

4주차 회고
3주차까지의 고도화 작업은 모두 하나의 가설에서 출발했습니다.
“로그 처리 경로를 비동기화하고, 장애를 전제로 한 복구 구조를 설계하면
대량 트래픽과 장애 상황에서도 로그 유실 없이 안정적으로 동작할 수 있을 것이다.”
4주차에는 이 가설이 실제로 성립하는지를 확인하기 위해,
모니터링 지표를 기반으로 한 부하 테스트와 장애 시나리오 테스트를 진행했습니다.
부하 테스트는 k6를 사용해, 운영 환경에서 여러 OPA 인스턴스가 동시에 로그를 전송하는 상황을 단순화한 형태로 구성했습니다.
- 부하 조건: 초당 1,000건 요청을 60초간 지속
- 요청 형태: gzip 압축된 Decision Log (요청당 1~5건 배치)
- 목표:
- 요청 수신이 병목 없이 유지되는지
- 로그 저장 경로가 요청 처리 흐름에 영향을 주지 않는지
- 장애 발생 시 로그가 유실되지 않고 복구되는지
정상 시나리오 (POC)
먼저 기존 POC 구조에서도 동일한 조건으로 k6 부하 테스트를 먼저 수행했습니다.
이 테스트는 단순히 “얼마나 빠른가”를 보기 위한 것이 아니라,
부하 상황에서 시스템이 요청을 안정적으로 소화하고 있는지를 확인하기 위한 목적이었습니다.

테스트 결과를 처음 보면 `http_req_failed` 가 0%로 표시되어 있기 때문에 모든 요청이 성공적으로 처리된 것처럼 보일 수 있습니다. 하지만 이 수치는 전송된 HTTP 요청 중에서 2xx 성공 응답이 오지 않은 개수로, 이 테스트에서 주의 깊게 봐야 할 지표는 HTTP 실패율이 아니라 dropped iterations입니다.
dropped_iterations는 k6가 목표로 한 초당 요청 수를 유지하지 못해 포기한 요청 수를 의미하며,
iteration_duration은 요청 하나를 처리하는 데 걸린 전체 시간을 나타냅니다.
이때, dropped_iterations는 “절대적인 실패 개수”가 아닙니다.
이 지표는 목표로 설정한 TPS(iterations/s)를 시스템이 따라가지 못할 때 증가하는 값으로, 이 값이 작다는 것은 해당 부하 조건에서 시스템이 목표 TPS를 대부분 유지하고 있음을 의미합니다.
- dropped iterations : 367/s
- iteration_duration
- 평균: 약 64ms
- p90: 약 128ms
- p95: 약 158ms
정상 시나리오
아래 결과는 로그 처리 경로를 비동기화하고, Kafka 기반 파이프라인을 적용한 이후 동일한 조건(초당 1,000 req/s, 1분)으로 수행한 정상 시나리오 테스트 결과입니다.

- dropped iterations : 10/s
- iteration_duration
- 평균: 약 17ms
- p90: 약 29ms
- p95: 약 31ms
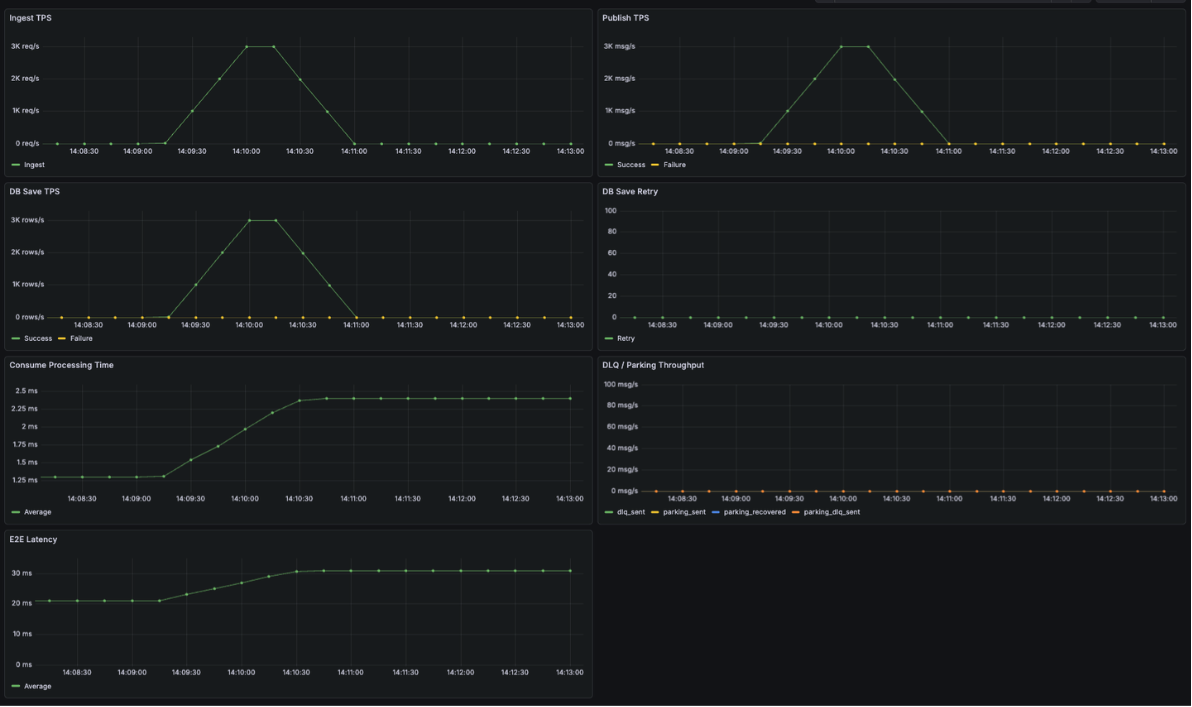
정상 상황에서는 다음 지표들을 중심으로 관측했습니다.
- Ingest TPS
- Kafka Publish TPS
- DB Save TPS
- End-to-End Latency
- DLQ / Parking 관련 메트릭
테스트 결과, 초당 1,000건의 요청이 안정적으로 수신되었으며 Kafka 발행과 DB 저장 역시 배치 처리 기반으로 정상적으로 처리되었습니다. 특히 수신 시점부터 DB 저장까지의 E2E Latency가 안정적으로 유지되었고, DLQ나 Parking Lot으로 분기되는 로그 없이
전체 흐름이 정상 경로로 처리되는 것을 확인할 수 있었습니다.
이를 통해, 로그 유입량이 증가하더라도 요청 처리 흐름이 직접적인 영향을 받지 않는다는 비동기 구조의 기본 가설을 확인할 수 있었습니다.
DB 장애 시나리오
다음으로, DB 장애 상황을 가정해 테스트를 진행했습니다.

- dropped iterations : 15/s
- iteration_duration
- 평균: 약 18ms
- p90: 약 30ms
- p95: 약 32ms
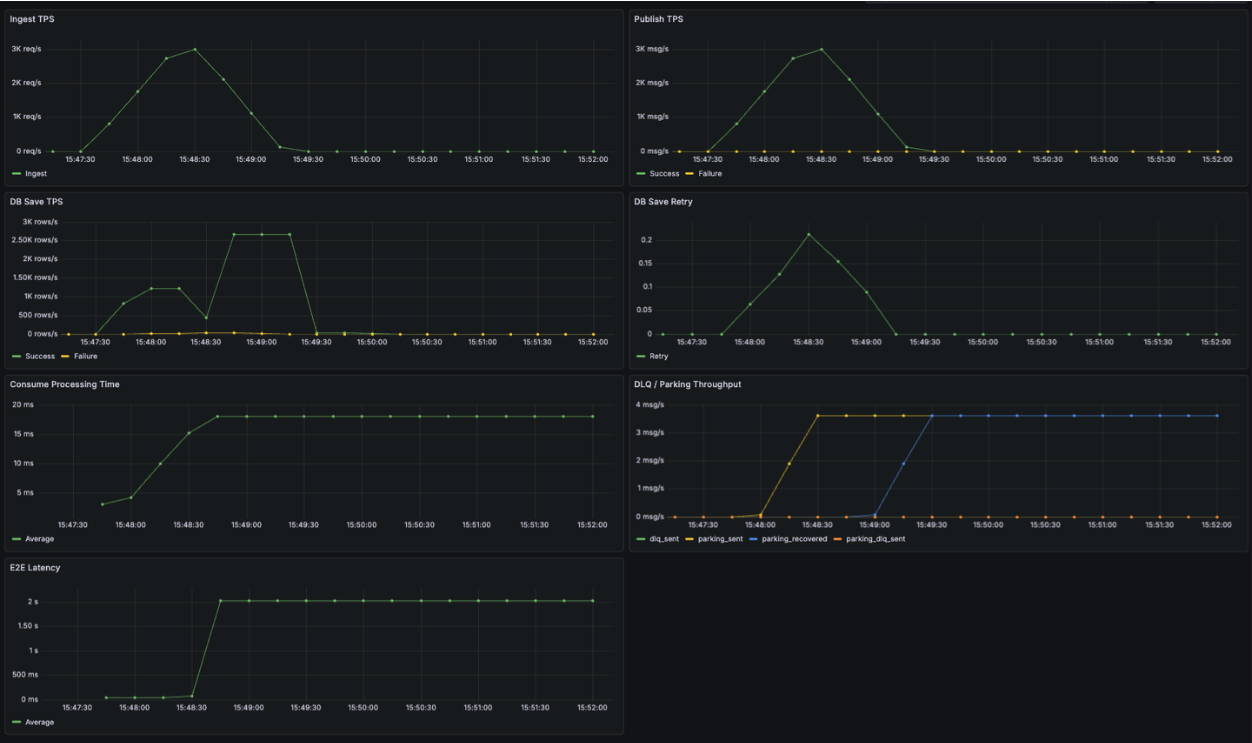
DB를 강제로 중단한 상태에서 동일한 부하를 유지했을 때,
- DB 저장 단계에서는 HikariCP 타임아웃(3초) 이후 빠르게 실패했고
- 해당 오류는 재시도 가능한 인프라 에러로 분류되어
- 로그는 Parking Lot 토픽으로 전송되었습니다.
이 과정에서도 중요한 점은, DB 장애가 발생했음에도 요청 수신(Ingest TPS)은 안정적으로 유지되었다는 것입니다.
즉, 로그 저장 실패가 요청 처리 실패로 전파되지 않았습니다.
DB 복구 이후에는 Parking Lot Consumer가 지수 백오프 전략에 따라 대기 중이던 로그를 순차적으로 재처리했고, 최종적으로 모든 로그가 DB에 정상 저장되는 것을 확인했습니다. 이번 테스트에서는 Parking DLQ로 이동한 로그 없이 전체 데이터가 복구되었습니다.
마무리하며
4주차는 설계와 구현이 실제 부하와 장애 상황에서도 의미가 있는지를 검증하는 시간으로, 기존 POC와 동일한 조건으로 테스트를 진행하며, 구조 변화가 처리 흐름과 지표에 어떤 영향을 주는지 확인할 수 있었습니다.
특히 목표 TPS 유지 여부를 나타내는 지표를 통해, 로그 처리 경로를 비동기화한 효과를 수치로 설명할 수 있었습니다.
이렇게 Learner’s High에 참가하면서 한 달이라는 제한된 시간 안에서 문제를 정의하고, 구조를 설계하고, 마지막에는 테스트와 지표로 이를 검증해보았습니다.
운영 환경에서 겪었던 디버깅의 불편함을 구조적으로 개선해보는 시도를 출발점으로, 헥사고날 아키텍처와 CQRS를 적용해 코드의 책임을 정리하고 장애 상황을 전제로 한 설계와 복구 프로세스를 직접 고민해보며 한 단계 성장할 수 있었던 의미 있는 시간이었습니다.
'Leaner's High' 카테고리의 다른 글
| [Learner's High] 3주차 - 운영 대비 고도화 (0) | 2026.01.07 |
|---|---|
| [Learner's High] 2주차 - 조회 고도화 (0) | 2025.12.31 |
| [Learner's High] 1주차 - 문제 정의 (1) | 2025.12.24 |
| [Learner's High] 토스 러너스하이 시작 (0) | 2025.12.17 |