

3주차 회고
1주차에 문제를 정의하고, 2주차에 조회를 고도화했다면,
3주차에는 이 구조가 실제 운영 환경에서도 안전하게 동작할 수 있는지를 고민하는 단계였습니다.
여러 OPA 인스턴스를 연결하고 많은 트래픽과 함께 대량의 정책 결정 로그가 유입되는 상황을 가정했을 때
- 로그가 유실되지 않고 처리될 수 있는지
- 로그 수집이 서비스 흐름에 영향을 주지 않는지
- 코드 구조가 이후 확장과 변경에 유연한지
를 중점적으로 점검하고 개선했습니다.
정책 결정 로그는 단순한 부가 데이터가 아니라 장애 분석과 보안 판단의 근거가 되는 관측 데이터입니다.
특히 여러 OPA를 연결하고 트래픽이 증가할수록 로그 유입량은 급격히 늘어나고, 저장 지연이나 장애가 발생할 가능성도 커지며, 로그 처리 로직이 서비스 로직과 강하게 결합되어 있다면 전체 시스템 안정성에 영향을 줄 수 있습니다.
이러한 상황을 전제로 3주차에서는 로그를 어떻게 안전하게 처리할 것인가와 구조적으로 어떻게 변경에 강해질 것인가를 함께 고민했습니다.
비동기 처리 및 복구 프로세스
먼저, 로그 처리 경로를 비동기화했습니다.
기존에는 정책 판단 이후 로그 저장이 요청 처리 흐름과 직접 연결되어 있었기 때문에 저장 지연이나 DB 이슈가 발생할 경우
요청 응답에도 영향을 줄 수 있는 구조였습니다.
이를 개선하기 위해 Kafka를 도입하여 정책 판단 결과는 이벤트로 발행하고 실제 저장은 별도의 처리 흐름에서 수행하도록 분리했습니다.
이를 통해 로그 유입량이 증가하더라도 요청 처리 흐름이 직접적인 영향을 받지 않도록 구조를 정리했습니다.
비동기 구조를 도입한 이후에는 장애 상황에서 시스템이 어떻게 동작해야 하는가를 함께 고민했습니다.
운영 환경에서는 DB 지연이나 일시적인 장애, 트래픽 급증과 같은 상황을 정상 흐름만으로 가정할 수 없기 때문입니다.
이를 위해 다음과 같은 안전장치를 단계적으로 정리하고 적용했습니다.
- 배치 처리
- 백오프 재시도
- 멱등성 보장 및 중복 방지
- 에러 분류 및 라우팅
- 장애 상황에서의 fallback 처리
이 과정에서 중요한 것은 로그 처리 실패가 서비스 실패로 전파되지 않도록 하는 것이었습니다.
시스템 아키텍처와 시퀀스 다이어그램

OPA는 정책 판단 결과를 애플리케이션으로 전달하고 애플리케이션은 이를 즉시 Kafka로 비동기 발행합니다.
이 단계에서는 로그 저장 성공 여부와 관계없이 요청을 빠르게 종료하여 저장 지연이나 일시적인 장애가 정책 판단 응답에 영향을 주지 않도록 했습니다.
Kafka 이후의 저장 과정은 Consumer에서 처리되며 정상 처리 외에도 오류 유형에 따라 DLQ, Parking Lot, Parking DLQ로 분기됩니다. 이를 통해 일시적인 장애는 재처리 경로로 흡수하고 복구가 어려운 오류는 운영자가 확인할 수 있는 지점으로 분리했습니다.
이제 위 아키텍처에서의 실제 런타임 흐름을 시퀀스 다이어그램으로 자세히 살펴보겠습니다.
1. 로그 수집과 정상 처리
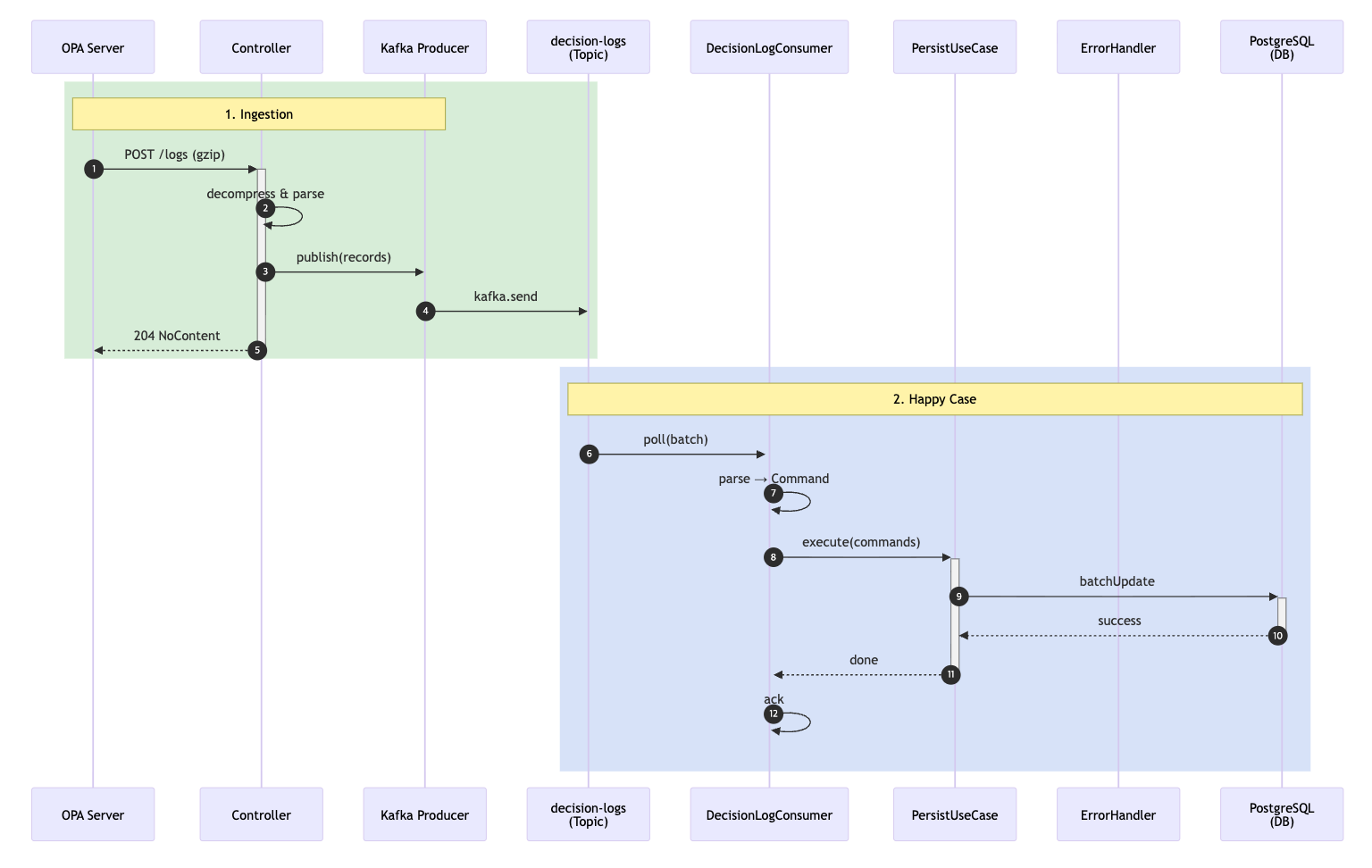
OPA 서버는 정책 판단 결과를 batch 단위로 gzip 압축하여 로그를 전송합니다.
Controller에서는 이를 압축 해제하고 파싱한 뒤 즉시 Kafka 토픽(decision-logs)으로 발행합니다.
이 단계에서 중요한 점은 로그 발행이 요청 처리의 성공 여부와 강하게 결합되지 않도록 설계했다는 것입니다.
Kafka 발행 이후에는 저장 여부와 관계없이 OPA에는 바로 204 NoContent를 응답합니다.
이를 통해 로그 저장 지연이나 일시적인 장애가 정책 판단 요청의 응답 시간에 직접적인 영향을 주지 않도록 했습니다.
Kafka 토픽에 적재된 로그는 DecisionLogConsumer가 batch 단위로 poll 합니다.
Consumer는 로그를 도메인에서 사용하는 Command 객체로 변환한 뒤 PersistUseCase를 통해 DB에 batch 저장을 시도합니다. DB 저장이 성공하면 Consumer는 offset을 ack 하는 이 경우가 가장 일반적인 정상 처리 흐름입니다.
2. 재시도 가능한 오류 / 재시도 불가능한 오류
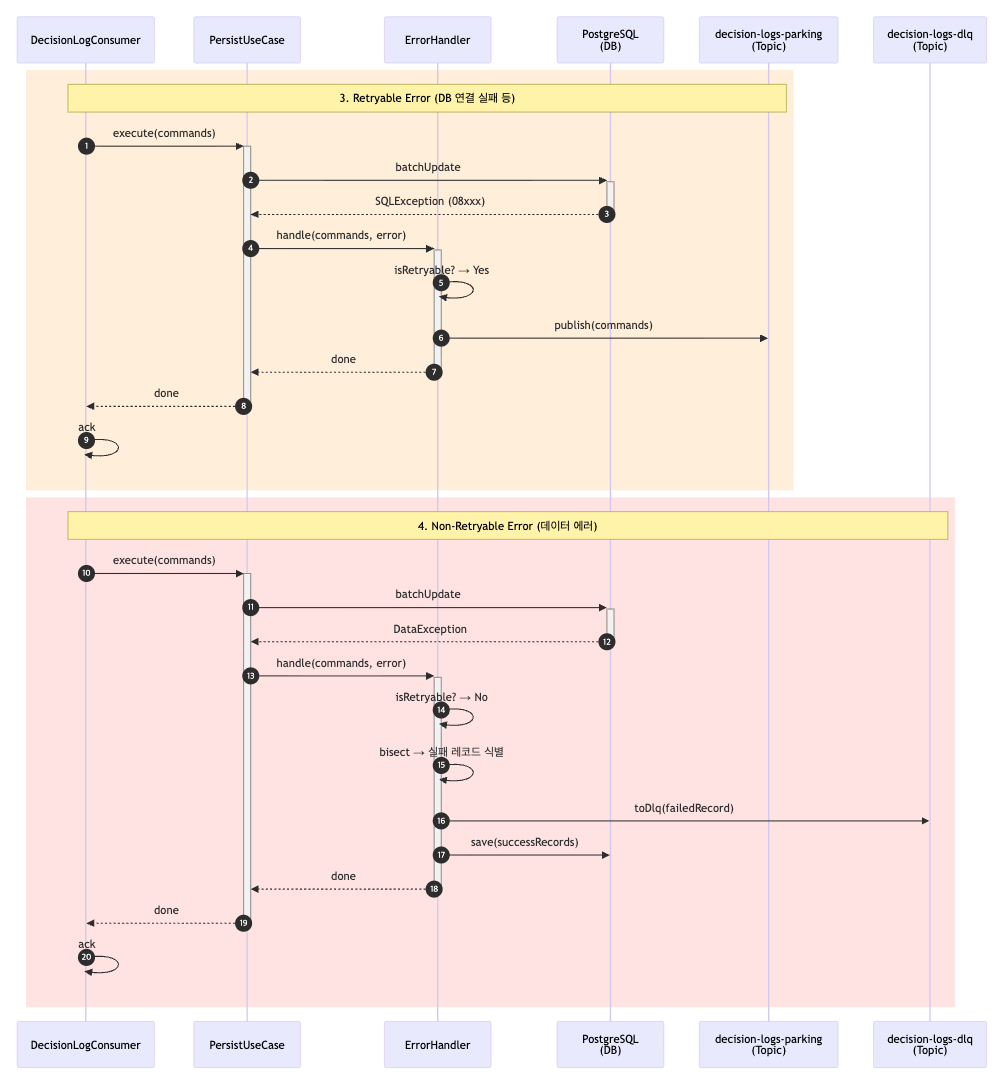
운영 환경에서는 DB 연결 실패, 일시적인 네트워크 오류 등 재시도가 가능한 오류가 발생할 수 있습니다.
이 경우 PersistUseCase에서 예외가 발생하면 에러는 ErrorHandler로 전달되고 ErrorHandler는 오류를 분석해
재시도 가능한 유형으로 판단되면 해당 로그를 Parking Lot 토픽으로 발행합니다.
중요한 점은 이 경우에도 Consumer는 현재 offset을 ack 한다는 점입니다.
즉, 메인 토픽에서의 재처리를 끌고 가지 않고 복구 전용 경로(Parking Lot)로 책임을 분리함으로써 메인 처리 흐름이 지연되지 않도록 했습니다.
반면 데이터 포맷 오류나 제약 조건 위반과 같이 재시도로 해결할 수 없는 오류도 존재합니다.
이 경우 ErrorHandler는 전체 batch를 그대로 실패 처리하지 않고 문제가 발생한 레코드만 식별합니다.
식별을 위해서 Divide and Conquer 알고리즘을 사용하여 배치를 반씩 나눠 실패 레코드들을 따로 수집한 후 정상 레코드는 그대로 DB에 저장하고 실패한 레코드만 DLQ 토픽으로 분리합니다.
이를 통해 하나의 잘못된 로그 때문에 전체 batch가 유실되거나 반복 실패하는 상황을 방지했습니다.
3. Parking Lot 기반 복구 프로세스
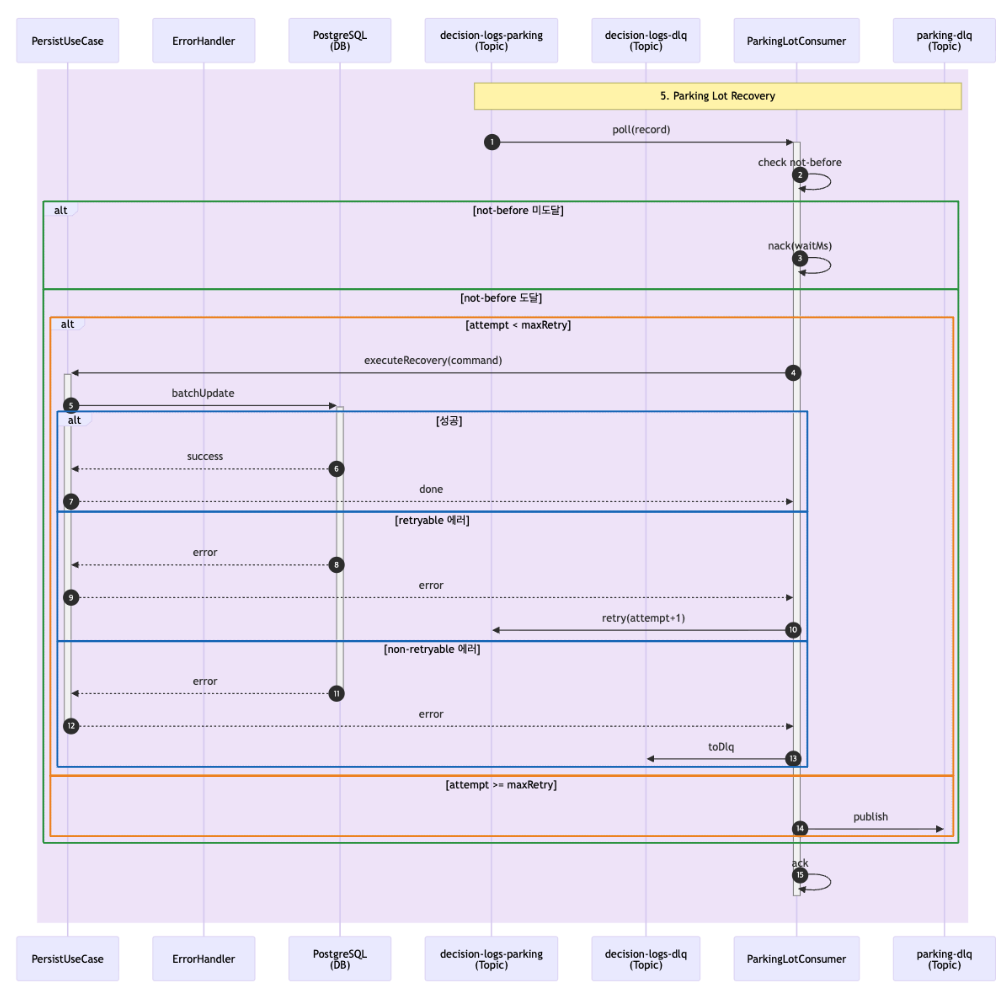
Parking Lot 토픽에 쌓인 로그는 ParkingLotConsumer에 의해 별도로 처리됩니다.
각 레코드는 다음 2가지 헤더를 기준으로 관리됩니다.
- 재시도 횟수(attempt)
- 다음 재시도 가능 시점(not-before)
아직 재시도 시점에 도달하지 않았다면 Consumer는 nack 하여 대기하고 시점이 도달한 경우에만 실제 복구 처리를 시도합니다.
복구 시에도 동일하게 성공하면 정상 종료, 재시도 가능한 오류면 attempt를 증가시켜 다시 Parking Lot으로, 재시도 불가능한 오류면 DLQ로 이동하는 흐름을 따릅니다.
정해진 최대 재시도 횟수를 초과한 경우에는 Parking DLQ로 이동시켜 운영자가 별도로 확인할 수 있도록 했습니다.
비동기 처리와 복구 흐름을 설계하면서 단순히 Kafka를 도입하는 것만으로는 충분하지 않다고 느꼈습니다.
운영 환경에서는 로그의 성격과 실패 유형에 따라 허용할 수 있는 지연과 신뢰성 수준이 서로 다르기 때문입니다.
이에 따라 프로듀서와 컨슈머를 하나의 설정으로 통일하기보다는 각 단계의 역할에 맞게 다른 타임아웃, 재시도, 신뢰성 전략을 적용했습니다. 아래 표는 이러한 의도를 바탕으로 정리한 Producer / Consumer 설정을 한눈에 비교한 내용입니다.
공통 설정
| 항목 | 값 | 역할 |
| acks | all | 모든 replica 확인 |
| enable.idempotence | true | 중복 발행 방지 |
| compression.type | lz4 | 고속 압축 |
| linger.ms | 5ms | 배치 전송 시간 단위 |
| batch.size | 16KB | 배치 사이즈 |
| consumer group.id | decision-log-writer | 저장 전용 그룹 |
| auto.offset.reset | earliest | offset을 모를 때 처음부터 읽기 |
| max.poll.records | 500 | 최대 poll 사이즈 |
Producer 설정
| 구분 | Fast Producer | Parking Producer | DLQ Producer |
| 목적 | 빠른 로그 발행 | 복구 대상 로그 처리 | 최종 유실 방지 |
| 대상 토픽 | decision-logs | decision-logs.parking-lot | decision-logs.dlq / decision-logs.parking-lot.dlq |
| 신뢰성 전략 | 빠른 응답 우선 | 중간 신뢰성 | 최대 신뢰성 |
| retries | 1 | 2 | 3 |
| delivery timeout | 8초 | 20초 | 30초 |
| request timeout | 3초 | 8초 | 12초 |
| max block | 2초 | 5초 | 5초 |
| 실패 시 동작 | 즉시 포기 | Parking Lot 이동 | DLQ 기록 |
Consumer 설정
| 구분 | DecisionLog Consumer | ParkingLot Consumer |
| 역할 | 원본 로그 처리 | 실패 로그 복구 처리 |
| 대상 토픽 | decision-logs | decision-logs-parking |
| 처리 단위 | 배치 처리 (List<ConsumerRecord>) | 단건 처리 (ConsumerRecord) |
| 처리 목적 | 대량 로그를 빠르게 처리 | 실패 메시지를 지연·안전하게 복구 |
| Consumer Group | decision-log-writer | decision-log-writer |
| auto-offset-reset | earliest | earliest |
| max.poll.records | 500 | 500 |
| 정상 처리 | DB batch 저장 후 ack | DB 저장 성공 후 ack |
| 실패 시 기본 흐름 | Parking Lot 또는 DLQ로 분기 | retry 후 Parking DLQ로 분기 |
| 재시도 전략 | ErrorHandler 기반 단기 backoff | Parking Recovery 기반 장기 backoff |
| 재시도 시간 범위 | 최대 30초 | 최대 1시간 |
| 최종 실패 처리 | DLQ | Parking DLQ |
DecisionLog Consumer Backoff
| 항목 | 값 |
| initial interval | 1초 |
| multiplier | 2.0 |
| max interval | 10초 |
| max elapsed time | 30초 |
| 재시도 패턴 | 1s → 2s → 4s → 8s → 10s … (30초 내) |
| 설계 의도 | 빠른 판단 후 메인 흐름 차단 방지 |
ParkingLot Consumer Backoff
| 항목 | 값 |
| max retry attempts | 5회 |
| initial backoff | 1분 |
| backoff multiplier | 2.0 |
| max backoff | 1시간 |
| 재시도 패턴 | 1m → 2m → 4m → 8m → 16m |
| 초과 시 | Parking DLQ 이동 |
| 설계 의도 | 장기 장애·DB 불안정 상황 흡수 |
헥사고날 아키텍처 강화
3주차의 또 다른 핵심은 헥사고날 아키텍처를 더 명확하게 드러내는 것이었습니다.

Kafka 도입과 복구 로직이 추가되면서 자연스럽게 이런 질문이 생겼습니다.
“도메인이나 애플리케이션 계층이 메시징 기술과 저장 방식에 대해 알고 있어야 하는가?”
도메인은 정책 결정 로그를 발행한다는 사실만 알면 되고 그 로그가 Kafka로 가는지, DB에 저장되는지, 혹은 파일로 fallback 되는지는 도메인 외부의 책임이어야 한다고 판단했습니다.
이를 위해 헥사고날 아키텍처의 원칙을 더 명확하게 적용했습니다.
로그 발행과 저장에 대한 책임을 포트(interface) 로 추상화하고, Kafka, DB, 파일 저장과 같은 구체적인 구현은 어댑터(adapter) 로만 존재하도록 구조를 정리했습니다.
또한 복구, 재시도, 저장 전략과 같이 운영 환경에 따라 바뀔 수 있는 정책들 역시 도메인 내부가 아닌 외부 계층으로 밀어냈습니다.
이로 인해
- 메시징 기술이 Kafka에서 다른 시스템으로 변경되더라도
- 저장 방식이 바뀌거나 복구 전략이 조정되더라도
도메인과 애플리케이션 계층의 코드는 영향을 최소화한 채 유지될 수 있는 구조가 되었습니다.
마무리하며
3주차는 기능을 더하는 시간이라기보다는 이 시스템이 실제 운영 환경에서도 버틸 수 있는 구조인지를 점검하고 다듬는 시간이었습니다.
다음 주에는 이 구조 위에 모니터링을 추가하고, 실제 장애·부하 시나리오를 기반으로 한 테스트를 진행해볼 계획입니다.
로그 유실 여부, 처리 지연, 복구 흐름이 의도대로 동작하는지를 관측하며 설계한 구조가 어떤 지표로 설명될 수 있는지를 확인해보려 합니다.
'Leaner's High' 카테고리의 다른 글
| [Learner's High] 4주차 - 검증과 회고 (0) | 2026.01.14 |
|---|---|
| [Learner's High] 2주차 - 조회 고도화 (0) | 2025.12.31 |
| [Learner's High] 1주차 - 문제 정의 (1) | 2025.12.24 |
| [Learner's High] 토스 러너스하이 시작 (0) | 2025.12.17 |