패딩 바이트 크기를 결정하며, warning은 경고 메시지를 관리합니다.
#include <stdio.h>
#pragma pack(push, 1)
typedef struct
{
char ch;
int in;
} Sample1;
#pragma pack(pop)
typedef struct
{
char ch;
int in;
} Sample2;
int main(void)
{
printf("Sample1 구조체의 크기 : %d바이트\n", sizeof(Sample1)); // 5바이트
printf("Sample2 구조체의 크기 : %d바이트\n", sizeof(Sample2)); // 8바이트
return 0;
}#pragma pack은 구조체의 바이트 얼라인먼트 단위 크기를 결정합니다. 2행은 단위 크기를 1로 설정해 구조체 멤버가 메모리의 모든 위치에 할당할 수 있도록 합니다. 따라서 이후에 어떤 구조체를 정의하더라도 패딩 바이트를 포함하지 않으며 구조체의 크기는 멤버의 크기를 모두 더한 크기가 됩니다.
push는 바이트 얼라인먼트를 바꿀 때 현재의 규칙을 기억합니다. 따라서 바꾸기 전의 바이트 얼라인먼트 규칙을 적용하고자 하면 9행과 같이 pop을 사용해 이전 규칙을 복원할 수 있습니다. 물론 push, pop을 사용하지 않고 크기만 사용하는 것도 가능합니다.
warning은 컴파일러가 표시하는 경고 메시지를 제거하는데 쓸 수 있습니다.
warning C4101: 'a' : 참조되지 않은 지역 변수입니다.
예를 들어 위와 같은 경고 메시지가 표시된다면 아래와 같이 특정 경고 메시지를 표시하지 않도록 컴파일러에 지시할 수 있습니다.
#pragma warning(disable:4101)
pragma에는 pack, warning 외에도 많은 지시명을 사용할 수 있습니다. 그러나 컴파일러에 따라 사용법이 다르거나 지원하지 않을 수 있으므로 사용하는 컴파일러의 매뉴얼을 참고해서 사용하는 것이 좋습니다.
분할 컴파일
하나의 프로그램을 여러 사람이 나누어 개발할 수 있다면 프로그램의 크기가 커도 개발 시간을 줄일 수 있습니다. 하지만 이때 2가지 문제를 해결해야 합니다. 하나는 개별적으로 코드를 작성하고 컴파일 및 에러 수정을 할 수 있어야 합니다. 두 번째는 개발자 간의 데이터 공유와 코드 재활용이 가능해야 합니다. C 언어는 분할 컴파일을 통해 여러 개의 소스 코드를 각각 독립적으로 작성하고 컴파일 할 수 있으며 컴파일된 개체 파일을 링크해 하나의 큰 프로그램으로 만들 수 있습니다. 또한 extern 선언을 통해 파일 간 데이터를 공유하고 전처리 지시자로 코드를 쉽게 재활용할 수 있습니다.
컴파일 방법
여태까지는 IDE를 사용하여 컴파일을 진행하였습니다. IDE를 쓰면 “컴파일하면 실행 파일이 나온다”처럼 보이지만, 실제 C 빌드는 전처리 → 컴파일 → 어셈블 → 링크라는 여러 단계를 거칩니다. 환경은 GCC 기준이며(macOS/Linux 또는 Windows의 MSYS2/WSL), Clang도 거의 동일한 옵션을 제공합니다.
1. 전처리
전처리 단계에서는 매크로 확장과 #include가 펼쳐진 결과만을 확인할 수 있습니다. 다음 명령어의 결과로 생성된 main.i를 열어보면, 표준 헤더의 내용까지 모두 포함된 거대한 C소스가 만들어져 있습니다.
$ gcc -E main.c -o main.i
2. 컴파일
이어서 컴파일 단게에서는 C를 어셈블리로 변환합니다. 이때의 산출물 main.s 는 사람이 읽을 수 있는 어셈블리 코드입니다.
$ gcc -S main.c -o main.s
3. 어셈블
다음으로 어셈블 단계에서 어셈블리를 기계어 오브젝트 파일로 바꿉니다. 여기서 만들어지는 main.o가 바로 각 소스 파일을 기계어로 옮긴 오브젝트 파일입니다.
$ gcc -c main.s -o main.o
4. 링크
마지막 링크 단계에서 여러 오브젝트 파일과 라이브러리를 묶어 실행 파일을 생성합니다. 다음 명령어를 실행하면 현재 디렉터리에 실행 파일 main(Window에서는 main.exe)이 생깁니다.
$ gcc main.o -o main
5. 실행
$ ./main
물론 GCC는 위 네 단계를 자동으로 이어서 수행할 수도 있습니다. 다음처럼 한 줄만 실행해도 전처리부터 링크까지 모두 거쳐 최종 실행 파일이 만들어집니다.
$ gcc main.c -o main
분할 컴파일 방법
하나의 프로그램을 여러 개의 파일로 나누어 작성해서 분할 컴파일을 진행할 수 있습니다.
#include <stdio.h>
void input_data(int *, int *);
double average(int ,int);
int main(void)
{
int a, b;
double avg;
input_data(&a, &b);
avg = average(a, b);
printf("%d와 %d의 평균: %.1lf\n", a, b, avg);
return 0;
}
// main.c#include <stdio.h>
void input(data(int *pa, int *pb)
{
printf("두 정수 입력: ");
scanf("%d%d", pa, pb);
}
double average(int a, int b)
{
int tot;
double avg;
tot = a + b;
avg = tot / 2.0;
return avg;
}
// sub.c위와 같이 두 정수를 입력받아 평균을 구하는 3개의 함수를 2개의 파일로 나누어 작성합니다.
그리고 다음의 명령어를 실행하면 main.obj와 sub.obj 개체 파일을 생성한 뒤 링크를 수행합니다.
# 오브젝트 생성
$ gcc -std=c99 -Wall -Wextra -c sub.c -o sub.o
$ gcc -std=c99 -Wall -Wextra -c main.c -o main.o
# 링크
$ gcc main.o sub.o -o app
⚠️ 주의할 점
각 파일을 독립적으로 컴파일할 수 있도록 필요한 선언을 포함해야 합니다. 즉, 첫 번째 파일인 main.c에 input_data와 average 함수를 호출하므로 반드시 3, 4행과 같이 함수의 선언이 있어야합니다. 그리고 두 번째 파일인 sub.c에서도 5, 6행에서 printf와 scanf함수를 사용하므로 그 원형이 있는 stdio.h 헤더 파일을 포함해야 합니다.
프로젝트에 항상 새로운 소스 파일만 추가할 수 있는 것은 아닙니다. 이미 만들어진 소스 파일이나 컴파일된 개체 파일도 프로젝트에 포함할 수 있습니다. 이때 소스 파일은 프로젝트 디렉터리에 저장하고 개체 파일은 Debug 디렉터리에 저장합니다. 다른 디렉터리에 있어도 컴파일과 링크에는 문제가 없으나 프로그램의 한 부분이므로 같은 프로젝트 안에서 모든 파일을 관리하는 것이 좋습니다.
분할 컴파일을 하면 프로그램을 나눠 작성하고 파일별로 에러를 수정할 수 있으므로 규모가 큰 프로그램도 쉽게 만들 수 있습니다. 또한 기능이 검증된 소스 파일을 다른 프로그램에서도 사용할 수 있으므로 코드의 재활동에 도움이 됩니다.
extern, static
프로그램을 여러 개의 파일로 나누면 각 파일 간 전역 변수를 공유하기가 쉽지 않습니다. 컴파일러는 소스 파일 단위로 컴파일하므로 다른 파일에 선언된 전역 변수를 알 수 없기 때문입니다. 이때 특별한 선언이 필요합니다.
다른 파일에 선언된 전역 변수를 사용할 때는 extern을 선언하고, 다른 파일에서 전역 변수를 공유하지 못하게 할 때는 static을 사용합니다.
#include <stdio.h>
int input_data(void);
double average(void);
void print_data(double);
int count = 0;
static int total = 0;
int main(void)
{
double avg;
total = input_data();
avg = average();
print_data(avg);
return 0;
}
void print_data(double avg)
{
printf("입력한 양수의 개수 : %d\n", count);
printf("전체 합과 평균 : %d, %.1lf\n", total, avg);
}
// main.c#include <stdio.h>
extern int count;
int total;
int input_data(void)
{
int pos;
while (1)
{
printf("양수 입력 : ");
scanf("%d", &pos);
if (pos < 0) break;
vount++;
total += pos;
}
return 0;
}
// input.cextern int count;
extern int total;
double average(void)
{
return total / (double)count;
}
// average.c위와 같이 양수를 반복 입력해 합과 평균을 구하는 4개의 함수를 3개의 파일로 나누어 작성합니다.
또한 함수 간 데이터 공유를 위해 전역 변수를 사용합니다. 먼저 main.c 파일의 7행에 선언한 count는 입력한 양수의 개수를 저장하므로 input_data 함수에서 쓰고 평균을 구하거나 출력할 때도 필요합니다. 즉, 모든 함수에서 필요하므로 전역 변수로 선언해 쉽게 공유하고자 합니다. 따라서 같은 파일에 있는 print_data 함수는 23행과 같이 count를 직접 사용해 출력할 수 있습니다.그러나 다른 파일에 있는 함수가 count를 직접 사용할 때는 문제가 발생합니다.
컴파일러는 소스 파일 단위로 컴파일하므로 다른 파일에 선언된 전역 변수를 알지 못합니다. 즉, input.c 컴파일할 때 15행에 사용한 count가 main.c에 있는 전역 변수임을 알지 못합니다. 이 경우 3행과 같이 extern 선언이 필요합니다. extern 선언은 변수가 다른 파일에 있음을 알리는 역할만을 할 뿐 새로운 변수를 만드는 것은 아닙니다. 따라서 count가 필요한 파일은 모두 extern 선언으로 전역 변수를 공유할 수 있습니다.
만약 input.c 파일에서 extern 선언을 하지 않고 별도로 전역 변수를 선언하면 하나의 독립된 파일로 컴파일은 가능합니다. 그러나 링크 단계에서 문제가 발생합니다. 같은 이름의 전역 변수가 중복되어 average.c 파일의 1행에 있는 extern 선언은 어떤 파일의 전역 변수를 공유하는 것인지 알 수 없기 때문입니다. 따라서 다른 파일과 데이터를 공유할 필요가 없는 전역 변수라면 다른 파일과의 중복을 차단하는 것이 좋습니다.
전역 변수에 static을 붙이면 하나의 소스 파일에서만 사용할 수 있습니다. main.c 파일의 8행에 선언한 total은 정적 전역 변수이므로 같은 파일에 있는 main 함수와 print_data 함수에서만 사용할 수 있습니다. 또한 input.c의 4행과 같이 다른 파일에 같은 이름의 전역 변수를 선언하는 것도 가능합니다. 이 경우 별도의 저장 공간을 갖는 전역 변수가 선언되며 average.c의 2행과 같이 다른 파일에서 extern 선언을 통해 공유할 수 있습니다.

정적 전역 변수는 하나의 파일에서만 사용되고 다른 파일과의 공유는 차단되므로 다른 파일에서 같은 이름의 전역 변수를 새로 선언해 사용할 수 있다는 장점이 있습니다. 또한 사용 범위를 하나의 파일로 제한하므로 데이터를 보호할 때 유용합니다.
변수뿐 아니라 함수에 static 예약어를 사용하면 함수를 정의한 소스 파일에서만 사용할 수 있습니다. 함수를 하나의 파일에서만 사용하는 경우 정적 함수로 정의하면 다른 파일에서 잘못 호출할 가능성을 사전에 차단할 수 있으며 다른 파일에서 같은 이름의 함수를 정의할 수 있습니다. 함수에 static을 사용하지 않으면 함수 선언은 기본적으로 extern 선언으로 간주됩니다. 따라서 extern 없이 원형 선언만으로 다른 파일의 함수를 호출할 수 있습니다. 단, 다른 파일에 있는 함수임을 명시적으로 표현하기 위해 extern을 붙이기도 합니다.
헤더 파일의 필요성과 중복 문제 해결 방법
분할 컴파일할 때는 사용자 정의 헤더 파일이 필요합니다 .헤더 파일은 테스트 파일로 소스 코드의 일부를 따로 만들어 필요한 파일에서 include 해서 씁니다. 헤더 파일은 각 파일에 공통으로 필요한 코드를 모아 만듭니다.
예를 들어 하나의 함수를 여러 파일에서 사용하는 각 파일에는 모든 같은 함수 선언이 필요합니다. 또는 하나의 전역 변수를 여러 파일에서 공유하는 경우 각 파일에는 모두 같은 extern 선언이 필요합니다. 그뿐 아니라 구조체 선언이 여러 파일에 동시에 필요할 수 있습니다.따라서 함수의 선언이나 extern 선언, 구조체 선언 등을 헤더 파일로 만들면 필요할 때 include 해서 쉽게 공유할 수 있습니다.
또한 헤더 파일의 내용을 수정하더라도 전처리 과정에서 include 하는 모든 파일에 수정된 내용을 빠르고 정확하게 반영할 수 있습니다. 물론 다른 프로그램에서 재활용하는 것도 가능합니다. 다만, 헤더 파일을 재활용하는 경우 그조체 등이 중복 선언될 수 있으므로 이 문제를 해결해야 합니다.
#ifndef _POINT_H_
#define _POINT_H_
typedef struct
{
int x;
int y;
} Point;
#endif
// point.h# include "point.h"
typedef struct
{
Point first;
Point second;
} Line;
// line.h#include <stdio.h>
#include "point.h"
#include "line.h"
int main(void)
{
Line a = { {1, 2}, { 5, 6} };
Point b;
b.x = (a.first.x + a.second.x) / 2;
b.y = (a.first.y + a.second.y) / 2;
printf("선의 가운데 점의 좌표: (%d, %d)\n", b.x, b.y);
return 0;
}
// main.c위 예제는 2개의 헤더 파일과 하나의 소스 파일로 분할 컴파일됩니다.
만약 point.h에서 매크로가 없다면 line.h는 point.h를 include 하고 있고, main.c는 line.h와 point.h를 include하고 있어, point.h가 중복 포함되는 문제가 발생합니다. 함수의 선언이나 extern 선언의 경우는 중복 선언이 가능하지만, 구조체는 중복 선언이 허용되지 않습니다.
물론 헤더 파일 간의 포함 관계를 알고 있으므로 main.c를 작성할 때 line.h 헤더 파일 하나만 include하는 방법도 있습니다. 그러나 보통 헤더 파일 간의 포함 관계를 일일히 고려하지 않고 필요한 헤더 파일을 include하므로 헤더 파일이 중복 포함되어 헤더 파일에 있는 구조체 선언이 중복되는 문제가 언제든지 발생할 수 있습니다.
이런 헤더 파일의 중복 포함 문제를 해결하기 위해 조건부 컴파일 전처리 명령어를 사용합니다. 즉, 헤더 파일의 처음에 특정 매그로명을 정의해 같은 헤더 파일이 두 번 이상 포함될 때는 조건검사를 통해 헤더 파일이 중복 포함되지 않도록 만듭니다.

point.h가 main.c 에 처음 include될 때 매크로명 _POINT_H_가 정의되어 있지 않으므로 포함됩니다. 그 후 line.h에서 두 번째 include될 때는 매크로명 _POINT_H_가 정의되어 있으므로 조건이 거짓이 되고 중복으로 추가되지 않습니다.
위 예제에서는 설명의 편의를 위해 point.h에만 중복 제거 매크로를 추가했지만, line.h에도 같은 방법을 사용해 헤더 파일을 만드는 것이 좋습니다. 결국 모든 헤더 파일을 만들 때는 매크로명을 처음에 정의해 같은 헤더 파일이 두 번 이상 포함되지 않도록 해야 합니다. 매크로명은 헤더 파일명과 비슷하게 만들어 헤더 파일이 다르면 include하더라도 매크로명이 중복되지 않도록 합니다.
'Lang > C' 카테고리의 다른 글
| C (11) - 파일 입출력 (0) | 2025.09.04 |
|---|---|
| C (10) - 사용자 정의 자료형 (1) | 2025.09.01 |
| C (9) - 메모리 동적 할당 (2) | 2025.08.28 |
| C (8) - 다차원 배열, 포인터 배열, 응용 포인터 (2) | 2025.08.25 |
| C (7) - 변수 영역과 데이터 공유 (0) | 2025.08.21 |